Introduzione sull'encoding
Ossia trattiamo metodi per codificare caratteri dei linguaggi umani, come ASCII, UCS e UTF.
Digitalizzare significa encodarlo in un sistema che possa essere memorizzato su un dispositivo di memorizzazione elettronico. Ovviamente non possiamo mantenere l'informazione così come è, ma vogliamo memorizzarne una forma equivalente, ma più facile da manipolare dal punto di vista del computer. Creiamo quindi un mapping, o anche isomorfismo tra il valore di mappatura (o encoding), solitamente un valore numerico, tra il singolo valore atomico originale e il numero.
Esempi di cose atomiche per encoding sono:
- Carattere per le parole
- Pixel per le immagini
- Sequenza sinusoidale per FFT per il suono o la musica.
Vogliamo creare un mapping non ambiguo, quindi uno standard è necessario!.
Sulle differenze linguistiche
(non fare) Ma come fare a creare uno standard che possa essere adatto sia a caratteri arabi, inglesi, cirillici, cinesi coreani o giapponesi?
-
Sulle caratteristiche linguistiche diverse

La scrittura non è in grado di rappresentare il suono della lingua in modo univoco per tutti i linguaggi (esempi accenti in certe lingue, come l'italiano, oppure il fatto che l’inglese molte pronuncie sono diverse rispetto a quanto si scrive), Danese cambia proprio suono. In ebraico contano solamente le consonenti, le vocali sono solamente un ausilio per la pronuncia.
Arabo ha una forma di corsivo, e la forma del carattere dipende dai caratteri che sono di fianco.
-
Secondo ragionamento sulle caratteristiche delle lingue diverse

Ossia può cambiare proprio la semantica della parola, a seconda della lingua in cui si interpretano gli stessi caratteri. Quasi il linguaggio si potrebbe intendere una funzione di interpretazione semantica , accennato in Logica Proposizionale.
La ricerca dello spazio di rappresentazione (3)
ci interessano in partioclare tre caratteristiche per trovare lo spazio di rappresentazione per i nostri caratteri (che comunque rientrano nei numeri, e sono tutti in ).
-
Slide

- Contiguità (se ho certi numeri che hanno un certo senso all’interno di un)
- Raggruppamento logico (se hanno funzioni simili vorremmo che siano ancora vicini)
- Ordine, vorremmo seguire l’ordine alfabetico per questo encoding. (credo il motivo di questa scelta è affinché sia un pò più naturale!)
Altre caratteristiche che fanno parte dell'encoding (che è una funzione parziale)
- Shift: un codice riservato che cambia mappa da adesso in poi. Lo stesso shift o un secondo carattere di shift, può poi far tornare alla mappa originaria
- Codici liberi: codici non associati a nessun carattere. La loro presenza in un flusso di dati indica probabilmente un errore di trasmissione.
- Codici di controllo: codici associati alla trasmissione e non al messaggio.
Standard passati
Stardard poco utilizzati (non importante)
Baudot
Una codifica vecchissima, che nessuno usa, e io non ho mai sentito (siamo circa nel 1850).
EBCDIC
-
Slide

ISO 656-1991
Questo è presente nelle slides ma completamente saltato
ASCII e ISO Latin 1
Questi codici esistono, ma solitamente non sono compatibili con altre lingue. Per questo motivo affinché il codice sia compatibile con il mondo è molto meglio che sia utilizzato UTF-8 di default. Fare la transizione di questa codifica solitamente è costosa
American Standard Code for Information Interchange
Sono 7bit utilizzate e uno come bit di parità. Questo mette uno standard fra codifiche fra telescriventi e schede perforate che erano molto presenti all'epoca. Ed è solamente alfabeto latino inglese.
Origine Backspace Delete, CR e LF
Nella telescrivente avevo bisogno di backspace, per eliminare un carattere. Nelle schede perforate utilizzavo tutti i buchi presenti per significare che non avevo questo carattere, ecco la delete.
Carriage return, nella telescrivente avevo una testina che andava avanti a scrivere, e bisognava farlo tornare indietro, e per far girare la testina utilizzavo Line-feed.
Estensioni custom
Dopo un po' l’hardware è diventato molto affidabile, quindi utilizziamo il bit in più per memorizzare un codice come ci è più comodo. sono le Codepage di ASCII, e ognuno si fa una propria versione.
-
Greco

