Machine learning cannot distinguish between causal and environment features.
Shortcut learning
Often we observe shortcut learning: the model learns some dataset dependent shortcuts (e.g. the machine that was used to take the X-ray) to make inference, but this is very brittle, and is not usually able to generalize.
Shortcut learning happens when there are correlations in the test set between causal and non-causal features. Our object of interest should be the main focus, not the environment around, in most of the cases. For example, a camel in a grass land should still be recognized as a camel, not a cow. One solution could be engineering invariant representations which are independent of the environment. So having a kind of encoder that creates these representations.
Counterfactual Invariance
Counterfactual invariance is a formal framework to define the variables that influence and do not influence the output of a model under certain contexts (i.e. downstream tasks that you could have). It has been introduced in (Veitch et al. 2021) for text perturbations originally.
A first notion of counterfactual invariance
Suppose we have a function . Let's define a counterfactual for a random variable . Let's say is a random variable that represents our non-causal features, e.g. our background. We say is the result of when , so we force the background to be some specific thing. We would like to formalize the following idea: the outcome of should be only dependent on , not on .
We say is counterfactually invariant if the following holds: for any . How does this happen in practice? Ideally we would like to train any counterfactual, but this is practically impossible (too many resources to get camels into Himalaya to create this counterfactual! Additionally, we have too many possible background environments!)
Causal Graphs
The main advantage of using causal graphs is the intuitive understanding of the relations between the variables. Furthermore, these graph relations could be used to define algorithms for inference that exploit their structure. So we say: causal graphs are both interpretable and useful inference models. We now explore some desiderata that is clearly understood in terms of causal graphs: to correctly formalize the notion of counterfactual invariance.
Causal Graphs
In causal scenarios our input features indeed have a causal relation with
Suppose we want to classify cancer and we have three features, , where location is , , and is a boolean is our , or categorical, .
We can build a causal graph of possible relations between the variables.
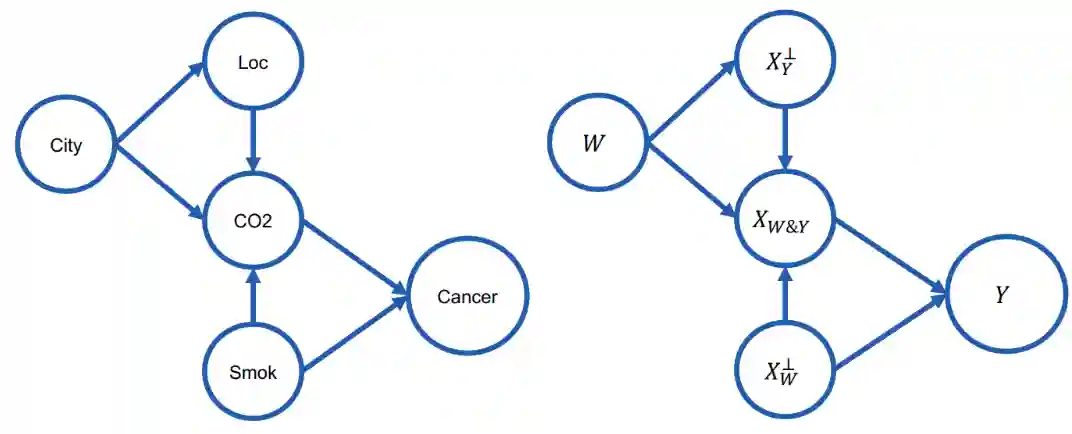
In the above image is the set of variables that do not influence , and is the set of variables that influence both and . And is the set of variables that are not influenced by but do influence .
Anti-Causal
Let's consider another scenario anti-causal scenario, where we want to predict celiac disease, we have stomach ache, fatigue and income as features. Our background variable would be the Job.
In these kinds of scenarios, our output random variables have a causal relationship with the features in .
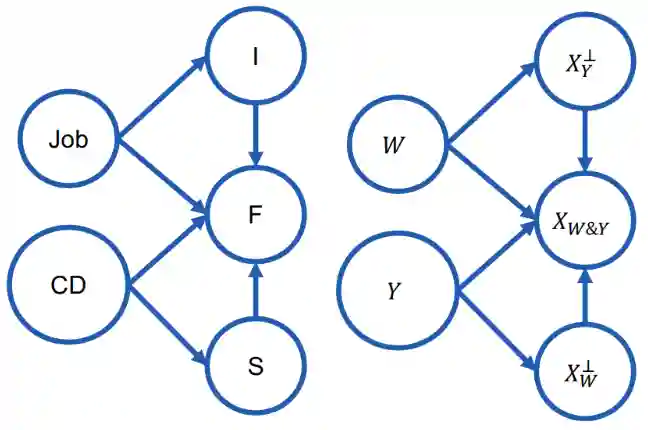
Whys of non-causal relations
We can say that two are the main causes of non-causal associations in causal graphs:
- Confounding variables: existence of another random variable U that could affect both of the variables of our interest.
