Introduzione
L’importanza del topic
Gli algoritmi di ordinamento sono molto di base per la comprensione dell’ampio raggio degli algoritmi. Utilizzano l’analisi, introducono tecniche di risoluzione dei problemi computazionali come greedy, divide et impera e simile. Permettono un primo uso di astrazioni e l’analisi di sottoproblemi.
Il problema
Il problema è trovare una permutazione di un insieme di numeri iniziali tale per cui tale insieme di numeri si ordinato:
Questo si può fare con qualunque collezione confrontabile fra di loro.
-
Slide

Loco: non vengono utilizzati array di appoggio, per esempio un quicksort sarà di in loco, mentre mergesort no.
Stabile: se due elementi hanno la stessa chiave, questi compaiono con lo stesso ordine nell’array ordinato, per esempio radix sort è stabile, merge sort è stabile.
Algoritmi incrementali
Si possono dire incrementali algoritmi che si dimostrano in “maniera greedy”, ossia creano un sottoaray ordinato k, e al prossimo passo provano a creare un array k + 1.
Selection sort
Si trova l’elemento più piccolo all’interno di $(k+1,n)$ e lo si swappa con quello in posizione k + 1, si continua così fino a quando l’array non sia ordinato. NO stabile (spara dall’altra parte l’elemento con cui swappa).
Una proprietà che possiede selection ma non insertion è che:
$\forall e \in (1,k), \forall b \in (k + 1, n), e Codice java Analisi del costo Si inserisce l’elemento k + 1 nella posizione corretta in $(1, k)$. è stabile Codice java Analisi del costo Nel caso ottimo è lineare l’algoritmo. Si fa “galleggiare” l’elemento massimo fino alla fine, creando un array ordinato per $(k + 1, n)$, inoltre si ha che ogni elemento in $(1, k)$ è minore del primo insieme. Codice java Analisi del costo A differenza del selection sort, nel caso migliore bubble sort è lineare, mentre selection resta quadratico. Analisi nel caso medio Per portare un elemento v all’indice i fino all’indice j ho bisogno di $|i - j|$ numero di swap. Vorrei sapere in media quanti nei ho bisogno. Metto un limite inferiore al caso medio. Lo faccio partendo al punto medio, posso dire che assumento probabilità uguale, dovrei fare in media n/4 swap per questo. Tutte le altre celle devono farne di più, quindi al minimo devo avere $n^2 / 4$ operazioni al caso medio, quindi al minimo deve essere $\Omega(n^2)$ ma al massimo, nel caso peggiore ho $O(n^2)$. Quindi Quindi il tempo avarage è compreso fra stesse cose, quindi è la stessa. Caso medio in slide Una caratteristica importante del bubble sort è che contiene informazioni sulle inversioni, che è legato al grado di disordine dell’array. (caso pessimo per esempio 2,3,4,5,6,7,8,9,1) Storia e dell’algoritmo Inventato da Hoare nel 1962, cerca di creare ordinare l’array secondo il metodo di divide et impera che si divide in 3 passi. Introduzione all’algoritmo Si prende un valore della sequenza da ordinare, che chiamiamo pivot. Vogliamo creare così 2 array (in loco) tali che una sia sempre più piccola di questo valore, l’altra sempre più grande, mettiamo il pivot in mezzo e andiamo a ordinare questo array. Codice Java L’analisi dell’algoritmo è abbastanza complesso rispetto agli altri algoritmi trovati Analisi in slide generale Il caso peggiore si verifica nel caso in cui prendo sempre il massimo o il minimo (quindi nel caso in cui l’array è già ordinato per esempio) Analisi del caso medio Essendo il caso medio nlogn, questo algoritmo ha dei benefini nel caso in cui si randomizzi l’analisi del caso medio rende questo algoritmo abbastanza succoso per quanto riguarda l’utilizzo pratico contro altri algoritmi come Merge o Heapsort Vogliamo utilizzare sempre il caso medio, sarebbe la cosa migliore, perché in questo modo è molto più probabile utilizzare l’elemento medio. Quindi nel momento di selezione del pivot scelgo un valore casuale. Si può fare questa analisi probabilistica per avere theta di nlogn Uno degli algoritmi più vecchi che ci siano, Ideato da Von Neumann nel 1945, è uno degli esempi migliori per il divide et impera. Codice Java Analisi del costo Lineare nello spazio. Questo algoritmo per il sorting non utilizza il divide et impera, ma una struttura di dati utile, per questo motivo lo