Introduzione al design logico
- Conoscenze sul carico dell’applicazione, ossia se ha più read rispetto a writes per esempio, sono dei priors in pratica
- Un design concettuale spiegato in precedenza.
E si avrà in output un design logico con anche un po’ di documentazione.
bisogna in questa fase valutare la performance principalmente su indicatori, ossia una operazione quante istanze visiterà? Invece di garanzie sul numero di transazioni al secondo.
Indicatori visti (2)
Costo di una operazione: viene valutato in termini di numero di occorrenze di entità e associazioni che mediamente vanno visitate per rispondere a una operazione sulla base dì dati; questa schematizzazione è molto forte e, pur nelle semplici valutazioni che svilupperemo, sarà talvolta necessario riferirci a un criterio più fine; Occupazione di memoria: viene valutato in termini dello spazio di memoria (misurato per esempio in numero di byte) necessario per memorizzare i dati descritti dallo schema.
I volumi sono un concetto importante, sono una stima di quante entries dovranno avere, e serve per avere una idea di come progettare quella cosa. Bisogna utilizzare questi indicatori per valutare in che modo progettare la ristrutturazione e la logica.
NOTA: C’è un modo molto più complicato per fare questa analisi, ma per questo corso è ok valutare solo queste.
Metodi di ristrutturazione E-R
Redundancies analysis
Per la ridondanza bisogna fare una analisi di efficienza per capire se è buono o meno lasciare la ridondanza.
Tipologie di ridondanze (4)
Per il prof è importante due cose:
-
Attributi derivabili
-
Associazioni derivabili
-
Attributi derivabili da cose della stessa entità
-
Attributi derivabili da altri
-
attributi derivabili da conteggio
-
Associazioni derivabili dalla composizione di altre associazioni in presenza di cicli
Esempi:
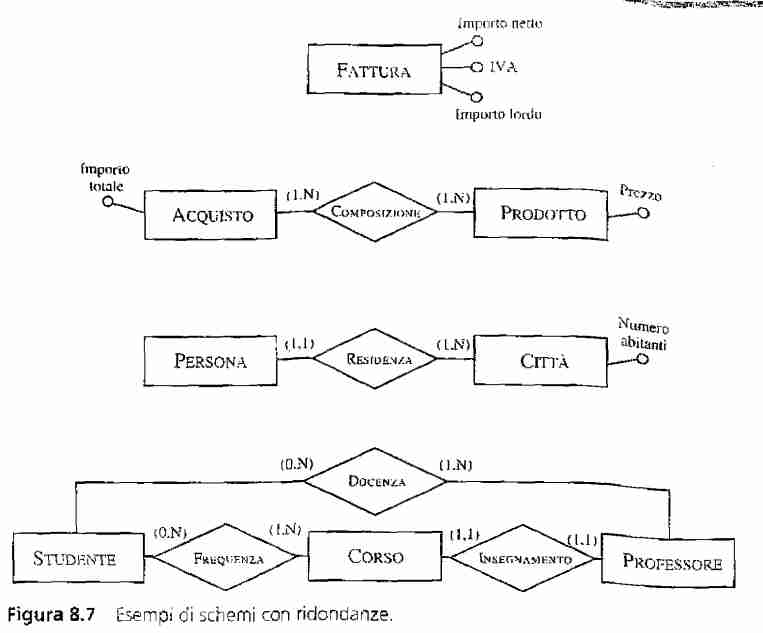 Nell’ultimo esempio, basta fare la join per avere quella informazione, un ciclo implica una ridondanza in pratica.
Nell’ultimo esempio, basta fare la join per avere quella informazione, un ciclo implica una ridondanza in pratica.
Generalizations deletion
We need to delete the generalizations because in ER explained in Design del database the generalizations are not possible. A common way to fix this is embed children in the parent or something very similar.
Example of deletion of generalization (3)
- In un caso abbiamo che il genitore prende tutti i campi.
