Introduzione agli alberi di decisione
Setting del problema

Spazio delle ipotesi
Definizione spazio ipotesi
Per spazio delle ipotesi andiamo a considerare l’insieme delle funzioni rappresentabili dal nostro modello. Questo implica che l’allenamento ricerca l’ipotesi ossia la parametrizzazione ottimale del nostro modello, ottimale in quanto minimizza l’errore che viene compiuto nel training set.
L’insieme iniziale si può anche considerare come inductive bias ossia il restringimento solamente a certe ipotesi e non tutte. Altrimenti abbiamo no free lunch.
Espressività
In pratica ci andiamo a chiedere
- Per quali $h$ esistono modelli di alberi di decisione? Per tutti
- Dato un albero per una ipotesi $h$, l’albero è unico?
- Se non è unico abbiamo una preferenza?
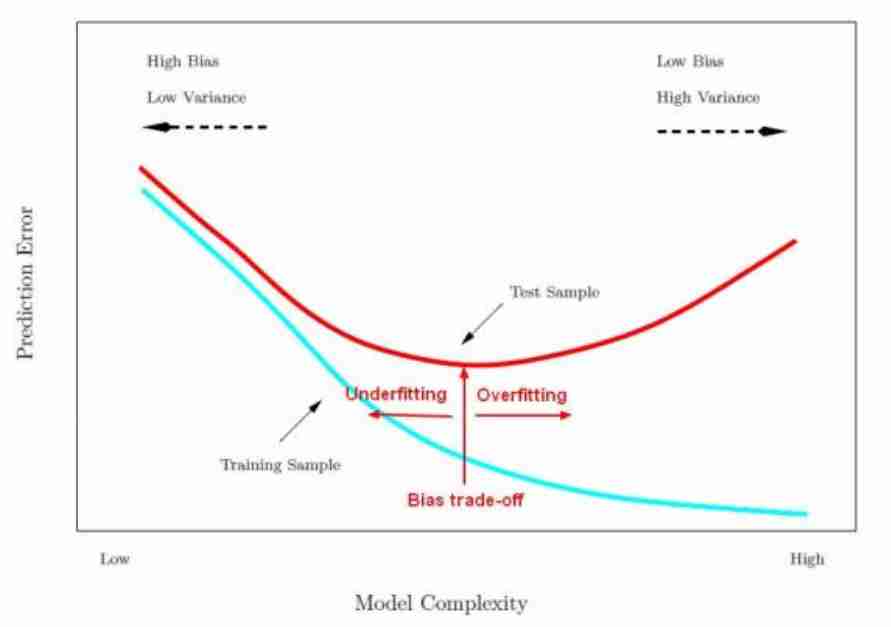
Overfitting and underfitting
Sono dei fenomeni molto comuni nel campo dell’apprendimento statistico. Si potrebbe dire in modo intuitivo che:
-
Underfitting quando il modello non è ancora stato allenato, quindi possiede un bias molto alto per quanto riguarda la precisione del modello
-
Overfitting quando il modello è stato allenato troppo, tanto che ha imparato del rumore presente sul training set, questo non permette la generalizzazione sul test set.
Ossia ho un errore basso nel training set, ma non riesco a generalizzare sul validation set.
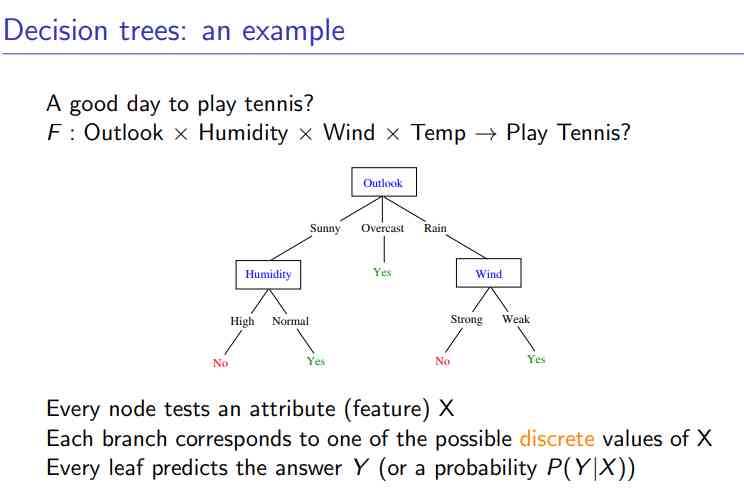
 ### Esempio di struttura albero decisionale
### Esempio di struttura albero decisionale
Vorremmo cercare di modellare alcuni modelli di regressione o classificazione seguendo un albero di decisione come in figura
 Il problema sarebbe capire come creare l’albero in automatico, a seconda di un training set labellato:
Input:
Il problema sarebbe capire come creare l’albero in automatico, a seconda di un training set labellato:
Input:
- $
- Un ipotesi $h$ che è un albero di decisione.
Entropia
Definizione entropia
$$ H(X) = - \sum_{i=1}^{n}P(X = i) \log_{2}P(X=i) $$In cui se sono uguali hanno entropia massima, segue il grafico di questo genere

C’è un apparato teorico non da poco per questo, perché è stato utilizzato molto nella teoria della comunicazione. Una cosa che riguarda la probabilità del singolo dato, se è sempre uguale ho entropia più alta.
Information Gain
Una definizione che segue l’intuizione è che la probabilità dell’avvenimento influenzi il concetto di informazione, ossia se un evento compare sempre (tipo il sole che sorge), non ha molto informazione, perché è sempre uguale.