-
Cirillico

-
Arabo

Ma nessuno di questo è standard! L'unico forse è ISO Latin 1
Caratteri orientali e testi multilingua
Codifica dei Caratteri Orientali
Ma per il cinese non è possibile mettere tutto in un singolo byte, Quindi utilizzano due byte qui.
Ma anche con due byte non è possibile avere tutti i caratteri nella lingua, per questo motivo metto solamente i caratteri più utilizzati
-
Codifiche cinese giapponesi e coreani

-
Slide alfabeti CJK

IL PROBLEMA DEI TESTI MULTILINGUA
Ma cosa succede se ho un testo multilingua? Come faccio a codificarlo in modo disambiguato?
- Dichiarazioni esterne (no, sarebbe per l’intero documento, dovrei utilizzare un markup per specificarti l’encoding?? Troppo brutto)
- Intestazioni interne (sarebbe molto scomodo dover stabilire ogni volta che encoding sia!) Dovrei forse spezzettartelo in troppi modi.
Per questo motivo bisognerebbe creare un nuovo encoding, ed è questo quello che viene fatto in Unicode.
Unicode e Universal Transformation Format
Unicode e ISO/IEC 10646 (storia)
UN PO DI STORIA Questi due standard sono nati per fare le stesse due cose, senza sapere che facevano la stessa cosa. (UNICODE è sponsorizzato dai produttori di hardware, ISO è internazionale ed è spinto dalle nazioni estere).
Il problema principale che vanno a risolvere è quello di essere standard unico per tutti i linguaggi, per esempio in questo modo posso scrivere testo in lingua mista senza darmi troppi problemi!
Hanno avuto una difficoltà ad universi quando l'uno ha scoperto dell’esistenza dell’altro. Poi sono andati a convergere, ossia sono ancora d’accordo con l’encoding presente.
COSA È ENCODATO Così sono nate UCS-2/4 e UTF-8/16/32 che rappresentando rispettivamente una codifica fissa o variable. Questi sono in grado di rappresentare codici di tutti i codici passati!
-
3 categorie di cose encodate

-
Esempi di codici encodati

Con tanto spazio disponibile possiamo anche encodare i linguaggi di star trek e Lord of the ring, però non potevano includere questi linguaggi in uno standard, comunque è possibile encodarli in uno Private Use Area (6400 di base, che sono quelli inizialmente utilizzate per klingon o Lord of ring) e poi 65k liberi.
-
Slide

Principi di unicode (10)
Sono troppi, a memoria non va bene ricordarseli così.
In pratica tutti i caratteri di Unicode sono distinti per semantica, caratteri (quindi la sharfes es tedesca o versione greca sono codici diversi), se ho una P in alfabeti diversi hanno codifiche diverse. Non ho cose riguardanti la grafica!.
la Composizione dinamica è una cosa molto cool, per esempio è quello che sto utilizzando ora, il fatto che scrivo `e, e mi appare la è accentata.
-
Slides



