2 Storia
2.1 0: Computer Meccanici
dal 1600 a oggi
2.2 1: Computer a Valvole
Principalmente i computer della seconda guerra mondiale
2.3 2: Computer a Transistor
Abbattere i costi
2.4 3: Circuiti stampati
- Computazione parallela
- Multiprogrammazione (Caricamento di più programmi)
2.5 4: VLSI
Possibilità di creare tansissimi transistor
2.6 5: Computer moderni
2.6.1 Computer Ubiqui
2.6.2 Computer invisibili
2.7 Velocità di calcolo
2.7.1 Flops and MIPS
3 CPU
La struttura moderna degli elaboratori sono basati principalmente sull’architettura di Von Neuman, l’unica differenza è che gli elementi di questa architettura.
3.1 Struttura e funzione della CPU
La CPU si può dividere in tre parti principali:
- Una unità di controllo che coordina i processi
- Registri che immagazzinano temporaneamente piccole quantità di informazioni
- ALU che fa i calcoli ordinategli dalla CPU
3.1.1 Registri Principali
- Program Counter o Instruction Pointer
- Contiene un pointer all’istruzione da eseguire così lo prende dalla memoria
- Instruction Register
- Contiene l’istruzione da eseguire
- Memory Address Register
- Prende l’indirizzo del contenuto interessante dalla memoria
- Memory Data Register
- Prende il contenuto dalla memoria
- Program Status Word
- Raccoglie lo stato di esecuzione del programma, se fallisce se tutto ok oppure se ci sono errori
3.1.2 ALU
Aritmetic Logic Unit, è la componente che fa i calcoli.
Per sapere cosa deve fare, è la Control Unit che collega certe vie dai registri all’ALU.
A seconda del genere di architettura può collegarsi direttamente in memoria (CISC) oppure sempre passando per i registri (solitamente RISC)
3.1.3 Central Control Unit
Il processore che decide cosa fare, se chiedere qualche altro pezzo dalla memoria seguendo il processo FDE Fetch Decode, Execute, oppure Scrivere qualcosa in memoria e cose simili.

3.2 Filosofie Architetturali
Complex Instructions Set Computer and Reduced Instructions Set Computer definiscono delle filosofie di architettura degli elaboratori differenti.
3.2.1 CISC e microprogrammazione
Utilizza una interpretazione che credo sia cosa a cui il prof. ha riferito come microprogrammazione, ovvero una programmazione delle istruzioni a livello molto basso.
Questo livello di interpretazione rallentava la macchina, perché non era direttamente eseguito sull’hardware. Inoltre la tendenza ad accedere direttamente la memoria **rendeva questo modello a volte imprevedibile in termini di tempo
-
Esempio di microprogramma

Chiaro che se questo interamente fosse considerato una istruzione, ci sarebbe un alto bisogno di cicli di clock (diventarebbe in generale più lento).
3.2.2 RISC e peculiarità
Una delle peculiarità principali delle architetture RISC è il numero ridotto di istruzioni necessarie (che però erano molto veloci perché girava direttamente sull’hardware).
Inoltre ha introdotto un sistema load store con cui affacciarsi alla memoria.

