Memoria statica
Elementi in memoria statica (4)
- Variabili globali
- Istruzioni macchina
- Costanti
- (Variabili locali, paramentri e ritorno di funzione?)
Le primi tre elementi descritti di sopra sono sicuramente presenti dopo la fase di compilazione, infatti sono allocati dal compilatore in una zona presente nell’eseguibile (un esempio è il READONLY per le stringhe in C).
Quindi se vogliamo
- Avere funzioni ricorsive
- Potere allocare e deallocare variabili in modo dinamico
Abbiamo bisogno di far uso di Pila o Heap, che riescano a cresere e restringersi in modo dinamico.
Implementazione di funzioni statiche
Si potrebbe anche utilizzare la memoria statica per implementare le funzioni, ma questo ha il fortissimo drawback che non permette la ricorsione in quanto stiamo assumento che in ogni momento di esecuzione la funzione è chiamata una singola volta. (ho un unico indirizzo di memoria per l’indirizzo di ritorno.
Infatti se chiamassimo in modo ricorsivo questa funzione, perderemmo alcuni valori, come l’indirizzo di ritorno, il valore di ritorno precedente, e porterebbe in uno stato invalido.
Oltre a questo avremmo un elevato uso della memoria nel caso in cui il numero di chiamate di funzioni sia in media minore del numero di dichiarazioni di funzione (avremmo un sacco di funzioni inutilizzate).
-
Slide di quanto memorizzato per la funzione statica
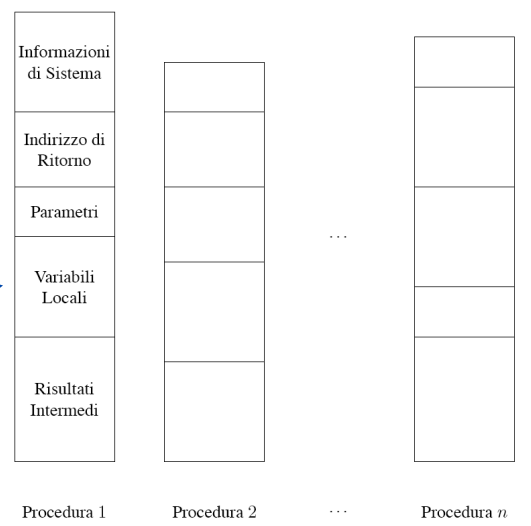
Figura 7.1 Gestione della memoria statica. per le funzioni
Sull’efficienza
Solitamente se utilizziamo questo metodo il compilatore solitamente è in grado di accedere a delle variabili utilizzando un OFFSET senza dover stare a fare risoluzione di nomi simbolici (una volta che abbiamo un frame o RdA, possiamo calcolare la posizione della variabile locale, o parametro attraverso l’offset sul base pointer, che qui è anche chiamato puntatore di RdA). Qualcosina in più forse c’è da fare sulle variabili non locali
Un altra ottimizzazione è memorizzare i risultati intermedi su REGISTRI invece che utilizzare la stack. In generale ci sono moltissimi modi di ottimizzare, quindi non andiamo a parlare di questo.
Gestione della pila
La pila è la struttura più comoda per la gestione dei blocchi di codice, che come abbiamo descritto in Nomi e Scope, devono essere LIFO, ossia il blocco più annidato deve finire prima di uscire. Questo è il motivo per cui possiamo giustificare la gestione della pila. Ecco che si giustifica l’idea di creazione della pila di sistema.* Che è in grado di stabilire le posizioni delle variabili locale, dei parametri attraverso un Offset rispetto al base pointer del frame.
Record di attivazione di blocchi (3)
Ne abbiamo accennato in 8.4.1 Activation record, parlando anche lì dei record di attivazione, in questo momento andremo a parlarne in modo più approfondito.
Ora parliamo brevemente di record attivazione di blocchi, per questi quando entriamo in un nuovo blocco vogliamo creare spazio per queste cose:
- Variabili intermedie (per storare calcolo intermedio)
- Variabili locali nuove
- Catena dinamica che mi dice in quale blocco sono, ed è utilizzato per eliminare tutto il nuovo spazio allocato in questo blocco.