- Oppure elimina il genitore e metti due relazioni
- Oppure crea relazioni col genitore
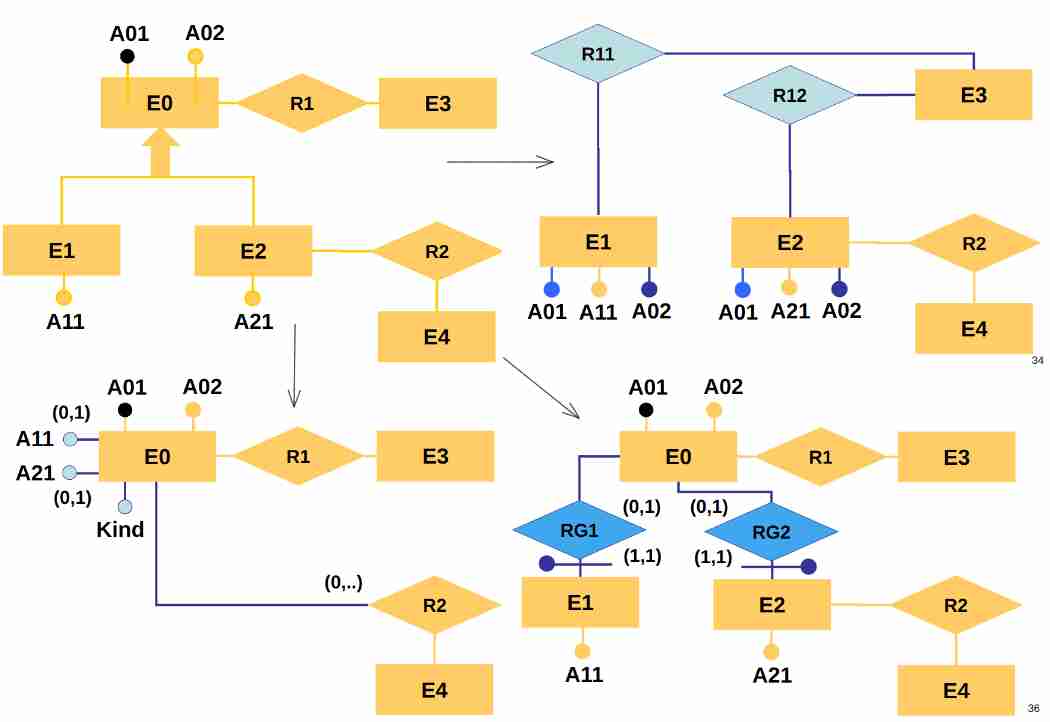 Ma come fare a scegliere la versione corretta? Vogliamo prendere la soluzione che ci permette di minimizzare il numero di accessi, come per esempio se sappiamo che figli e genitori vengono acceduti insieme, ha senso usare la freccia in basso a sinistra!
Ma come fare a scegliere la versione corretta? Vogliamo prendere la soluzione che ci permette di minimizzare il numero di accessi, come per esempio se sappiamo che figli e genitori vengono acceduti insieme, ha senso usare la freccia in basso a sinistra!
Partitioning or grouping of entities
Se una stessa entità ha due attributi molto diverti, ossia c’è solamente un accesso per uno, invece che per tutti, potrebbe avere senso dividerli. In modo simile se ho due entità che vengono spesso accedute assieme potrebbe essere una cosa sensata accorparli assieme.
L’obiettivo è sempre efficienza degli accessi.
Partizionamento verticale o orizzontale