Universal Coded Character/UNICODE
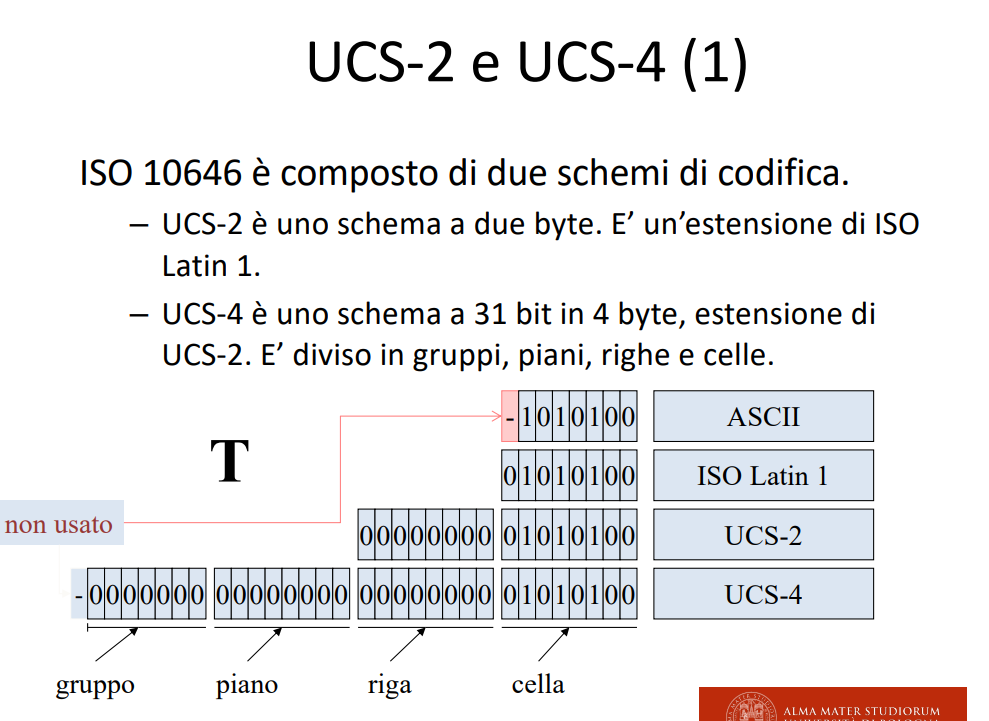
Universal Coded Character same as UCS-2 UCS-4
In UCS-4 il primo bit è utilizzato per identificare la differenza fra UTF-8 e UCS-4.
-
Slide struttura generale
Il piano 14 è in disuso, per tag strani.
Basic Multilingual Plane (BMP) sono tutti i caratteri nel piano 0, sono quelli più comuni per alfabeti west
-
Esempio suddivisione dei piani

Questo è una cosa svantaggiosa per i caratteri latini che andavano già bene con un singolo byte per trasmettere, ecco che entra in gioco il UTF.
Unicode Trasformation Format
Anche conosciuto come UTF-8. È una forma variabile per la rappresentazione precedente, il motivo principale per cui esiste è che per gli americani sarebbe stata una perdita enorme dover aggiungere quell’overhead inutile nella loro trasmissione, loro con 256 restavano già bene.
-
Slide necessità di UTF

Spazi di codifica in UTF
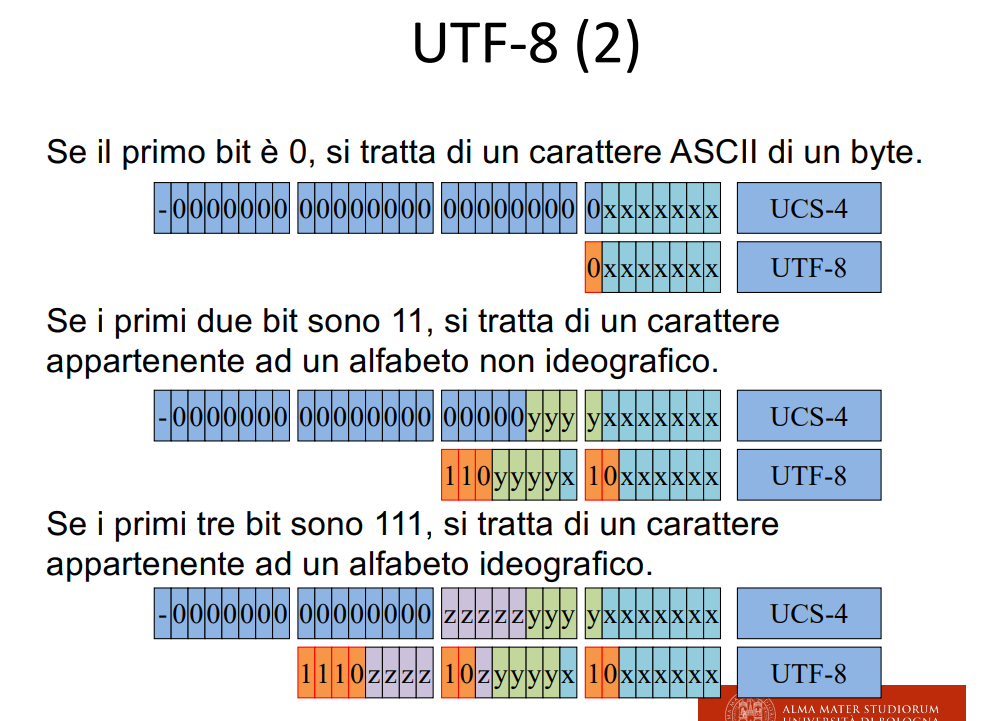
ASCII è compatibilissimo per UTF, in 2 byte ho tutti il resto dei caratteri. in 3 byte stanno tutti i caratteri CJK, in 4 byte stanno tutti i caratteri antichi.
-
Slide numero di byte necessari per la codifica