Esempio:
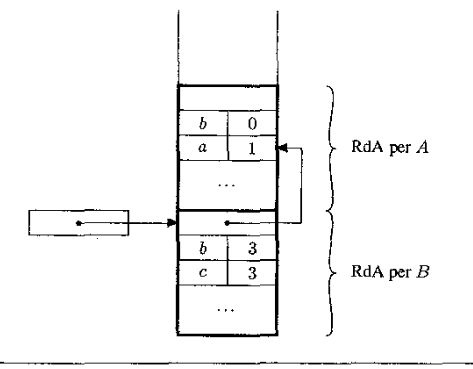
Figura 7 .3 Allocazione del record di attivazione per I blocchi A e B nell’Esempio 7.2.
Record di attivazione per funzioni (7)
Questi record di attivazione, anche chiamate RdA in modo abbreviato hanno lo stesso concetto per i record di attivazione per i blocchi, ma devono avere qualche informazione in più per indirizzo di ritorno e modo di ritornare la variabile di output.
- Tutti i 3 punti per i RdA dei blocchi
- Catena statica per gli scope (che attualmente non so in che modo venga utilizzata)
- Indirizzo di ritorno, per il program counter
- Indirizzo per il Valore di ritorno
- I parametri di chiamata della funzione.
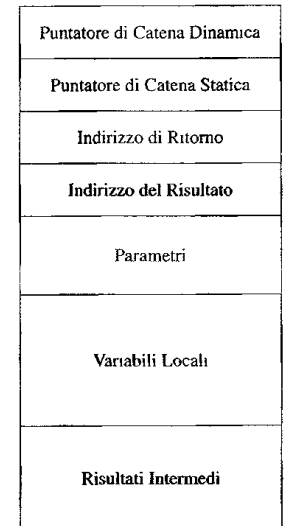
Figura 7.7 Struttura del record di attivazione per una procedura.
Gestione della pila a runtime (!!!)
In questa parte andiamo a parlare di alcune istruzioni che sono utili per implementare questo sistema di RdA in un linguaggio classico.
Andiamo a parlare di sequenza di chiamata per l’insieme di procedure che deve eseguire il chiamante prima di entrare nel blocco della funzioen chiamata, e una sequenza di ritorno per uscire dal blocco, poi di prologo e epilogo per l’uscita. ora nel pezzo sequente andiamo a descrivere alcune istruzioni da eseguire per entrare ed uscire da un blocco di RdA di una funzione.
Questa divisione è necessaria perché alcune cose possono essere fatte solo dal chiamante, e altre solo dal chiamato!
Chiamata di funzione
Questa parte interessa la parte di sequenza di chiamata e il prologo della funzione.
- Allocazione dello spazio necessario nella stack (per parametri, variabili locali, e risultati intermedi, e catene statiche e dinamiche).
- Passare i parametri (di solito copiati nella nuova RdA)
- Aggiornare il puntatore di RdA al nuovo, in C di solito è il base pointer, anche chiamato frame pointer.
- Salvare quanto necessario dai registri (e.g. il chiamante deve settare l’indirizzo di ritorno della funzione).
- Salvare il PC precedente, e settare il nuovo PC.
- Eseguire codice di inizializzazione specifico del linguaggio, se c’è (anche in C mi pare ci fossero alcune istruzioni, di solito erano nel prologo, come dei push rbp).
Ritorno del controllo al programma chiamante
- Ripristinare i valori dei registri precedenti.
- Risettare il PC precedente
- Copiare il valore di ritorno nell’indirizzo giusto
- ripristinare il puntatore di RdA
- Deallocare la parte della stack che non utilizziamo più.
- Esecuzione di codice di uscita.
Gestione della heap
Per la heap non è possibile utilizzare stack perché in questo caso l’utilizzo non soddisfa la proprietà LIFO tipida della stack, posso freeare una cosa anche prima di una cosa allocata dopo diciamo. Bisogna quindi creare un metodo di gestione dinamica della memoria differente.
Questo è solamente una zona contigua di memoria diversa dalla stack, in cui possiamo allocare e deallocare dinamicamente cose, non c’entra niente con la struttura di dati!
Dimensione fissa
Questa è l’implementazione della heap più semplice, in pratica divido tutto il mio array disponibile in blocchi liberi disponibili.
Quando vado ad allocare un blocco, vado a togliere questo blocco e metterlo a disposizione al chiamante, a chi ha allocato il blocco, e tolgo questo blocco dai liberi, ora la lista dei liberi punterà al prossimo blocco libero.
Quando vado a deallocare il blocco non faccio altro che marcare come libero il blocco, reinserendolo nella lista dei liberi.