- Selection bias: We have a variable S that filters the dataset based on the features that we want.
Where are the input features , are the output, and is the environment. In this whole set of note we will keep this nomenclature. An example of selection bias is studying the success of jobs, but you just sample from people on LinkedIn. Formally, we say we have a selection bias if all our samples have a selection criteria . If we want to account both for confounding variables and selection bias, we say our samples satisfy
We say that a relationship is purely spurious if
That is: we can predict by only using features that do not depend on . This is a easy way to define spuriousness.
Simpson's Paradox
We give the intuition on this paradox with a simple example. Let's say we have treatment A and B, we would like to know which treatment is better. We sent 350 to A and 350 to B. Let's say we observe that with treatment A recovered, with B recovered. Seems treatment B is better. But in the case we have another variable, e.g. the severity of the illness, the view could be far more different! These are called confounding variables. When designing an experiment we should keep also this in mind.
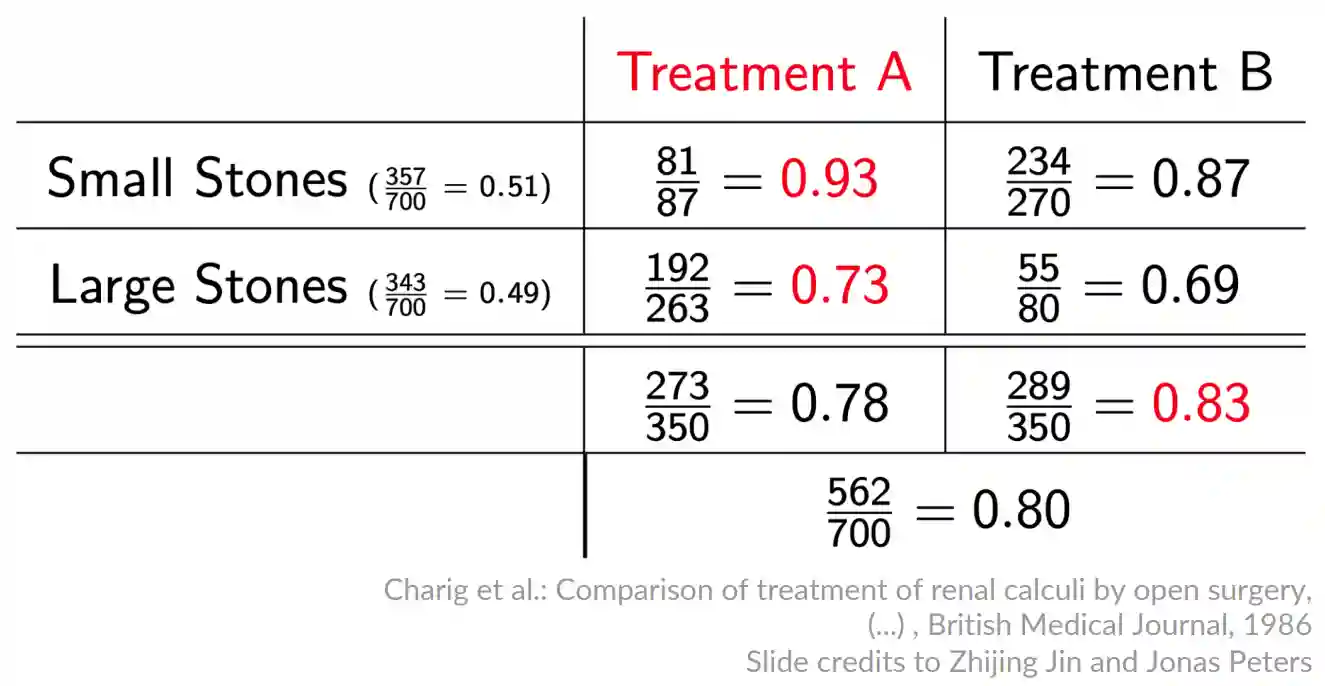
Simpson's paradox occurs due to confounding variables that influence both the group formation and the variables being studied. The decision whether to use treatment or should be based on causal considerations for Judea Pearl: different causal structures could arise for the same data, see (Pearl 2009) Chapter 6.1.3.
This phenomenon can be described in terms of events in probability. Consider to be the variable of effect, a cause (for example the drug trial) and an indicator variable describing a sub-population (i.e. Male or Female). We have:
A formal definition for counterfactual invariance
Intuitively a model is counterfactually invariant if it only depends on which are the features independent on the background (the cow in the example before). The following has been proven by Veitch in (Veitch et al. 2021), this should be still an active area of research.