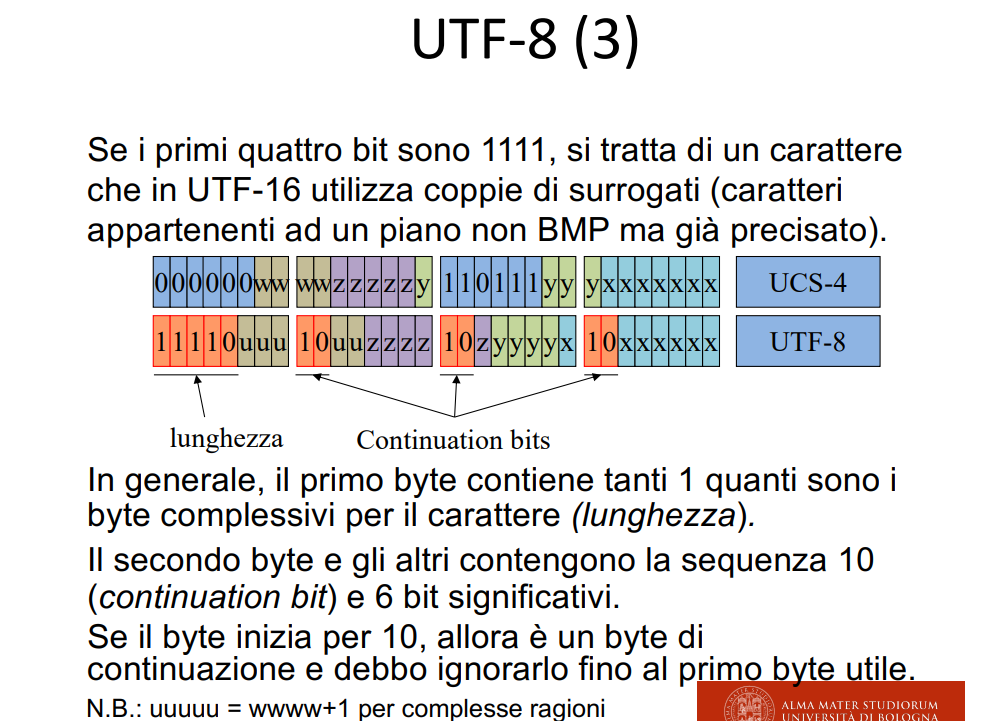
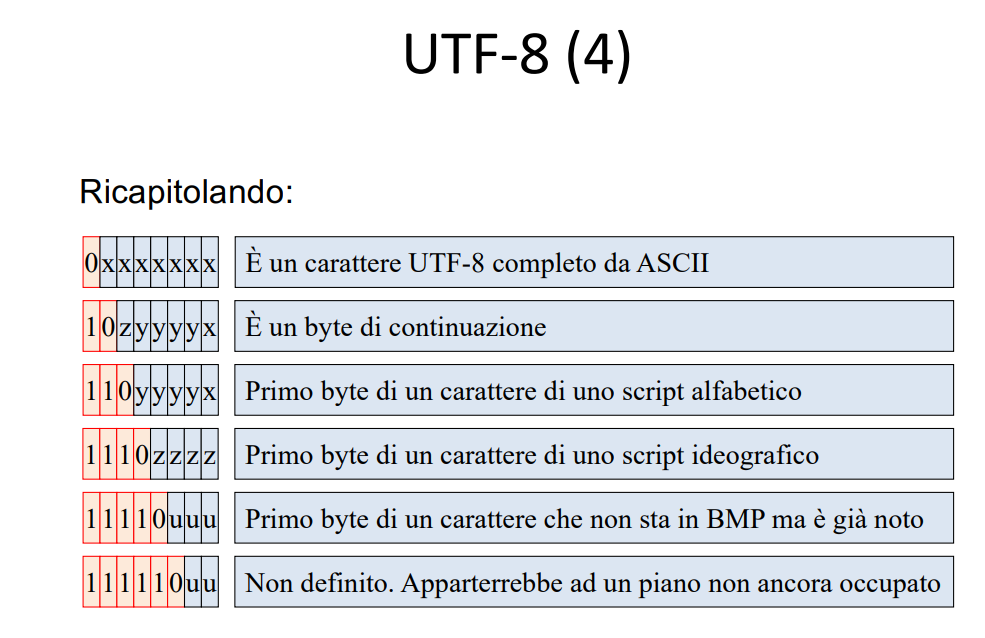
Struttura dei caratteri in UTF
Essendo questa una codifica variabile non ho possibilità di predire il numero di caratteri in un file, perché certi caratteri occuperanno un byte (ASCII normale), mentre altri caratteri occuperanno due byte, come le lettere accentate.
Allora devo utilizzare un codice per capire se sono all’inizio del blocco o sto continuando, o lo devo droppare (quando ricevo 10, ma non ho nessun blocco iniziato!) (sono gli schemi di 10, 0, e 110 etc..)
La cosa importante è che ASCII è subset diretto di UTF, dato che i caratteri latini sono sempre un singolo byte.
-
Confronto UTF e UCS
Alcuni problemi di trasmissione e conversione
Byte order mark
Utilizzato per risolvere il problema di risolvere se interpretare quanto mandato in Little o big endian.
Utilizziamo un carattere speciale in unicode, chiamato Zero-Width No-Break Space (ZWNBSP), Il cui codice è FEFF per capire se il sistema che mi sta mandando qualcosa è in formato little endian oppure big endian, accennato qui (molto importante per l'ordinamento!)
-
Slide

