The perceptron
-
Slide summary of working of perceptron
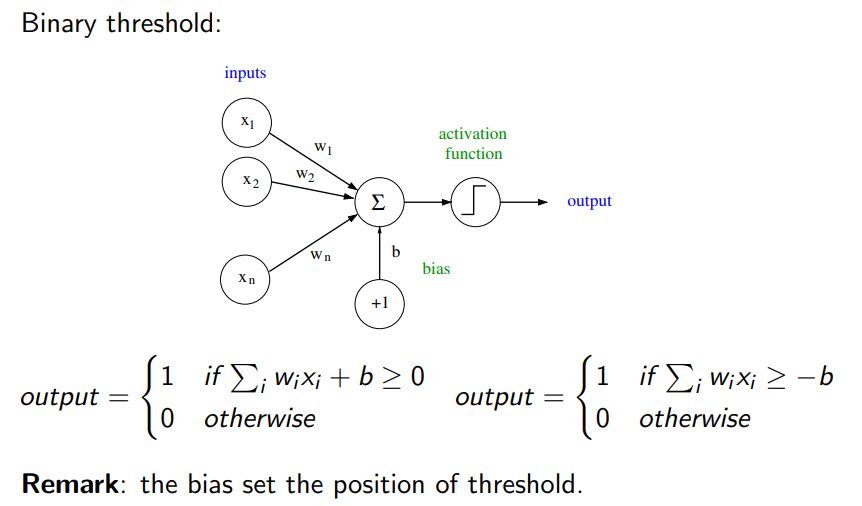
Note on the bias: it is only useful to move the treshhold where to consider the output to be 1 and where to be 1.
Now we ask what can be predicted by a perceptron?
We can see the update rule of the perceptron:
$$ \begin{cases} w = w + \alpha x \\ b = b + \alpha \end{cases} $$$$ \alpha = \begin{cases} 0 & \Theta(x \theta + b) = y \\ -1 & \Theta(x \theta + b) > y \\ 1 & \Theta(x \theta + b) < y \end{cases} $$Linearly separability necessity
Hyperplanes, because that equation is an hyperplane, so we are sure that we can predict an hyperplane, and that it, and it’s only it. (it’s predicting wheter it can be above or below that line). So the perceptron is correct only if the data is linearly separable!
È molto peculiare che questa struttura predica qualcosa di tanto semplice! È solamente quella roba, perché basta interpretarla come la linea nel piano, si potrebbe forse dire che esiste un isomorfismo fra percettrone e iperpiano in Rn, dove n è la dimensione di input!
Novikoff’s Theorem
Initialized at zero, the perceptron converges in at most $\lfloor \gamma^{-2} \rfloor$ update steps on any $\gamma-$separable sample.
- No gradient information needed!
- We have an error bound on the test!
- Number of iterations may be much larger (I don’t know why)
- Finite convergence
Learning logical operators
We can predict NAND operators, because we can create a plane to divide that, but we can’t say the same of XOR operators.
Predicting the NAND operator
<img src="/images/notes/image/universita/ex-notion/Expressiveness of NN/Untitled 1.png" style="width: 100%" class="center" alt="image/universita/ex-notion/Expressiveness of NN/Untitled 1">
The XOR problem
If we try to predict XOR, we can see that his graph is
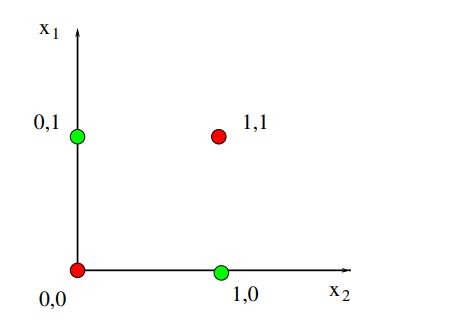
We can see that a line can’t be predicting this function, so we can say that perceptron is not COMPLETE. can’t predict every function, and we can say it’s not enough expressive.
Bad thing because for example perceptron can’t be predicting some kind of pixels put in that configuration, if we interpret the preceding image as pixel colors. It’s useless (gives me no new information) when we have to compare two features, because this implies it is not linear!
This problem is historically very important because it has influenced the first AI winter. They were surprised that it couldn’t even learn this easy function.
Multiplayer Perceptron
With the preceding idea, if we can compose nands, we can compute every logical cirtuit, this is the same idea behing the completeness of MLP, this can compute everything! (even two layers is enough using this NAND analogy!)
-
Slide XOR prediction with MLP
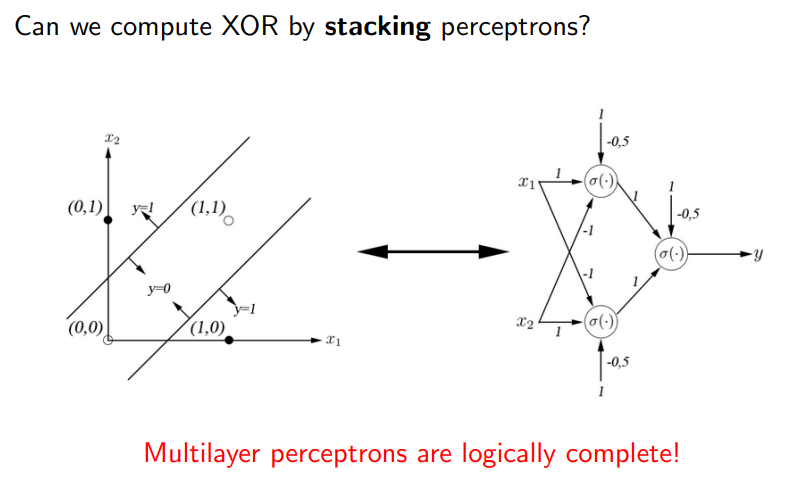
Shallow networks are COMPLETE after this argument. (but with deepness we would need less neurons (maybe exponentially less, with an argument based on CNF exponential explosion when they are not so deep)!, so deepness has some advantages).
Continous case
Can we compute a continous function as precisely as we want with a neural network?
At the end yes! Even with single hidden layer NN! The argument is based on step function activation (and the ability of sigmoid or other non linear functions to mimic the step function when we have the right weights). We can add or subtract an arbitrarily small function, with a value as small as we want!
See this for more information!
We should not be surprised by this expressiveness, also a big table of numbers would be able to aproximate quite well some functions, to an arbitrarily precise fascion.