Un pò di storia
È importante capire un pò di storia per vedere che strano robo abbiamo oggi. Due linee di sviluppo, uno è uno standard di W3C, l’altro è il living standard. È di fortissimo cambiamento, quindi di difficile definizione! (cambia significato sia di semantica e che di sintassi).
Nel 1997 abbiamo HTML4 che è stata considerata la versione finale, per cui un sacchissimo di siti web fino al 2008 sono stati implementato con questo HTML
Tag Soup
I browser permettono molti tag, senza voler dare errore con l’obiettivo di essere comprensivi. Abbiamo quindi un sacco di tags, molti dei quali non sono conformi a nessuno standard. Non abbiamo una correttezza sintattica o semantica dei tags. Abbiamo in pratica troppe eccezioni. Solitamente si è strict quando si scrive e permissivi quando si legge.
Il problema allora diventa, quando vogliamo andare a creare un parser per questo genere di html, come andare a crearne uno che riesca a gestire queste tipologie di tags?
-
Slide quirks and strict mode

In particolare abbiamo con HTML5 una standarizzazione delle regole di parsing quindi possiamo andare ad utilizzare lo strict mode e avere più garanzie sulle pagine.
XHTML e HTML
Le aziende dei webbrowser avevano già il codice per parsare il HTML brutto, con molti codici, e non volevano creare un nuovo parse per XHTML, molto più formale e che riusciva a garantire più codice (ossia ci sarebbe un modo unico per scrivere del codice corretto!). L’hanno proposto ai tizi del W3C che l’hanno rifiutato. Così è stato creato il working group WHATWG in cui si lavorò a una versione intermedia di HTML, che estese con alcuni tag. Dentro questo gruppo erano già presenti i maggiori player per i browser come mozilla, microsoft, e poi ci è entrato Google assumendo Ian per la creazione di chrome.
In questo moto ha vinto HTML5, che viene chiamato solamente HTML e un living standard che viene aggiornato ogni poche settimane.
Questo albero che viene creato dal parsing di quel modello è utile per la creazione del DOM trattato più sotto.
HTML
Struttura del documento
Ci deve essere una intestazione DOCTYPE che ci specifica che tipologia di documento stiamo andando a parsare (se non c’è credo sarebbe sintatticamente invalido ma ciononostante il browser è in grato di inferire come intenderlo!)
-
html che include tutto
-
head che include informazioni generali sul documento
-
body che contiene il contenuto del sito.
-
Esempio di file HTML

<!DOCTYPE html> <html> <head> <title> Document title </title> </head> <body> <h1> Major Header </h1> <p>This is a complete paragraph of a document. I write and write until I fill in several lines, since I want to see how it wraps automatically. Surely not a very exciting document.</p> <p>Did you expect <b>poetry</b>?</p> <p>Here you can see a paragraph <br> split by a <br></p> <hr> <p> A list of important things to remember: </p> <ul> <li>Spaces, tabs and returns</li> <li>Document type declaration</li> <li>Document structure</li> <li>Nesting and closing tags</li> </ul> </body> </html>
Elementi inline
Molti sono stati deprecati (o non li usa nessuno), perché dovrebbero essere usati CSS per la parte grafica. Solo i, e B sono ancora presenti, o small, perché sono caratteri tipografici molto comuni!
-
Esempi di elementi inline

Elementi di blocco e di lista
Sono i blocchi classici per rappresentare struttura di headers, di paragrafi, e blocchi generici, o citazoini, autori.
Blocchi seguono una sequenza di lettura fra le letture!
esempio:
- div>, un elemento anonimo, che deve essere totalmente stilato.
- span>, la stessa coda del div, che però non è blocco ma INLINE.
- h1>, h2> …, h6> etc
NOTA: whitespace è praticamente sempre ignorato, tranne all’interno del tag pre. (esiste white-space: pre, che permette di utilizzare whitespaces
-
Slide