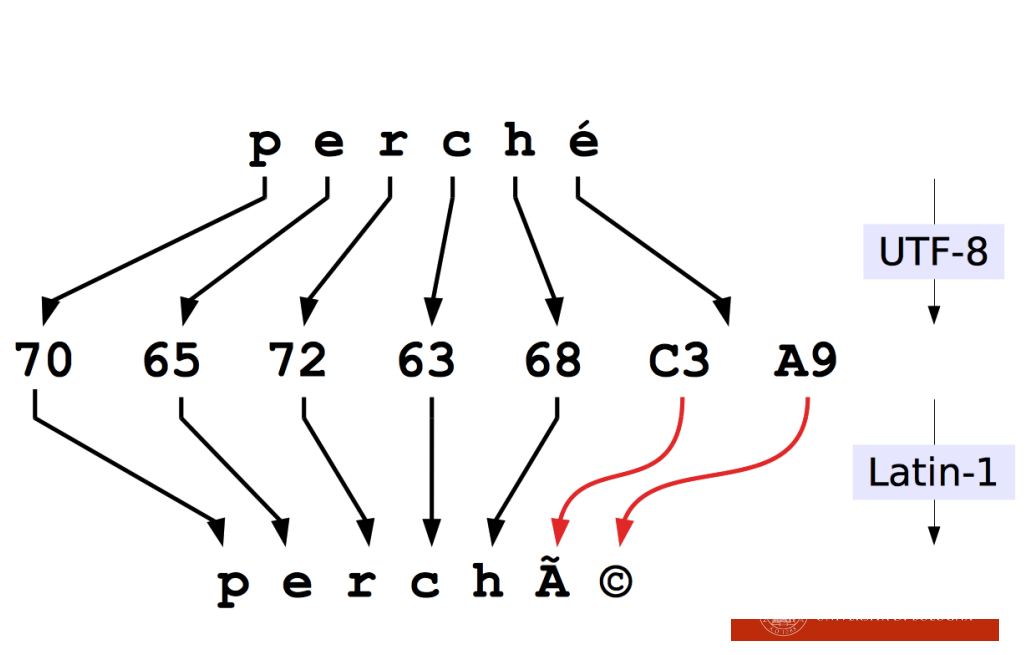
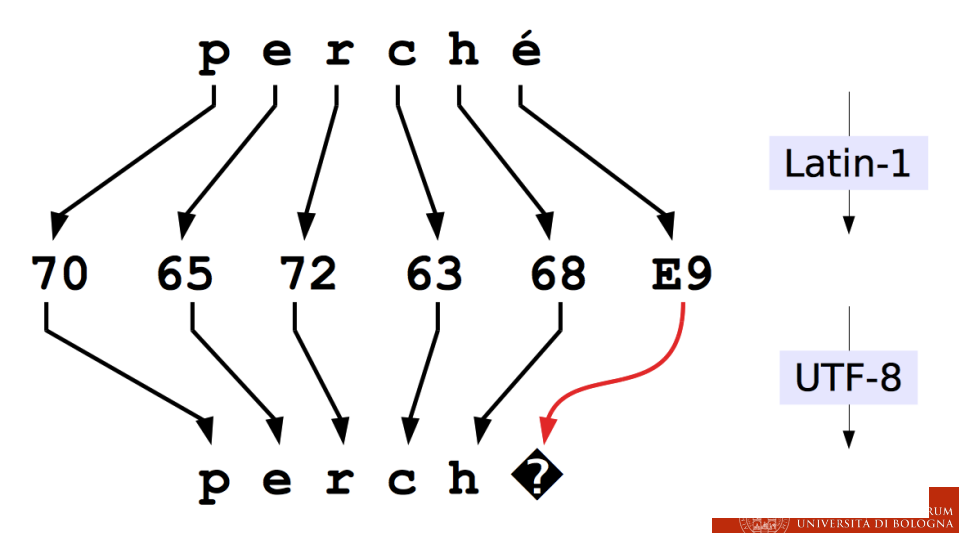
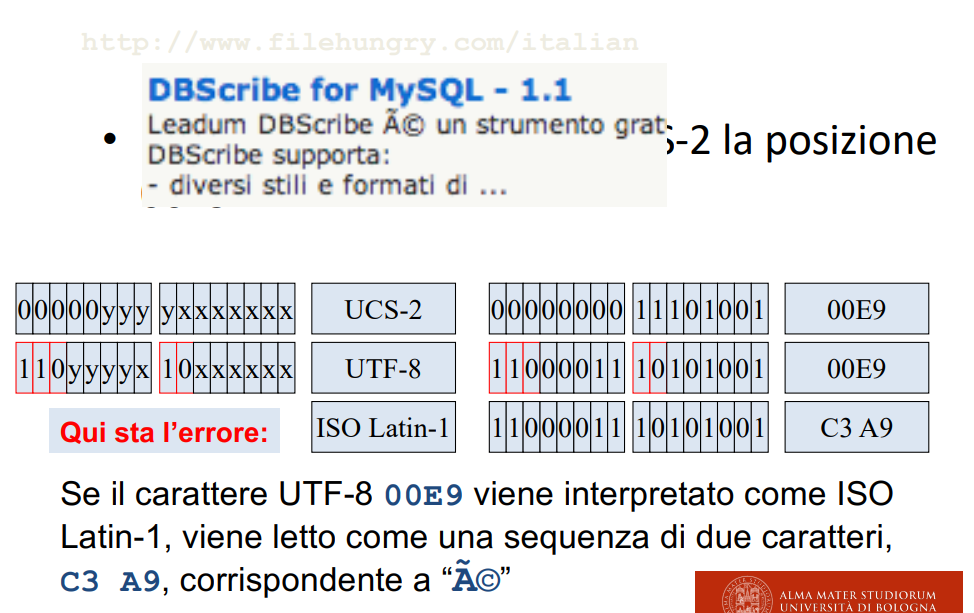
UTF-8 vs Latin-1
Si possono avere problemi di conversione fra questi due standard (perché latin 1 utilizza un singolo byte per le cose accentate, mentre utf-8 ne utilizza due).
-
Slide problemi comuni di conversione
Content encoding
Escaping ed encoding
La necessità di fare encoding o escaping è giustificata principalmente dal fatto che certe applicazioni utilizzano certi caratteri come simboli speciali (e quindi non si potrebbe utilizzarli, un esempio è l’andare accapo credo).
In pratica si utilizzano questi metodi per aggirare quelli
Escaping
Ossia sostituiamo il carattere proibito con sequenze alternative che corrispondono alla stessa cosa. Ad esempoio " rappresentano le virgolette
Encoding
Encoding quando utilizzo una sintassi speciale per rappresentare il suo encoding naturale.