Dimensione variabile
Questa è una soluzione molto più bella per quanto riguarda la soluzione della frammentazione interna, ossia quanta parte di memoria ho ancora inutilizzato, se ho richiesto un blocco (e.g. prima se avevo blocchi da 256, anche se volevo un singolo byte, mi dava un blocco da 256 e gran parte della memoria sarebbe stata sprecata per allocazione dinamica.)
Ora vorrei dividere tutta la memoria che ho secondo una certa logica, solitamente si può dividere in due modi di gestire questa cosa:
Heap dimensione variabile a liste multiple
Questa è una gestione della lista in cui ho più liste di una certa grandezza, i sistemi principali sono a buddy system o fibonacci heap. Discuteremo solamente il primo sistema, il secondo sistema è molto simile, con una leggera efficienza in più perché utilizzando i numeri di fibonacci si ha minore frammentazione interna**.**
Allora se richiedo un blocco di grandezza n, vado a cercare il blocco libero nella lista di k, con grandezza più grande di n (in buddy system le liste sono tutte di grandezze di potenze di due).
Se trovo una lista allora alloco e restituisco. Se invece non c’è, allora vado a cercare nelle liste più grosse se c’è. Se lo trovo, allora lo spezzo a metà, creando i buddies, uno lo aggiungo alla lista dei liberi della lista precedente, l’altra la restituisco come blocco allocato.
in fase di deallocazione vado a controllare se ho dei buddies spezzati, se esistono e sono liberi allora li ricompongo e li metto nella lista grossa originale, altrimenti rimane nella lista libera più piccola!
Heap a singola lista
Anche in questo caso possiamo avere dei problemi di frammentazione quando allochiamo e deallochiamo gli elementi della lista libera che possediamo, ne abbiamo parlato sempre in architettura quando abbiamo accennato alla paginazione: 9.3.2 In memoria: frammentazione esterna. Infatti anche qui possiamo andare a parlare di politiche di first and best FIT. Questi sono entrambi metodi di inserimento lineare, il primo favorisce il tempo, il secondo l’efficienza in memoria.
Con questo sistema ho un blocco di spazio UNICO disponibile. Quindi se chiedo n, posso effettivamente allocarti un blocco grosso n, senza nessuna frammentazione. Questo posso continuare finché non finisco la memoria. Quando la finisco potrei gestirla in due modi praticamente.
Lista dei liberi
In questo caso quando faccio free faccio append di tutti i blocchi deallocati alla lista dei liberi. Posso inserire controlli che quando ho due blocchi contigui nei liberi li compatto assieme. Questo è la compattazione parziale.
Poi quando finisco la memoria utilizzo direttamente la lista dei liberi per allocare nuovi blocchi, questo può portare al problema di frammentazione interna o esterna. Ci metto in tempo lineare ad allocare. (oppure posso tenere i blocchi ordinati, se utilizzo alberi ordinati allora log(n) per tirare via ed inserire.) Ma in generale ci sono molti modi per gestire questa struttura di dati.
Compattazione della memoria libera
Quando finisco la memoria, risolvo la frammentazione esterna rimettendo assieme tutti i blocchi allocati, e poi posso continuare l’algoritmo di sopra, allocando esattamente quando mi richiede.
Il problema di questo metodo è che difficilmente posso spostare le cose, che è una precondizione per poter utilizzare questo metodo.
Implementazione delle regole di scope
Abbiamo parlato per la prima volta di scope in Nomi e Scope.
Scope statico
Per implementare lo scope statico vogliamo utilizzare la catena statica presente all’interno del record di attivazione per poter risalire al blocco giusto.
In particolare dividiamo in due casi, il caso in cui il nome chiamato sia presente nell’ambiente locale del chiamante, e il caso in cui non lo sia. Questo è importante perché nella fase di sequenza di chiamata dovrebbe essere il lavoro del chiamante per impostare il puntatore di catena statica del chiamato. Notare che in questa sezione utilizziamo nomi come chiamante chiamato, ma il chiamato potrebbe anche essere riferimento al nome di una variabile, il concetto di risalita è comune.
Caso presente nell’ambiente locale
Questo è il caso semplice, so che la catena statica deve puntare al chiamante, quindi basta inserirla nel record di attivazione del chiamato!