-
Esempio

Elementi di lista
-
Slide

-
Esempio elementi lista


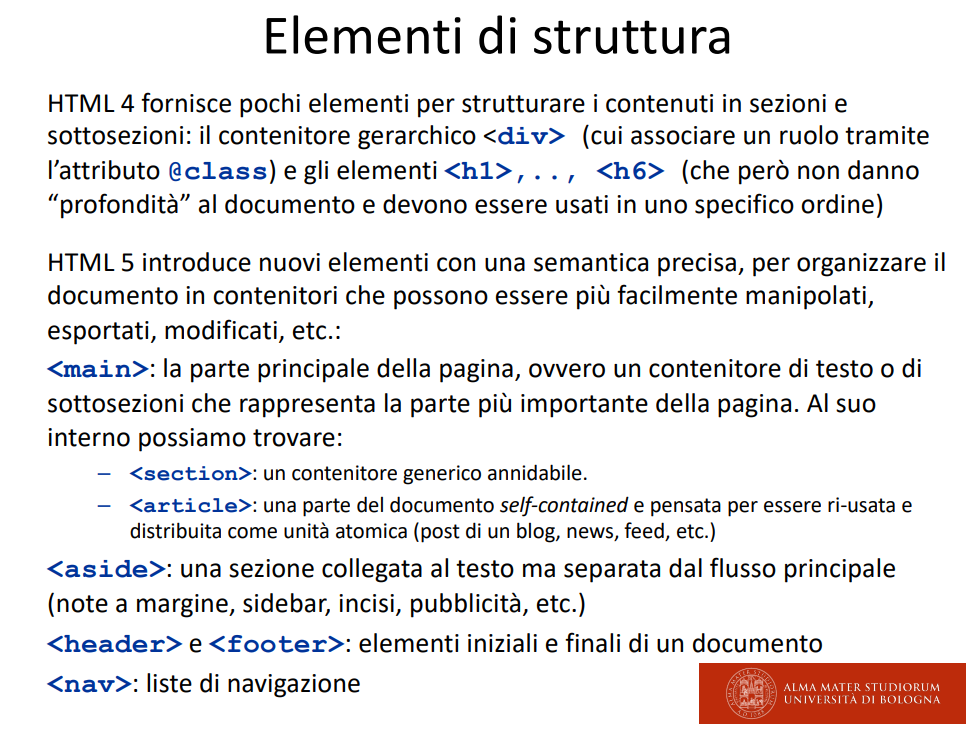
Elementi di struttura
Non vorremmo avere dei div come elementi di struttura, questo non è che sia molto chiaro dal punto di vista semantico!
Quindi introduciamo
-
section> che descrive un qualcosa di annidabile
-
article> che prende qualcosa di self-contained che può essere utilizzato a sé, e quindi potrei rimuoverla o inserirla senza problemi!
-
Slide tags struttura
-
Slide header e footer

-
Slide nav

-
Esempio confronto HTML 4 / HTML5


Anchors and images
Anchors
Posso metterci un fragment per gli a, questo non camibano niente nella transazione client e server, ma è il browser che capisce la locazione dopo aver scaricato tutto.
Si noti che l’attributo name non cambia la visuale del blocco, a differenza di href (che manda fuori).
-
Slide anchors

Immagini
Ha ancora degli attributi altezza e witdt, che rimangono ancora nonostante siano attributi rappresentazionali. Però precalcola l’occupazione dell’immagine e quindi il tutto carica più in fretta.
-
Slide immagini

Potrei includerla con una immagine, e specificare height o width (se li includo entrambi avrò resize dell’immagine senza rispettare le proporzioni, se non metto niente avrei l’immagine di grandezza naturale (px original) altrimenti se ne metto sono una avrò una resize che mantenga le dimensioni iniziali).
srcset, vogliamo avere tantissime immagini, che si scalino in modo automatico aseconda del device, definisco srcset e delle sizes.
-
Slide srcset

**figure **è un tag con un caption in pratica, niente di che…
Form
esistono da sempre, quindi già dall’inizio sembrava che fossero utili per fare applicazioni con un rapporto in clientside.
Creare una schermata per specificare i dati da passare a una applicazione server-side, per creare punti di raccolta di informazioni, e fare un submit all’applicazione server side, chiamata ACTION, .
-
Slide struttura di un form

Solitamente i metodi sono GET o POST, ma vedremo dopo con HTTP questa differenza.
I widget sono le cose visibili nel form, come **textarea, radio,, input select, *button.
-
Interactive forms

-
New input forms

Tags generali
Embedding
object è un tag per oggetti che non sono capibili dal browser naturalmente, infatti bisogna specificare un engine con cui runnarlo.
Questo è un embedding molto, troppo generale, quindi vogliamo creare i tags per embedding specifici, che rende il tutto più chiaro.
-
Slide per tags di embedding