MIME
I Limiti di SMTP (3)
SMTP è un protocollo molto vecchio, affinché le necessità nuove siano retrocompatibili, sono presenti alcuni accorgimenti che vedremo in sto pezzo.
Principalmente questi problemi di endoing e escaping sono nati nell’ambiente del protocollo SMTP, perchée li c’erano alcuni caratteri speciali del protocollo, e potevi mandare solamente ascii 7 bit.
-
slides limiti SMTP

- Massimo 1 MB
- Solo ascii 7 bit
- Ogni 1000 caratteri ci deve essere un CRLF.
Il motivo è che queste restrizioni erano presenti nelle RFC iniziali per SMTP, e dato che non possiamo farne nuovi (troppo costo prolly) ci dobbiamo tenere queste cose.
Guardare internet message format
Su come funziona SMTP sono accennate in Livello applicazione e socket
Multipurpose Internet Mail Extensions
il mime riesce a risolvere questi problemi di limiti di SMTP, riesco a trasformare il tutto in un formato compatibile, e riesco anche a ritrasformarlo indietro!
-
Schema protocollo MIME
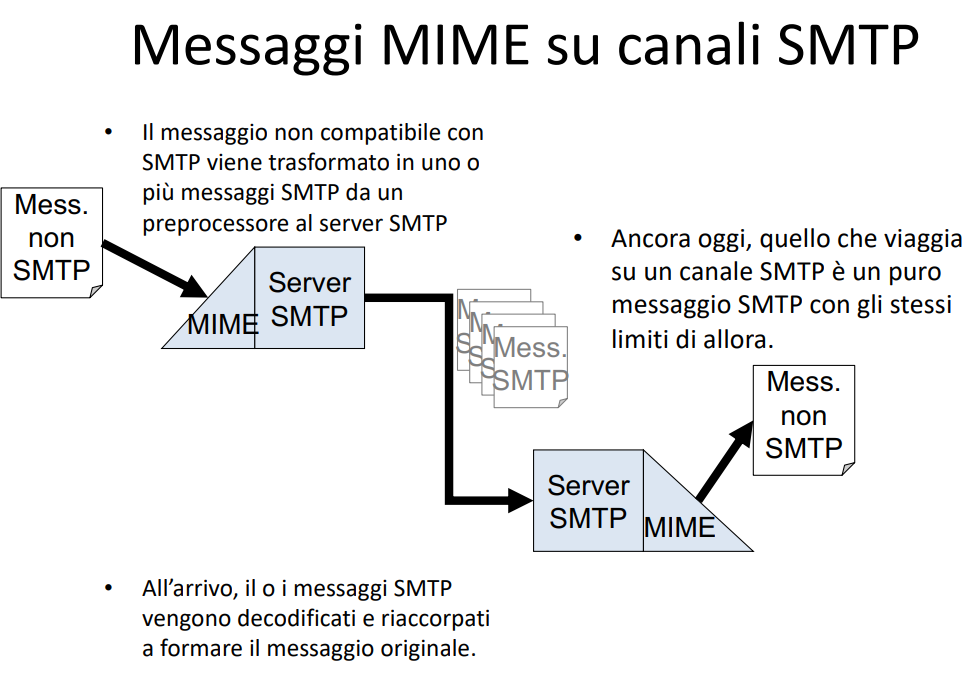
In questo modo riesco a risolvere tutti i problemi di limiti SMTP
- Caratteri ASCII US
- Le sequenze CRLF
- E la lunghezza dei messaggi (che viene spezzato)
TODO: parlare del multitipo
Headers del MIME (2)
-
Esempio di headers MIME