Caso non presente
Questo è una cosa leggermente più complessa, se io so che il chiamato è a livello di annidamento statico n (per tenersi queste informazioni probabilmente si utilizzano informazioni di annidamento e di ambienti locale, che sono comunque presenti nella struttura (statica), e quindi le posso calcolare al momento di compilazione)), e il chiamante a livello di m, devo percorrere k = m - n, livelli per trovare il puntatore di catena statica del chiamato e settarlo puntatore di catena statica del nuovo RdA che mi ritrovo dopo aver risalito di k sulla catena statica.
Questo lo so perché dato che il chiamato è esterno, so che è presente nell’ambiente non locale, quindi non può che essere a livello di annidamento inferiore, quindi risalire la catena statica è corretto.
Chiaramente è una cosa molto inefficiente fare k dereferenziazioni di pointer per arrivare fino al punto che mi interessa, vedremo subito dopo un metodo per velocizzare questo sistema di scope statico.
-
Esempio funzionamento
!
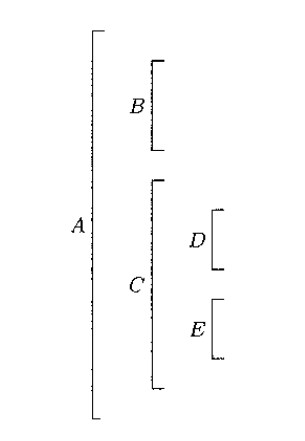
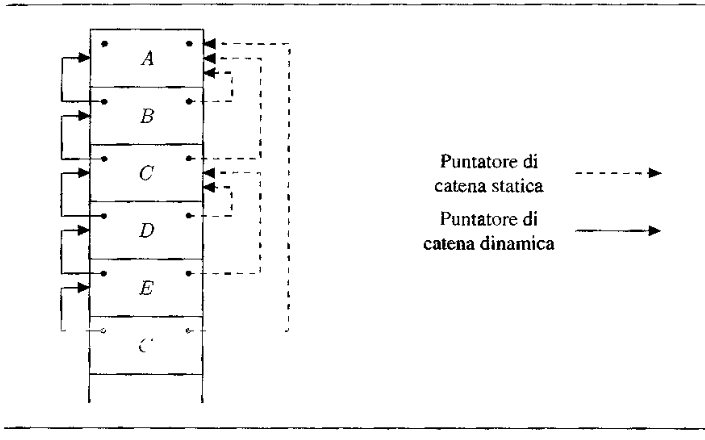
Figura 7.14 Catena statica per la struttura precedente e la sequenza di chiamate A, B, C, D, E, C.
statico: Il display
Vogliamo trovare un metodo più veloce per settare il RdA nel campo della catena statica, tanto che possiamo ridurre a k dereferenziazioni a solamente un numero costante piccolo (2, ma poi il problema precedente non è brutto dato che il numero di annidamenti per linguaggi reali sta molto piccolo in generale, di solito 3).
Allora un modo per fare questo è tenersi un altro array, che contenga un puntatore a seconda del livello di annidamento!
Idea: tenersi una struttura ausiliaria che viene aggiornato ad ogni cambio di ambiente che contenga il puntatore alla struttura statica di riferimento a ogni livello. (chiaramente il livello massimo si annidamento, va a determinare la lunghezza del display).
Due accessi, uno nel display per trovare il RdA corretto, l’altro accesso per trovare l’index della variabile locale corretta.
Funzionamento generale
Sia m il livello di annidamento del chiamato, allora salvo il valore che c’era prima, perché il display sarà comune a tutti i livelli diversi da m.
Quando ritorno ripristino il vecchio valore, in questo senso il display contiene tutte le RdA statiche a seconda del livello di annidamento, e posso utilizzare questo per capire il puntatore di catena statica.
-
Esempio display
!