3.2.3 Alcuni confronti
La filosofia attuale è la RISC, però a causa della grande presenza di elaboratori CISC, si è preferito creare architetture ibride che comprendano entrambi: presenza di istruzioni complesse che vengano eseguite su istruzioni harware di RISC. → Minore ciclo di Clock e quindi maggiore velocità.
La differenza principale è che CISC possiede istruzioni complesse molte dei quali vanno ad accedere la memoria (la parte lenta del processo) invece la RISC possiede soltanto i comandi load and store per accedere alla memoria, il resto delle istruzioni opera all’interno del microprocessore.
3.3 Velocità CPU
3.3.1 Clock e Data Path Cycle
Il significato di clock è spiegato molto meglio nella sezione dei Circuiti Sequenziali
Clock è tempo per l’istruzione più corta, se fosse ancora più corta è molto probabile che la CPU verrebbe indotta in errori molto comuni per cui il computer non funzionerebbe più (un istruzione viene eseguita quando il precedente non è ancora finito).
Una Data Path Cycle è l’intero processo che comporta lettura dai registri, calcolo e registrazione del risultato
3.3.2 Aumentare la velocità
Ci sono delle soluzioni per rendere la CPU più veloce:
- Migliori reti elettriche (agli informatici non interessa)
- Overclocking (per un pò)
- Memoria cache (spesso in RISC)
- Multi-core
- Pipelining
- Parallelismo
- Esattamente come una linea di assemblaggio di fabbrica, possiamo definire alcune parti per processi specifici.
- Parallelismo
3.4 Parallelismo
Circa 3-4 volte più veloce e poco costoso per crearlo, in quanto i pezzi sono efficienti, con pipeline di 5 sotto c’è bisogno di una sola ALU a differenza di 5 per avere funzionalità simili.
3.4.1 Pipelining
Spesso alcune istruzioni sono ottimizzate in termini di tempo nel caso sia presente la pipeline o meno, per cui è interessante poter averlo a mente. Parallelismo livello istruzione
Esempio:
5 step.
- Carica l’istruzione
- Interpreta l’istruzione
- Fetch dei dati necessari
- Esecuzione dopo aver ricevuto i dati
- Scrittura del risultato.
Ogni singola istruzione passa ogni volta secondo questa pipeline, che lavorano in parallelo, velocizzando il CHIP.
3.4.2 Multicore ~ SIMD & MIMD
Ci sono dei computer moderni che contengono molteplici CPU uguali a quanto descritti in 3.1.1
SIMD
Single instruction-stream multiple data-stream *Istruzioni a dati diversi: Tutte le CPU hanno lo stesso stream di dati (magari elaborazione immagini, un qualcosa di ripetitivo su stessa cosa)
Si guadagna in control unit, unica, fetch unica.
Esistono anche i processori vettoriali.
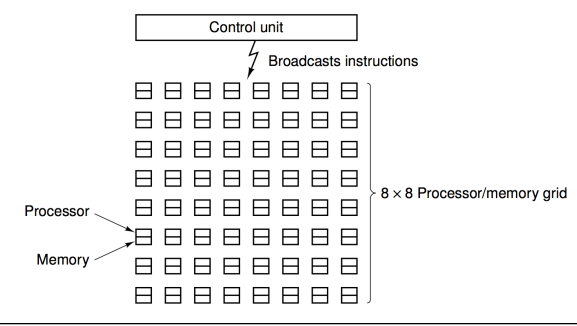
Di solito questo genere di architettura sono utili per istruzioni uguali a dati diversi come l’elaborazione di un immagine
MIMD
La differenza dal precedente è che l’istruction stream è multiplo, ma un pò più costoso perché ci sono molte CPU complete.
Avere troppe CPU su una memoria condivisa non andrebbe bene, perché si dovrebbero aspettare. Meglio avere una rete fra CPU per cose grosse.
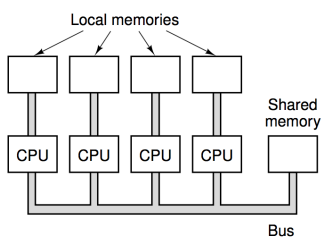
Cioè se collegassi troppe CPU, probabilmente l’unico bus andrebbe in stallo perché tutti cercherebbero ad accedere alla stessa memoria, e le CPU dovrebbero attendersi fra di loro, cosa non buona per la performance.
3.4.3 Rete di Computer
Una soluzione che si solito viene utilizzata dalle grandi aziende o comunque chi possiede le risorse è la costruzione di grandi reti di calcolatori che possano operare all’unisono, o comunque con certo criterio. Dovrebbero essere un sacco di CPU separate che comunicano con un computer centrale che agisce come da Unità di Controllo.
Di solito Multi-core e reti di computer sono conosiderati parallelismo a livello processore
Le redi di computer sono solitamente facili da costruire ma difficile da programmare, mentre invece un multicore è difficile da costruire ma facile da programmare.
Invece il pipelining è considerato un parallelismo a livello istruzione.
3.4.4 Prefetch-istruzioni
Questa cosa è molto simile al prefetch della Memoria cache.
Instruction Fetch Unit sono elementi di Hardware che caricano l’istruzione successiva nel momento in cui la presente è in esecuzione.
Questo avviene perché il caricamento dell’istruzione è spesso molto lenta.
Questa instruction cache prefecht può essere implementata a due livelli, Hardware o software.

3.4.5 Pipeline (e salti)

Esempio di pipeline
L’esempio fatto qui è già considerabile come un primo passo di Pipeline, in cui molteplici passi possono essere fatti allo stesso momento dentro la CPU.
Solamente la prima esecuzione servono 5-7 clock (a differenza delle parti), quindi basta un ciclo di clock per la fase più lunga per essere sicuri, ecco che riusciamo a completare l’istruzione in modo molto più veloce.
Se una singola istruzione dovrebbe fare tutto, saremmo costretti a tenere un clock molto elevato e il computer nel complesso sarebbe molto lento.
Salti
Se faccio un salto allora c’è un buco nel pipeline, ossia cose nel pipeline che non eseguono (perché devo saltare), cioè fetch e decode di certe istruzioni non mi devono servire.
(ho decodato una istruzione) ma nel frattempo ho già caricato 4 e 5 che non mi servono!
3.4.6 Predizione di salti
Possiamo utilizzare certe euristiche (ragionamenti caso per caso) per predire alcuni salti.
Salti all’indietro
Si possono prevedere per cicli while e for dei salti all’indietro.
Per salti incondizionati si può mettere una instruzione NOP in modo che faccia salti incondizionati senza sprecare istruzioni.
-
Esempio data race (read after write)
AX = 0
BX = 0
DX = 0
AX = DX + 1
BX = AX - 1
- fetch a
- decode a, fetch b
- leggo DX (a) , decode b
- DX + 1 (a), leggo AX (b) MA STO LEGGENDO TROPPO PRESTO!
Quindi devo chiudere AX ed aspettare che AX venga scritto
A volte, tipico dei processori CISC, si tende a eseguire minicomandi in ordine diverso perché ritenuti più efficienti, quindi si mischia un pò, proprio come intendi per combinatorio e la fai.
Entra cisc ma esegue risc.
Esiste una BPU (Branch Prediction Unit), che cerca di predire l’esito di un salto, come spiegato in questa pagina di wiki e una BTP (Branch Target Predictor) che controlla le istruzioni nel ramo di arrivo (qui). Questi sono le componenti principali che determinano la predizione dei salti.
In alternativa si mettono dei NOP. o di arrivo (qui). Questi sono le componenti principali che determinano la predizione dei salti.
In alternativa si mettono dei NOP.