- Probabilità 1 ha zero informazione
- given two independent events with probabilities p1 and p2 their joint probability is p1p2 but the information acquired is the sum of the informations of the two independent events, so $I(p_{1}p_{2}) = I(p_{1}) + I(p_{2})$ Le due propreità di sopra giustificano il fatto di definire in modo abbastanza naturale che $$ I(p) = -\log(p) $$
Proprietà importanti (4)
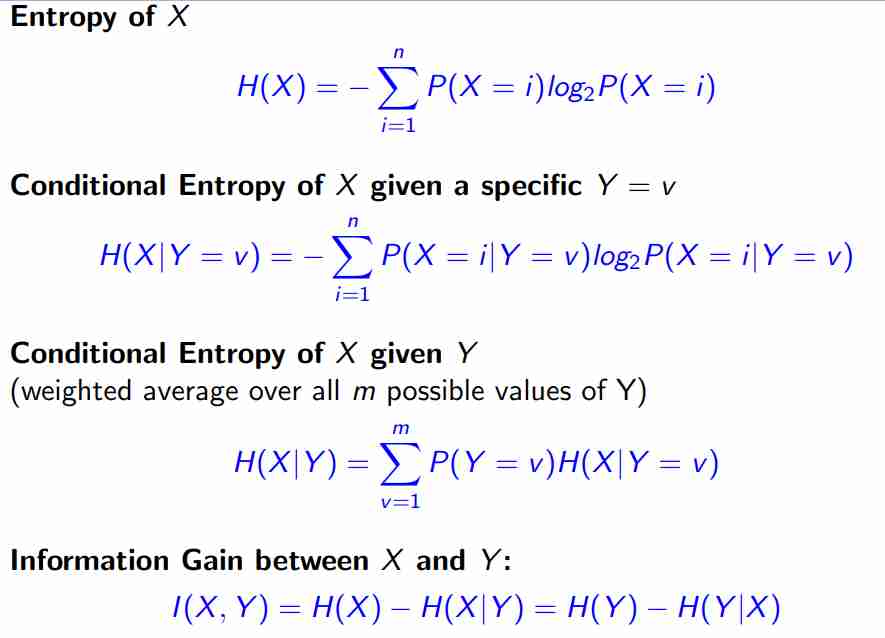
Algoritmo di costruzione dell’albero
Descrizione algoritmo di costruzione
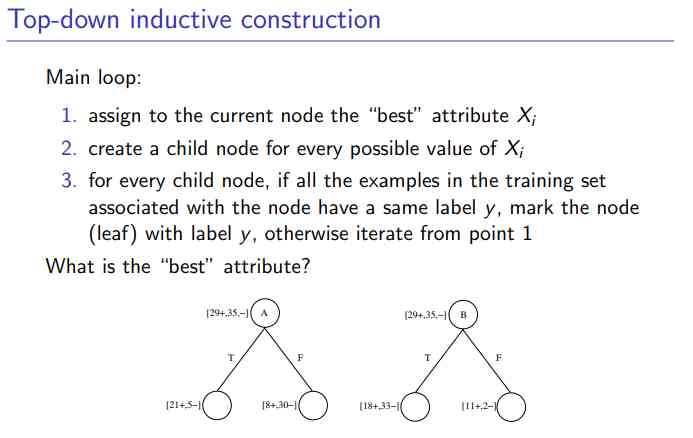
Bisogna introdurre il concetto di entropia per poter discriminare, vorremmo cercare il punto che diminuisca di più l’entropia.
Riduzione overfitting
Pruning dell’albero (2)
- Posso fare early stopping, ossia smetto di alllenarmi (ossia di creare altre branch), dopo che ne ho create un tot.
- Posso fare post-pruning, ossia dopo che ho creato tutto l’albero (probabilmente facendo overfitting), mi metto ad eliminare alcune branches di poco conto.
- Questo si utilizza il validation set per vedere in che modo potare può influenzare la performance su questo (se migliora allora di fa, lo facciamo in modo greedy)
Index di Impurità di Gini
Questo è un indice che è stato usato in economia per studiare la disuguaglianza fra le persone, nel nostro caso lo utilizziamo per capire in che modo fare branching con l’albero di decisione
$$ I_{G}(F) = \sum_{i=1}^{m} f_{i}(1 - f_{i}) = \sum_{i=1}^{m} (f_{i} - f_{i}^{2}) = 1 - \sum_{i= 1}^{m}f_{i}^{2} $$Gini’s impurity measures the probability that a generic element get misclassified according to the current classification (an alternative to entropy).
Dove $f_{i}$ è la frazione del dataset che appartiene ad $i$ Questo è quindi un modo alternativo per fare split ad un nodo dell’albero.
Random forests
Vengono costruiti molti alberi e si utilizzano le loro decisioni assieme per avere un risultato finale, questo è una tecnica ensemble perché vengono messe assieme conoscenze di tutti gli alberi.
Ensemble models
Ensemble techniques exploits the principle that a large number of relatively uncorrelated models (e.g. trees) operating as a committee will typically outperform any of the individual constituent models.
Metodi di differenziazione (2)
Chiaramente non abbiamo molto vantaggio se tutti gli alberi che vengono così creati sono tutti uguali fra di loro, è quindi utile utilizzare tecniche che li differenzino fra di loro:
- Bagging uso input random.
- Feature randomness (uso subset di features per predire)
Conclusioni
Aspetti positivi degli alberi di decisione (4)
- Molto veloci
- Non hanno bisogno di grandi quantità di dati
- Facile capire perché viene fatto la decisione (posso plottare le immagini)
- Adatti sia a problemi continui che discreti
Aspetti negativi (3)
- Molto facile andare in overfitting
- Esistono molti alberi per lo stesso dataset (instabile con le features e struttura dell’albero)
- Possono diventare molto unbalanced se c’è qualche predittore forte (andare a guardare questo).