mettiamo in una sezione apparte, che abbia inserimento e rimozione in log n. L’albero binario pone vincoli molto più forti perché l’intero sottoalbero destro e sinistro del nodo devono soddisfare certe proprietà Usiamo alberi completi, ovvero ogni noto ha grado 2 tranne le foglie. Possiamo anche avere un albero “quasi” completo, compattato a sinistra, ovvero le foglie possono avere buchi solamente a sinistra Questo sarà l’albero binario utilizzato dalla heap. si cicla da n/2 + 1 fino al 1 (root) per ogni elemento chiamo fixheap(i) crea la heap in tempo lineare, a differenza dell’insertion in n volte Codice java Si prende i lminimo fra index, left(index) e right(index), se questo minimo è diverso da index, si swappa e si continua ricorsivamente finché o non cambia o sono una foglia. Codice java DeleteMax () Codice Java mio Upper fix(index) È praticamente fixHeap, però va verso l’alto Insert(i) Metto l’elemento in fondo, aggiungo 1 alla size della heap e chiamo upper fix su questo elemento. Finalmente avendo (almeno 3) le funzioni precedenti, possiamo andare a costruire una funzione di sorting in loco, l’heapsort Codice Java Quindi heapify O(n), mentre delete max n volte ho un n log n, quindi la complessità è di O(nlgn). Possiamo dimostrare un limite inferiore per l’ordinamento di algoritmi che utilizzino il confronto. Io sto guardando tutti i possibili rami (che rappresentano una sequenza di operazioni). L’output è una permutazione degli elementi tale per cui si possa considerare che il risultato sia ordinato. La struttura dell’albero si può dire che descriva un algoritmo di ordinamento generale per certo numero di elementi. Un cammino dalla radice a una foglia rappresenta un particolare input per una singola esecuzione Esempio in slide con 3 Possiamo quindi dire che esiste un isomorfismo fra algoritmo di confronto e l’albero di ordinamento. Allora se esiste questa corrispondenza fra qualunque albero di ordinamento e l’algoritmo, il caso pessimo sarà l’altezza dell’albero! Perché uno step è andare giù di un livello. (un algoritmo può fare più confronti di questo, ma al minimo ho l’altezza dell’albero) Lemma 1 numero di foglie Il numero di foglie dell’albero di decisione è uguale a $n!$ con n il numero di input. Questo è vero perché l’algoritmo deve essere in grado di ordinare ogni tipo di input, se supponiamo che una permutazione non è raggiungibile nella foglia, allora l’algoritmo non è corretto, non può ordinare per certi input. Lemma 2 altezza con foglie Se ho k foglie, l’altezza di un albero binario deve essere al più $\lceil \log_2 n \rceil$ Dimostrazione per induzione strutturale Passo base supponiamo che l’albero abbia una foglia, allora l’altezza è 0. corretto. Passo induttivo Supponiamo che un albero abbia due sottoalberi per cui valga ciò. allora l’altezza dell’albero risultante è 1 + $max(\log_2 h_1, \log_2 h_2)$ (i ceil sono tralasciati per pigrizia, ma ci dovrebbero essere. Supponiamo, senza perdita di generalità che $h_1 \geq h_2$, allora avrò che $1 + \log_2 h_1 = \log_2 2h_1 \geq \log_2(h_1 + h_2) = altezza corrente$ Passo finale, calcolo dell’altezza allora utilizzando le dimostrazioni precedenti possiamo dire che al più l’albero di ordinamento ha altezza $\log_2 (n!) = \sum \log_2(i)$ con somma da 1 a n. allora facendo un ragionamento sull’integrale e somme di riemann (guardare l’approssimazione coi rettangoli, ottengo che C’è un altro modo che utilizza l’approssimazione di Stirling: $n! \approx \sqrt{2\pi n} (\dfrac{n}{e})^n$ Vogliamo contare il numero di elementi in un range ben specificato L’ordinamento stabile non è ben specificato qui. Codice java Analisi del costo Sto facendo 1 ciclo su k. 1 ciclo su n 1 ciclo su k con al massimo n iterazioni. n + k Quindi è in theta (n + k). Una cosa brutta di questo è che vale solo per INTERI. Bucket ha il vantaggio di essere eseguibile per ogni tipologia quindi anche i records! Praticamente è uguale a counting sort, ma si utilzza array di liste! Pseudocodice Il problema dei precedenti è che c’è bisogno di molta memoria per rappresentare la nostra chiave, per questo motivo radix sort interviene per cercare di risolvere questa situazione sfavorevole per i precedenti.