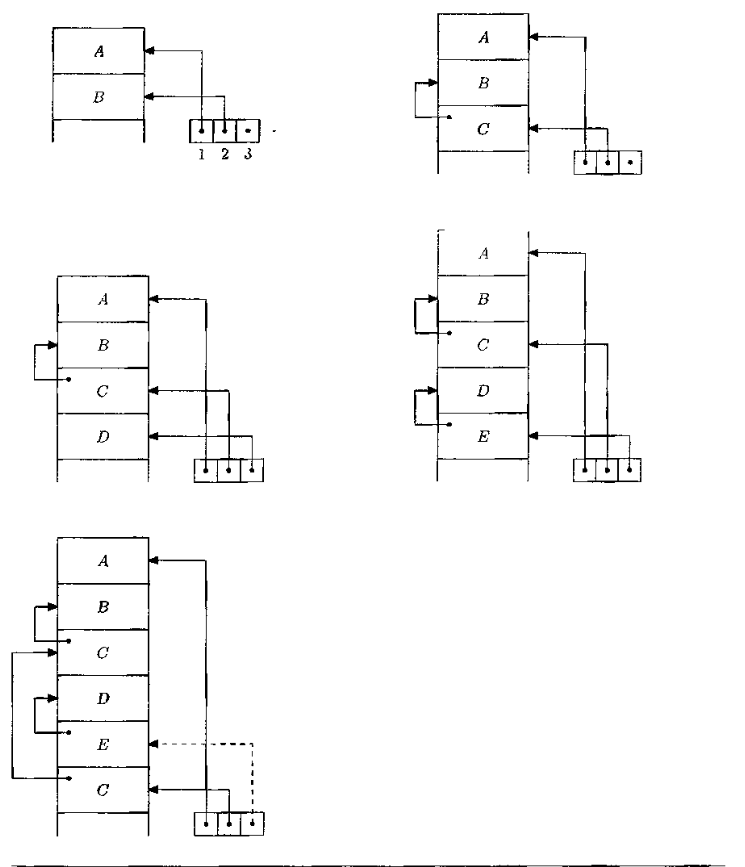
Figura 7.15 Display per la struttura di Figura 7.13 e la sequenza di chiamate A,' B, C, D, E, C.
Scope dinamico: La ricerca per nome
Questa è la soluzione più lenta che potrebbe esistere, che è quella della ricerca per nome negli RdA, in pratica risalgo i record fin quando non lo trovo o lo trovo.
Un problema diventa andare ad attivare o disattivare le variabili a seconda del fatto di averlo già visto o meno, e dello scope.
-
Slide descrive questo metodo
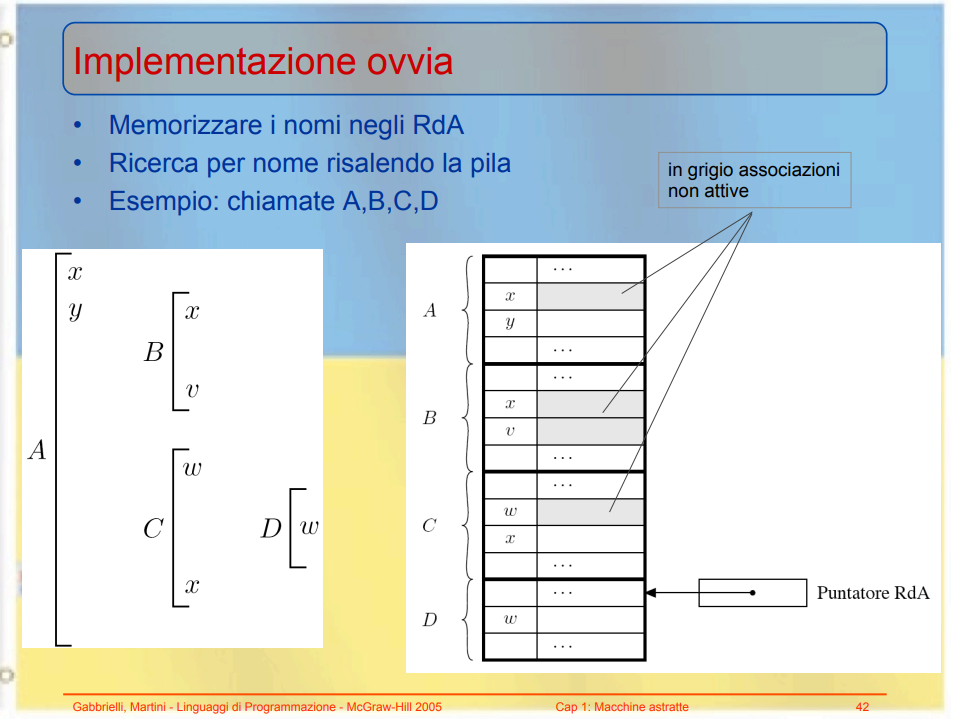
Scope dinamico lista associazioni
Una cosa banale è tenersi una lista di associazioni globale, chiamata A-list (che viene usato in lisp) che si tiene conto di tutte le associazioni attive. Un entrare e uscire da un certo ambiente non si tratta altro che andare a manipolare questa lista globale di associazioni.
