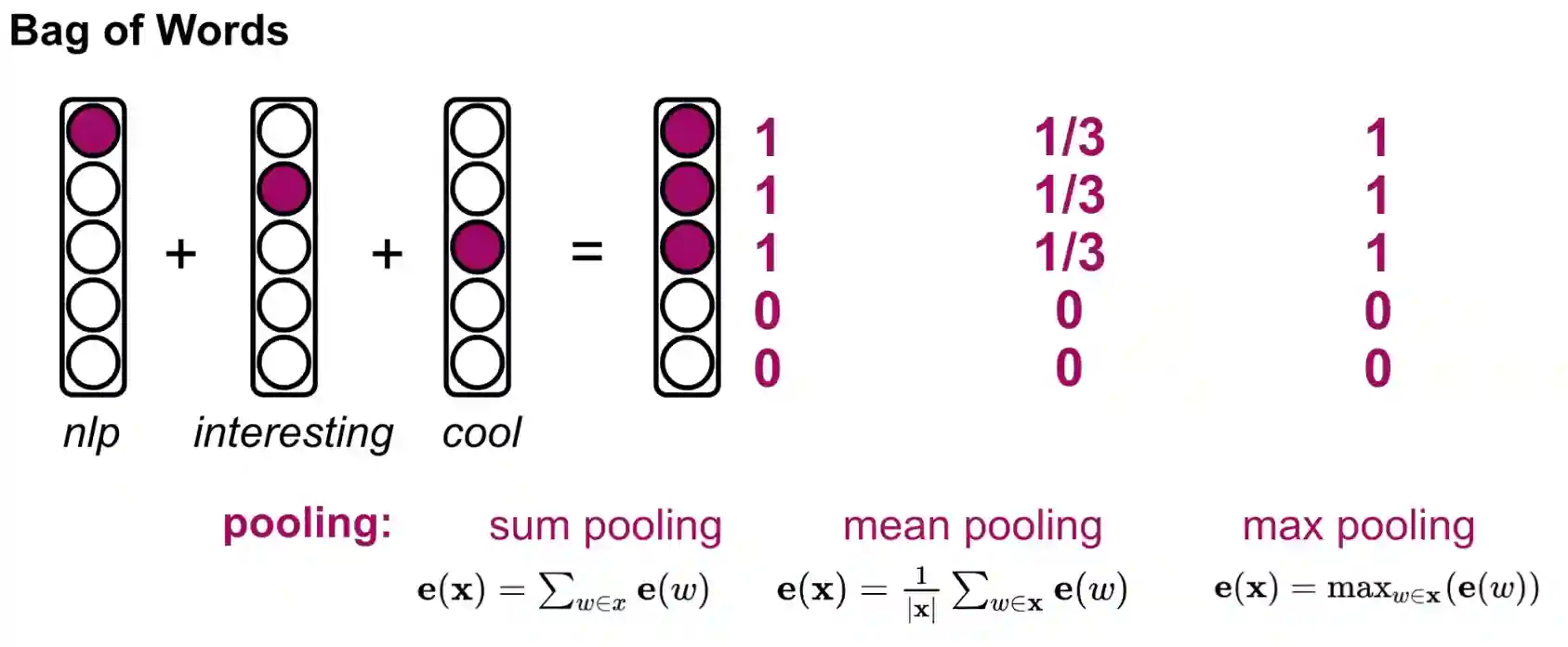
Bag of words only takes into account the count of the words inside a document, ignoring all the syntax and boundaries. This method is very common for email classifications techniques. We can say bag of words can be some sort of pooling, it’s similar to the computer vision analogue. It’s difficult to say what is the best method (also a reason why people say NLP is difficult to teach).
Introduction to bag of words
Faremo una introduzione di applicazione di Naïve Bayes applicato alla classificazione di documenti.
Setting del problema
$$ \theta_{i, \text{word}, l} = P(X_{i} = \text{word} | Y = l) $$Ossia quanto è probabile che una parola sia word, che appaia alla posizione i, data la categoria $l$ del documento Assumendo che non dipenda dalla posizione posso solamente contare le parole per documento fregandomene della posizione, questa è l’idea che ha portato ai primi approcci in questo campo.
Assumiamo che siano anche indipendenti alla posizione per semplicità, che è una assunzione molto forte perché proviamo a catalogare la classe solamente dalla frequenza delle parole
$$ \theta_{i, \text{word}, l} = \theta_{\text{word}, l} $$Note: assunzioni forti (2)
Perché è una assunzione molto forte, e irrealistica il fatto che siano:
- Indipendenti dalla posizione
- indipendenti fra di loro (è molto chiaro che certe parole vanno più insieme rispetto ad altri, quindi è una assunzione chiaramente false). Però è didattica la cosa che un modello semplice come Naïve Bayes possa essere utilizzato per un problema del genere.
Forward inference
Una volta creato tutta la matrice di pesi e possibilità (quanto è correlato), Per fare una forward inference non faccio altro che fare una dot product perché usiamo quella come metrica per fare inference.
Inference in breve

Calcolando la $s_{k}$ come in immagine sopra, posso avere una sorta di caratterizzazione del tema/categoria, in ogni singolo documento che ho.
Poi per fare inferenza vedo il documento attuale è più simile rispetto a quale.
Cosine similarity
Questa è una metrica molto utilizzata per dare una idea di somiglianza di vettori.