Devono essere specificati due campi:
- Content Type (il tipo del dato, con sottotimo e altri parametri utili che viene mandato, per capire poi dal ricevente cosa conviene convocare per capire il messaggio)
- Content-Transfer encoding, sono modalità per codificare i dati in modo che possano essere adatti al MIME. Esempi di transfer encoding sono sotto.
Quoted Printable and Base 64
Esempi di CTE sono quoted-printable, BASE64, nel primo si fanno escaping per caratteri che non sono printabili con un = seguito dal numero corrisopndente al carattere, di solito sono utilizzati solamente per messaggi con poche eccezzioni rispetto ASCII
-
Slide Quoted-printable

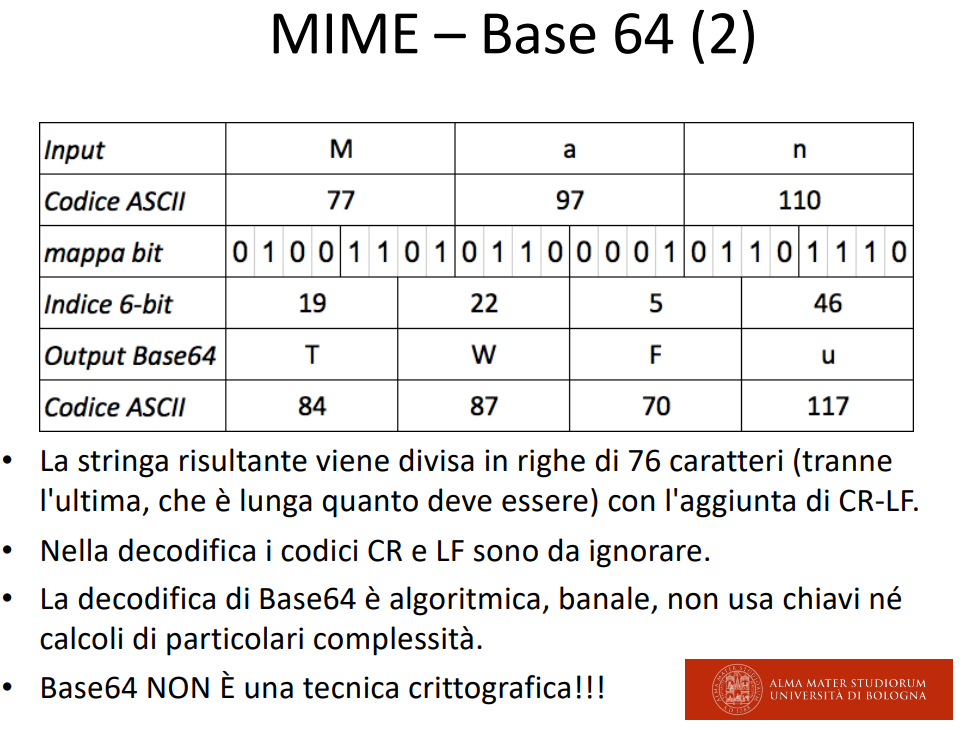
BASE64 da leggere BaseSessantaquattro, o BeisSicstiFor, non mix.
Per BASE è tutto tradotto in una codifica byte printabile, ossia si utilizzano 64 caratteri ASCII printabili per codificare 3 byte alla volta, questi 3 byte sono codificati in 4 lettere della mappa precedente, che si noti sono 2alla 6 caratteri.
Se mi mancano byte alla fine aggiungo del padding, che sono delle = nella parte encodata (il resto sono degli 0 credo).
-
Slides base64