Possiamo fare partizionamento in verticale o in orizzontale Verticale quando spezziamo una entità in due e le relazioniamo (utile quando accediamo solamente certe cose della tavola).
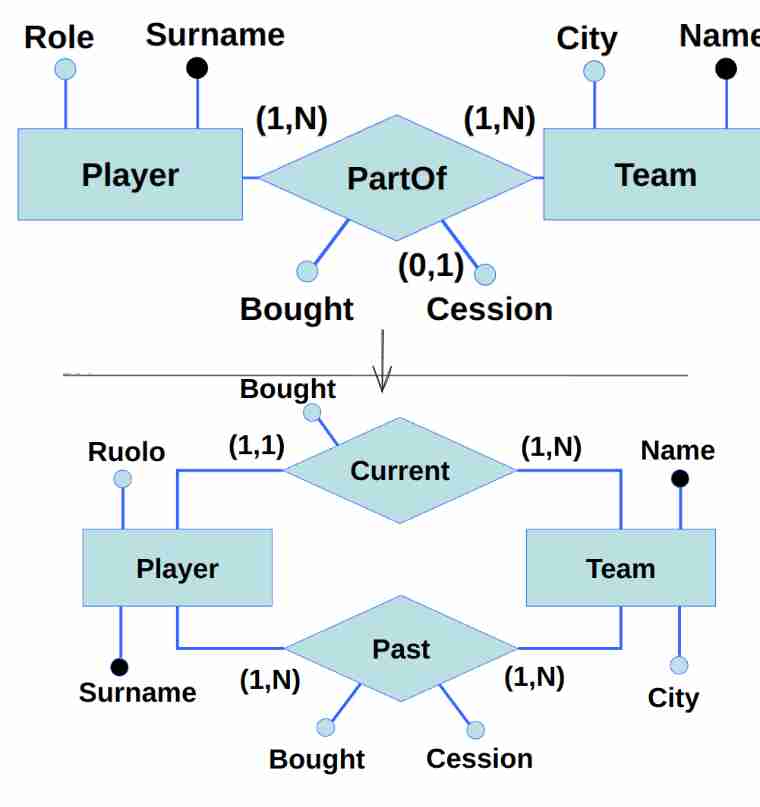
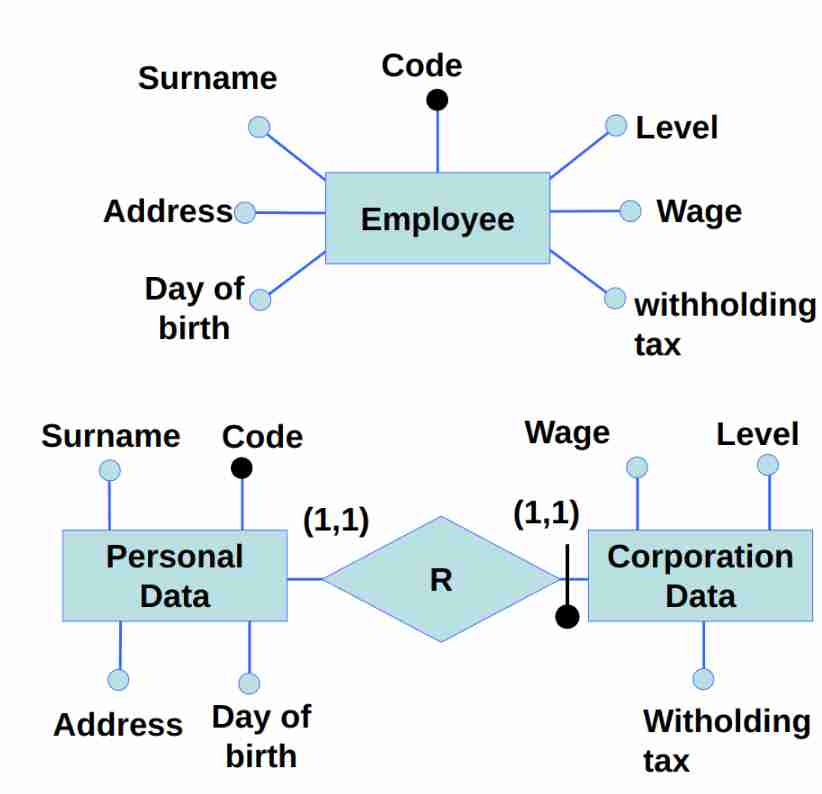 Orizzontale quando ad esempio provo a dividere correnti e passati (dividere la stessa relazione in più forme!).
Orizzontale quando ad esempio provo a dividere correnti e passati (dividere la stessa relazione in più forme!).
 ### Identifying the primary keys (non fare)
Questo passo è chiaramente il passo necessario per utilizzare E-R nel nostro caso.
### Identifying the primary keys (non fare)
Questo passo è chiaramente il passo necessario per utilizzare E-R nel nostro caso.
- Informazioni necessarie
- Le chiavi primarie in certi contesti possono essere complessi! E anche utili per identificare, non ho capito bene l’esempio del ferramenta fatto in classe (una nota è che i ferramenta si fanno codici enormi e complessi come chiavi ed è una brutta pratica probabilmente).
- Notare che saranno usate spesso, quindi non farle grosseeee!
La cosa semplice è creare codici identificativi, invece di avere chiavi complesse.