For an estimator to be counterfactually invariant we need:
- Anti-causal scenario
- Causal scenario without selection (possibly confounded)
- Causal scenario with selection we need as long as do not influence , i.e. we have .
Therefore, connecting to the intuitive notion of counterfactual invariance we would like to have to have the same distribution as for any . It is
V-structures
This is called d-separation.
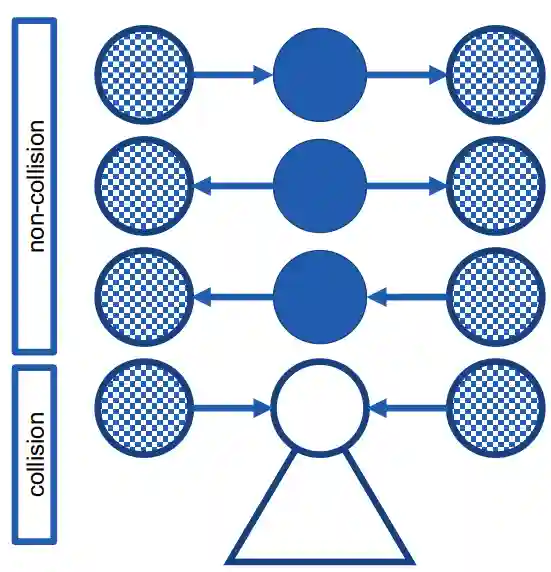
Let's take for example they are 3 random variables in this order. They are all Markov Chains. The nice thing that we have is that
A V structure is a Markov chain in this form : if i know B, then are related to each other.
For example, suppose we have a chain which is a Markov chain, and conclude that knowing , makes A and C conditionally independent. Then , in particular, if we consider and we can observe they are conditionally independent given :
One thing that has not been said about collisions, is that we need every child of it to be not observed (this is what the pyramid below that means).
Similarity Metrics
If we have two that represent the same idea but in different backgrounds, we would like their two representations to be somewhat similar. This brings the need to create some sort of a metric to measure their similarity. This section attempts to build upon this idea. This seems to be one of the seminal papers on the idea.
Checking the difference
We would like a way to compute a metric that tells us how different two probability distributions are (this is called two sample or homogeneity problem) . Given a probability space and another , and is compact. Given some realizations:
We would like to quantify the sameness between these two distributions. Note that they share the sample space and the Sigma algebra on that.
The idea is that if then there exists a set in the sigma algebra that has different measure (else, it would be exactly the same). We can write the same thing with the use of expectation as:
The indicator can be approximated by a continuous trapezoidal function with very high slope.
So checking the difference is the same as computing the expectation of the approximation of the indicator function. This has been formally proven by Dudley (2002) lemma 9.3.2 (they have proved something stronger).
Comparison with KL Divergence
This section was generated by GPT.
| Feature | MMD | KL Divergence |
|---|---|---|
| Requires explicit densities | No | Yes |
| Symmetry | Symmetric | Asymmetric |
| Support mismatch | Well-defined | Can be infinite |
| Computational feasibility | Efficient for empirical samples | Challenging for high-dimensional data |
| Robustness to noise | Robust | Sensitive |
MMD is ideal in situations where:
- You only have empirical samples of the distributions.
- The distributions are high-dimensional and nonparametric.
- A symmetric or support-insensitive measure is needed.
Maximum Mean Discrepancy
The Maximum Mean Discrepancy is a way to measure the difference between two distributions that builds upon the previous idea. It is defined as:
Where is a set of functions that are bounded and continuous. The MMD is a metric that measures the difference between two distributions (Müller 1997). The bad thing is that it is difficult to compute: the space of the functions is quite large. In this discussion we will restrict ourselves to the unit sphere of universal RKHS, see Kernel Methods for that. One interpretation of this set is the polynomials whose coefficients squared is 1.
Riesz Representation Space
Applying a bounded linear operator in a Hilbert's Space, then the operator can be represented as a inner product with a function in the space. This is the Riesz Representation Theorem in short! The main usage is moving from the functional realm to an algebraic realm. So we have a strong connection between functional analysis and algebra!
Formally, it states that for every linear functional on , a Hilbert's Space, there exists a unique vector in such that
And the norm of the functional is the norm of the vector. In this context, we use it to say that we can write
Algebraic Maximum Mean Discrepancy
We will use Riesz representation theorem and the above MMD to come up with an algebraic version of it that should be easier to compute. By Riesz theorem, computing is the same as computing the inner product with where is from a family of functions in the RKHS (See Kernel Methods). We express this version of MMD in the following way (Lemma by Borgwardt et al. 2006):
The nice thing is that the latter form can be empirically approximated:
And the last two are also compute accordingly.
References
[1] Veitch et al. “Counterfactual Invariance to Spurious Correlations in Text Classification” Curran Associates, Inc. 2021
[2] Pearl “Causality” Cambridge University Press 2009