Con radix abbiamo una memoria lineare sull’array di entrata. L’algoritmo è utilizzare un ordinamento stabile per fare l’ordinamento che ci serve. È stato inventato da Herman Hollerith per le macchine tabulatrici.
public static void selectionSort(Comparable A[]) {
for (int k = 0; k < A.length - 1; k++) {
// cerca il minimo A[m] in A[k..n-1]
int m = k;
for (int j = k + 1; j < A.length; j++)
if (A[j].compareTo(A[m]) < 0) m = j;
// scambia A[k] con A[m]
if (m != k) {
Comparable temp = A[m];
A[m] = A[k];
A[k] = temp;
}
}
}

Insertion sort
public static void insertionSort(Comparable A[]) {
for (int k = 1; k <= A.length - 1; k++) {
int j;
Comparable x = A[k];
// cerca la posizione j in cui inserire A[k]
for (j = 0; j < k; j++) {
if (A[j].compareTo(x) > 0) break;
}
if (j < k) {
// Sposta A[j..k-1] in A[j+1..k]
for (int t = k; t > j; t--)
A[t] = A[t – 1];
// Inserisci A[k] in posizione j
A[j] = x;
}
}
}

Bubble sort
public static void bubbleSort(Comparable A[]) {
for (int i = 1; i < A.length; i++) {
boolean scambiAvvenuti = false;
for (int j = 1; j <= A.length - i; j++) {
// Se A[j-1] > A[j], scambiali
if (A[j - 1].compareTo(A[j]) > 0) {
Comparable temp = A[j - 1];
A[j - 1] = A[j];
A[j] = temp;
scambiAvvenuti = true;
}
}
if (!scambiAvvenuti) break;
}
}


Algoritmi Divide et Impera
Quicksort
public static void quickSortRec(Comparable A[], int i, int f) {
if (i >= f) return;
int m = partition(A, i, f);
quickSortRec(A, i, m - 1);
quickSortRec(A, m+1, f);
}
