Dependable systems
Introduzione
Possiamo individuare alcune proprietà dei sistemi distribuiti. Però non siamo riusciti a renderli logicamente validi. Sono ancora un pò misti di linguaggio naturale e della sua ambiguità! Comunque possiamo ridurci per guardare quanto un sistema sia affidabile a guardare poche sue caratteristiche precise.
Caratteristiche fondamentali (4)
Queste proprietà sono pensate naturalmente caratterizzanti dei sistemi. In particolare dovrebbero essere tutti misurabili.
Availability
Che risponde nell’istante in cui fai una richiesta.
Reliability
Reliable quando non crasha quando comincia a runnare.
Safety
Niente di catastrofico avviene, ossia qualcosa da cui non si può tornare indietro. Vorrei riuscire a riprendere l’esecuzione dopo i crash.
Maintanability
Quanto è facile risolvere i problemi quando succedono i problemi.
Faults
Definiamo concetti come errori, faults, system failure. Rispettivamente sono definiti come
- Errore: è uno stato del sistema che ha causato il comportamento inaspettato
- faults: cosa che ha causato lo stato d’errore.
- system failure: quando non si comporta come secondo le specifiche.
Noi vorremmo avere un modo per controllare i faults. Quindi sistemi che riescano a prevedere, rimuovere e prevenire faults.
Classificazione dei faults
-
Sorts of faults (tempo)


Obiettivi dei sistemi distribuiti
Possiamo andare ad individuare alcuni principi cardine nella costruzione dei sistemi distribuiti
Trasparenza
Vogliamo che la distanza fisica della locazione del server non sia percepibile, quindi l’esperienza del sistema distribuito sia come nascosto. Possiamo andare ad individuare molti (probabilmente troppe) tipologie di trasparenza, e non tutte possono essere facilmente garantite (non tutte poi dovrebbero essere garantite secondo me)

Openness
Per aprirsi alla non-predittibilità dell’ambiente in cui presente, il sistema deve essere in grado di cambiare componenti, accettarne dei nuovi, e sapere comunicare con questi. Per questo motivo chiamiamo un sistema distribuito OPEN.
Chiaramente un linguaggio comune per cui parlarsi deve esistere. Diventano quindi importanti le IDL (interface definition Languages) linguaggi nati proprio per definire solamente delle interfacce di comunicazione. (++ sijntassi del protocollo, un buon esempio può essere protobuf).

Scalabilità
Come può scalare il nostro sistema distribuito. Di solito può scalare verticalmente oppure orrizzontalmente. Per verticale diciamo comprare una macchina più potente. Per orizzontale diciamo comprare più macchine.
Un problema per la scalabilità, molto legata alla trasparenza è mascherare la latency di comunicazione.
Availability
Più o meno questo dovrebbe essere il vantaggio dei sistemi distribuiti, che essendo replicati, è molto probabile che siano tutti ON. Questo concetto dell’availability comunque racchiude il concetto di quanto spesso ti risponde alle tue richieste.
Tipologie di sistemi distribuiti
Distributed computing systems
Questi sono i sistemi principalmente devoti al calcolo scientifico. (Quindi utilizzo di protocolli come Beowulf, che permettono un calcolo molto veloce e coordinato in Rete LAN, utile a fare calcoli molto simili.
Queste cose si dividono in cluster, e grid. Il primo fa cose molto simili fra di loro. Il secondo può fare anche cose diverse (mi pare, non ne sono sicuro).
Il cluster possiede stesso sistema operativo e sono solitamente messi nella stessa zona, collegati a una LAN molto veloce. Di solito è questo il modo con cui si costruisce un supercomputer, perché è la cosa più economica ammassare tanti computer insieme che lavorino bene per avere potenza di calcolo superiore.
-
Esempio cluster beowulf
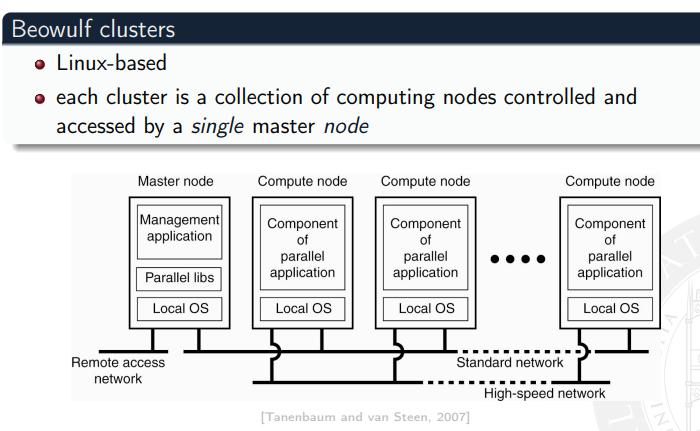
Invece i Grid sono utili per connettere aree amministrative diverse. Quindi boh… Forse connessione fra uni diverse, filesystem condiviso?? buo.
Distributed information systems
Storicamente è stato presente un fortissimo bisogno di coordinare i basi di dati di dipartimenti anche molto diversi affinché non ci sia una ripetizione inutile di dati che possa andare a causare una burocrazia molto elevata. C’è stato quindi bisogno di creare un sistema di middleware condiviso a tutti i basi di dati che provava a rendere consistente tutte le basi di dati diverse.
Pervasive systems
Attualmente tutte le persone possiedono dispositivi di calcolo, quindi è importante dare risalto anche a questo modello di sistema distribuito.
Principalmente i metodi per questa parte la dividiamo in 2 parti:
- Sensori che inviano costantemente dati (overhead network e il server che li deve processare)
- Sensori che hanno un processore locale, e dati locale, che rispondono in modo coerente (come se fossere un unico sistema) quando sono chiesti da una query
Paxos
Paxos è un protocollo utile per risolvere il problema di Bizantine agreement, creato da Lamport nel 1998. per BA guardare Syncronous model.
L’idea è dividire il processo di agreement in due fasi. Una priomise e un commit.
Poi andiamo a definire alcuni agenti principali in questo protocollo. Dei proposers,acceptors, quorum.** I primi propongono, gli altri accettano. Quando è stato raggiunto un quorum, allora si va alla seconda fase, quella di commit o accettazione, se è rifiutato si torna a prima, altrimenti si va al commit. Può esserci livelock?