Traduzione in schema logico
Tradurre relazioni
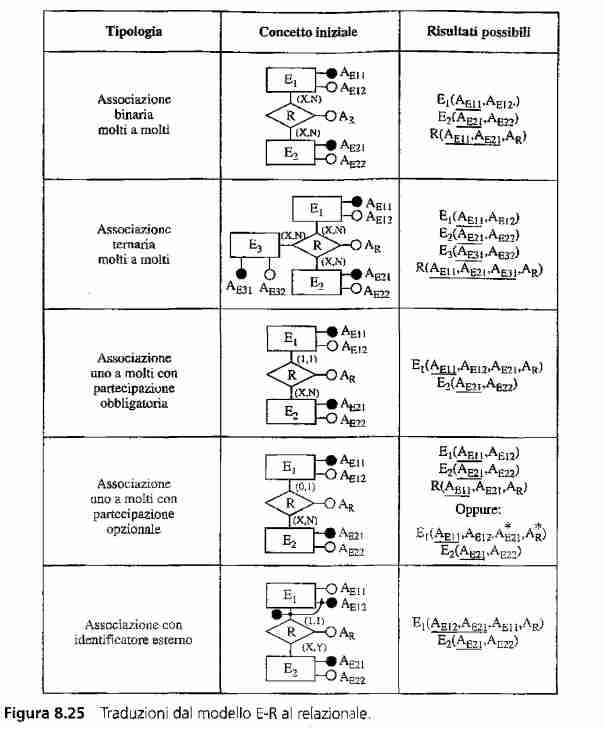
Questa tabella riassume praticamente tutto. (303 Atzeni)
La singola relazione
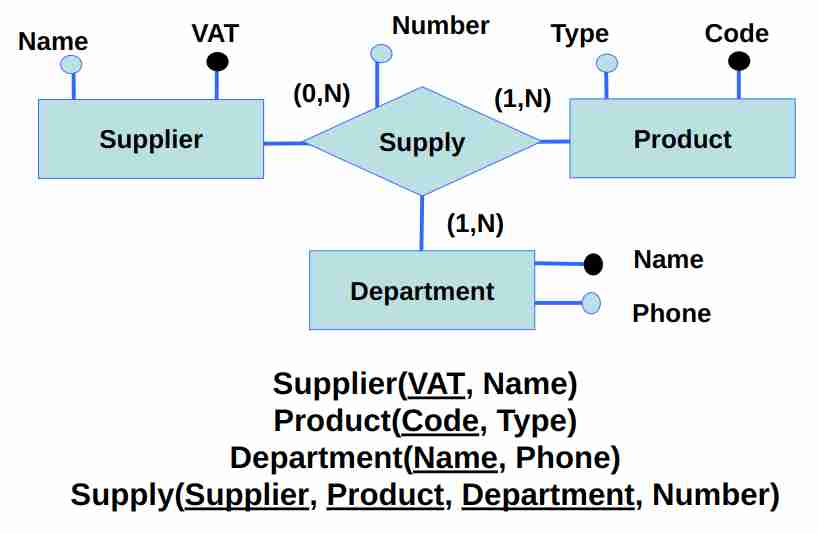
Una volta che abbiamo una relazione in E-R possiamo creare una tavola anche per questa parte! L’importante quando facciamo questo, bisogna encodare una referential integrity constraint che è la cosa bella della tabella.
La nota è che aggiungere la constraint non è sufficiente per tenere in considerazione vincoli di cardinalità. Anche se è n-aria si può modellizzare senza troppi problemi!
 #### Relazioni ricorsive
#### Relazioni ricorsive
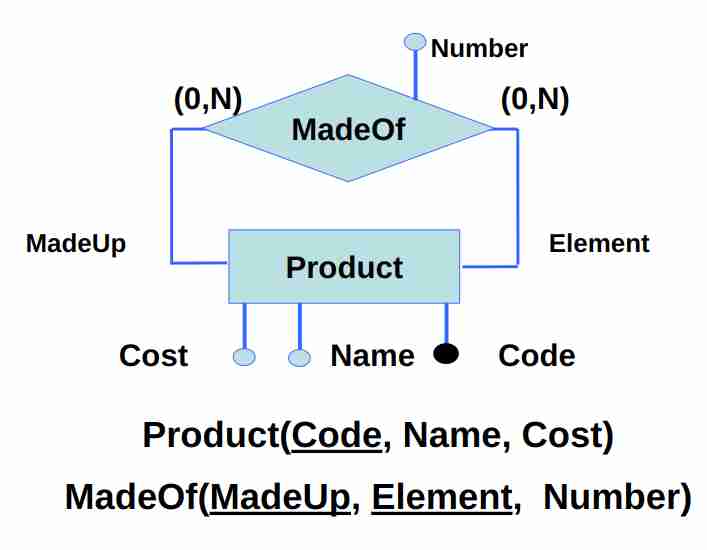 La seconda tabella modella la parte ricorsiva (in teoria le due chiavi foreign dovrebbero essere code e code, ma il nome è migliore in questo modo per esprimere questa relazione)
La seconda tabella modella la parte ricorsiva (in teoria le due chiavi foreign dovrebbero essere code e code, ma il nome è migliore in questo modo per esprimere questa relazione)
Merge di relazioni
A volte può essere utile unire relazione con l’entità, succede spesso per relazioni unarie da una parte, perché così faccio enforcing del 1. È una cosa principalmente pratica, di difficile formalizzazione, ma deve passare l’idea diciamo.