private static int partition(Comparable A[], int i, int f) {
int inf = i, sup = f + 1;
Comparable temp, x = A[i];
while (true) {
do {
inf++;
} while (inf <= f && A[inf].compareTo(x) <= 0);
do {
sup--;
} while (A[sup].compareTo(x) > 0);
if (inf < sup) {
temp = A[inf];
A[inf] = A[sup];
A[sup] = temp;
} else break;
}
temp = A[i];
A[i] = A[sup];
A[sup] = temp;
return sup;
}
Analisi dell’algoritmo


Analisi randomizzata
MergeSort
public static void mergeSort(Comparable A[]) {
mergeSortRec(A, 0, A.length - 1);
}
private static void mergeSortRec(Comparable A[], int i, int f) {
if (i >= f) return;
int m = (i + f) / 2;
mergeSortRec(A, i, m);
mergeSortRec(A, m + 1, f);
merge(A, i, m, f);
}
private static void merge(Comparable A[], int i1, int f1, int f2)
{
Comparable[] X = new Comparable[f2 - i1 + 1];
int i = 0, i2 = f1 + 1, k = i1;
while (i1 <= f1 && i2 <= f2) {
if (A[i1].compareTo(A[i2]) < 0)
X[i++] = A[i1++];
else
X[i++] = A[i2++];
}
if (i1 <= f1)
for (int j = i1; j <= f1; j++, i++) X[i] = A[j];
else
for (int j = i2; j <= f2; j++, i++) X[i] = A[j];
for (int t = 0; k <= f2; k++, t++) A[k] = X[t];
}

Heap
Albero Heap
Funzioni per la heap (5)
Heapify
private static void heapify(Comparable S[], int n, int i) {
if (i > n) return;
heapify(S, n, 2 * i); // crea heap radicato in S[2*i]
heapify(S, n, 2 * i + 1); // crea heap radicato in S[2*i+1]
fixHeap(S, n, i);
}
// per trasformare un array S in uno heap:
// heapify(S, S.length, 1 );
fixheap (index)
private static void fixHeap(Comparable S[], int c, int i) {