Cercare un valore dell’associazione a runtime non sarebbe altro che andare a scorrersi la lista fino a trovare il simbolo di mio interesse, alla prima occorrenza, perché quella è la più recente.
Entro in nuovo ambiente non faccio altro che aggiungere nella A-list i valori locali
Esco dall’ambiente non faccio altro che poppare i valori locali
Ricerca simboli non faccio che scorrere tutta la A-list per trovare il valore corretto.
Chiaramente questo runtime non è che sia molto invitante (nella pratica però è sufficiente, anche se non avrei comunque una efficienza di C), quindi vorremmo trovare anche metodi migliori per implementare lo scope dinamico.
Un altro metodo comparabile per inefficienza è scorrersi le RdA finché non troviamo il simbolo di nostro interesse..
Svantaggi
- Devo memorizzare i nomi in momento di esecuzione, per poter ritrovare l’istanza.
- Lentezza ad accedere valori globali, che sono in cima alla lista.
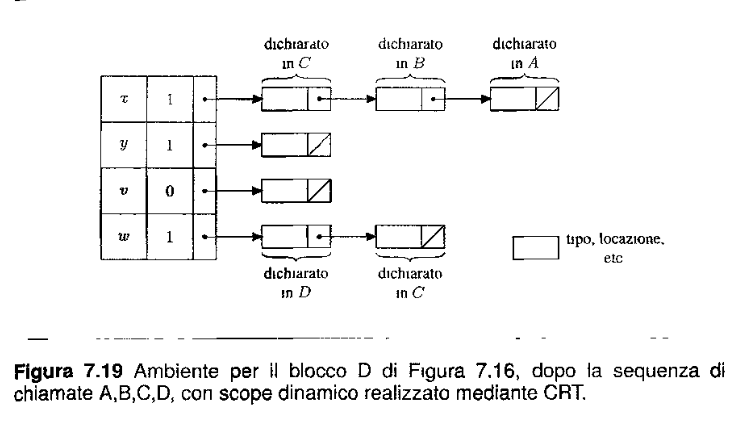
Entrambi questi svantaggi sono risolti con la CRT esposta nella squenza successiva.
Central Referencing environment Table
Durante l’esecuzione e durante le entrate in ogni ambiente locale, posso tenermi un array di tutti i simboli che posso avere (oppure una hastable). Questo mi permette di accedere al simbolo in tempo costante, e se a tempo di compilazione conosco tutte le variabili a mia disposizione, poi mi basta accedere con offset, e non mi serve sapere il nome originario! (se invece non è nota bisogna utilizzare la hastable).
In questo modo ho un leggere overhead in più per uscire ed entrare in un blocco. Perché devo aggiornare l’array globale di liste, però mi implementa in modo semplice questo scope dinamico.
Per tenere conto dei valori vecchi abbiamo principalmente due metodi:
- Tenersi la stack degli elementi nascosti che viene ripristinata quando usciamo dal blocco (quindi è temporaneo per tenere i vecchi valori)
- Lista dei vecchi valori, ossia ogni elemento si tiene una lista, che possiamo interpretarla come stack per ogni valore, che contiene i vecchi valori, in testa solamente il valore più recente.
-
Esempio stack elementi nascosti
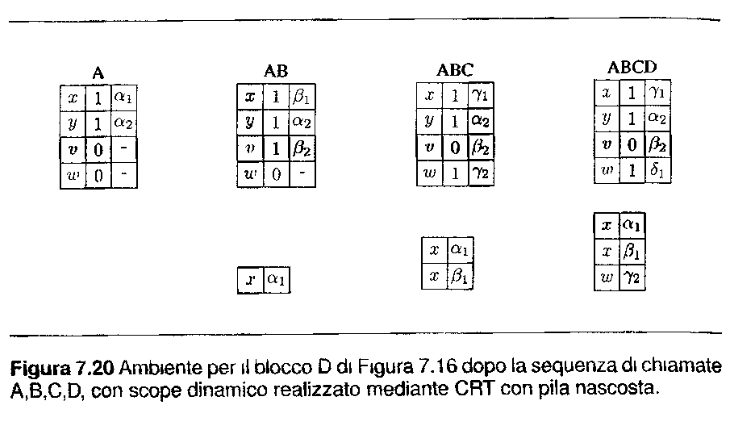
-
Esempio lista vecchi valori