// c è la size attuale della heap
int max = 2 * i; // figlio sinistro
if (2 * i > c) return;
if (2 * i + 1 <= c && S[2 * i].compareTo(S[2 * i + 1]) < 0)
max = 2 * i + 1; // figlio destro
if (S[i].compareTo(S[max]) < 0) {
Comparable temp = S[max];
S[max] = S[i];
S[i] = temp;
fixHeap(S, c, max);
}
}
private static void deleteMax(Comparable S[], int c) {
Comparable tmp = S[c];
S[c] = S[1];
S[1] = tmp;
fixHeap(S, c - 1, 1);
}
Heapsort
public static void heapSort(Comparable S[]) {
heapify(S, S.length - 1, 1);
for (int c = (S.length - 1); c > 0; c--) {
Comparable k = findMax(S);
deleteMax(S, c);
S[c] = k;
}
}
Limite inferiore
Corrispondenza cammino-algoritmo
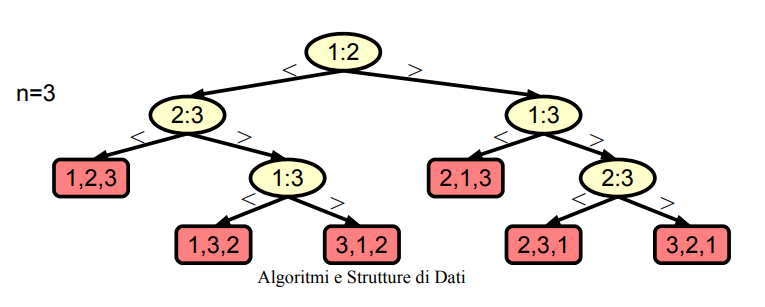
Altezza dell’albero di decisione di ordinamento
Ordinamento lineare
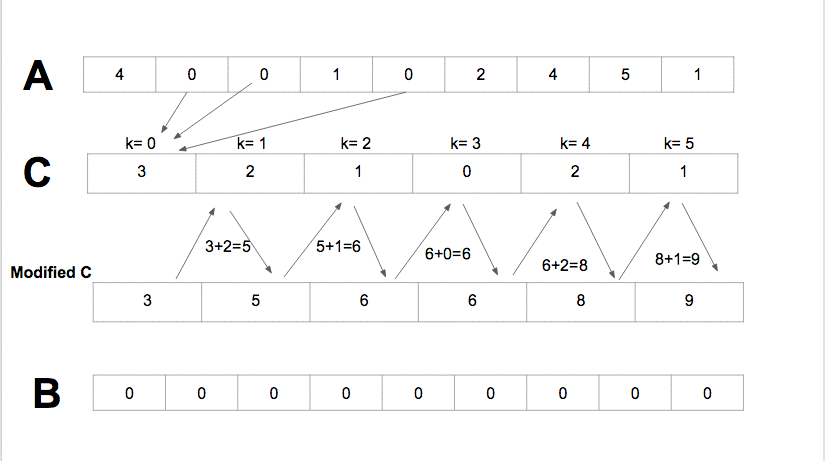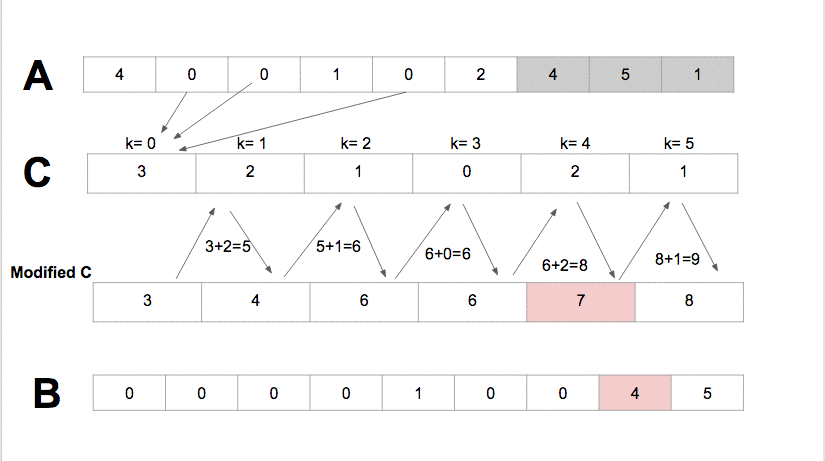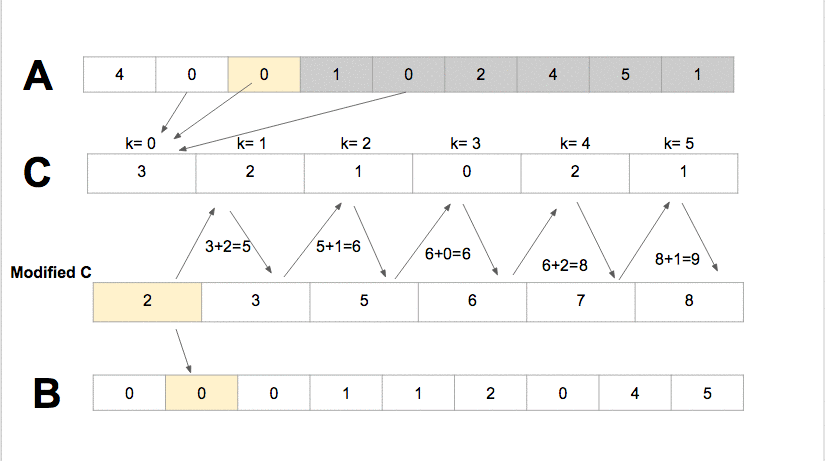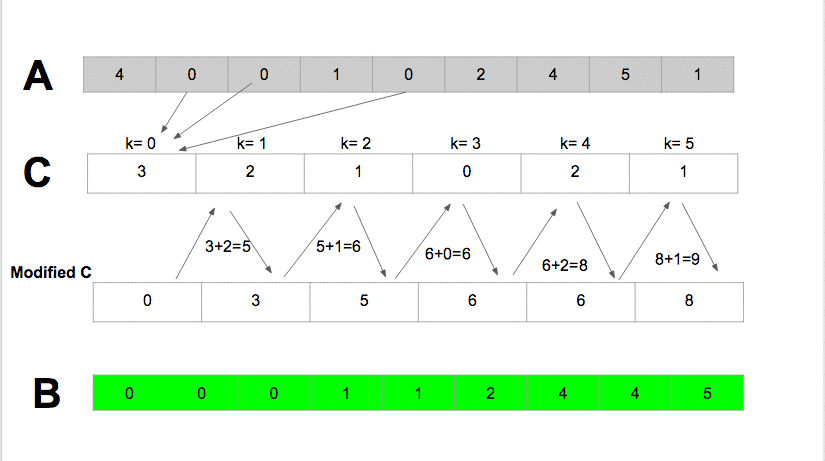
Counting sort
public static void countingSort(int[] A, int k) {
int[] Y = new int[k];
int j = 0;
for (int i = 0; i < k; i++) Y[i] = 0;
for (int i = 0; i < A.length; i++) Y[A[i]]++;
for (int i = 0; i < k; i++) {
while (Y[i] > 0) {
A[j] = i;
j++;
Y[i]--;
}
}
}
Bucket Sort
Algoritmo bucketSort(array X[1..n], intero k)
Sia Y un array di dimensione k
for i := 1 to k do
Y[i]:=lista vuota
endfor
for i := 1 to n do
Appendi X[i] alla lista Y[chiave(X[i])];
endfor
for i := 1 to k do
copia ordinatamente in X gli elementi di Y[i]
endfor
Radix Sort
{kind=link}