Tabelle
Cose come th per dire table header, or tr per dire table row., td per dire table data., e table per inizializzare le table
Solitamente è composta da tre parti. head, foot, e body, solitamente per questioni di efficienza foot deve essere messo subito dopo le head, perché ha i numeri più grandi, quindi non devo andare a ricalcolare la grandezza della tabella.
Una altra cosa interessante per le tabelle è che ci sono stiling come attributi (esempio di questo sono colspan, rowspan etc), ma dovrebbe essere di CSS, infatti questo era un modo per farlo prima di CSS.3.
Tipicamente utilizare le tabelle per fare layout è una delle cose meno accessibili che esistono! Quindi non ha più nessun senso utilizzare le tabelle di layout. (non utilizzarle, penalizza!).
DOM
Questa parte è fatta meglio in Javascript
Document object model, l’obiettivo della WHATWG era costruire un parser che potesse aiutare a creare una struttura di dati utile per la creazione di applicazioni, quindi molto più tollerante rispetto a quanto proposto dal W3C e specifiche più rigide come XHTML.
Document Object Model, una struttura di dati con alcune funzioni e strutture built in che permettono la facile manipolazione fornisce API. Dovrebbe essere facile creare un DOM da codice HTML così come il constrario. È esattamente quello che si vede sullo schermo!
“l’importante è arrivare ad una struttura dati in memoria unica su cui costruire applicazioni
Dato che deve funzionare per HTML secondo la filosofia più estesa del WHATWG, è praticamente la struttura del XHTML ampliata per includere altro, questo permette al codice JS di intervenire direttamente sul DOM.
Struttura del DOM
-
Slide struttura del dom
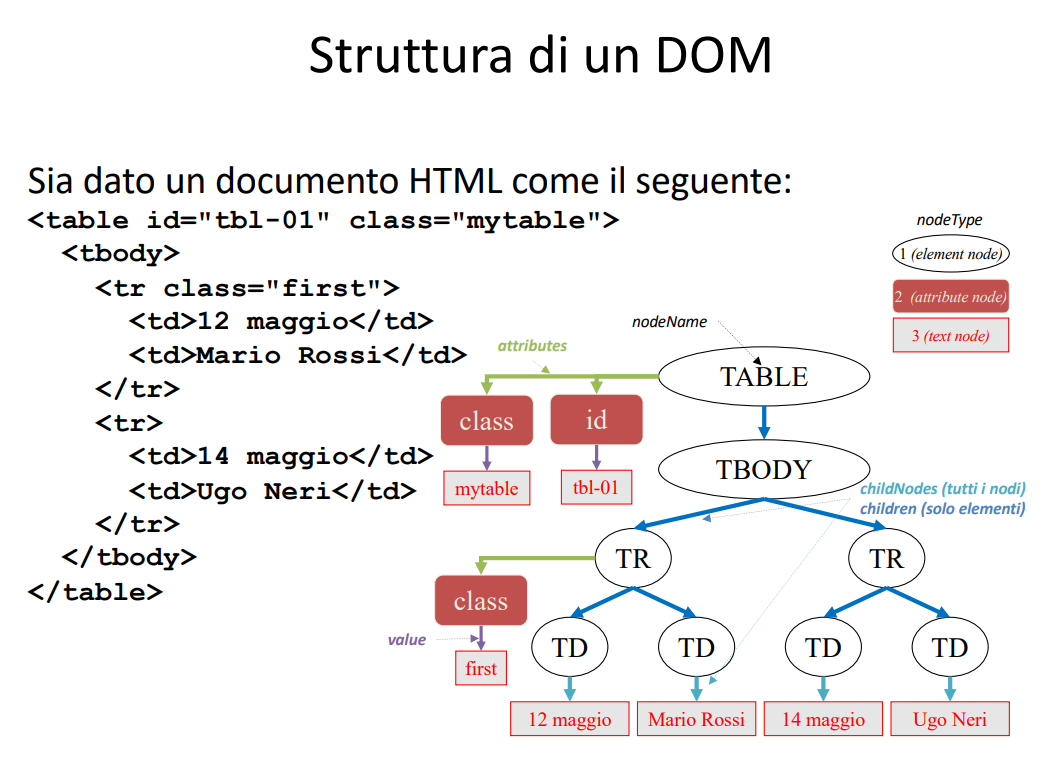
Ci sono alcune classi fondamentali per poter comprendere il DOM
- Documento
- Nodo del DOM
- Nodo di testo
- Nodo di elemento
- Nodo di attributo
- Poi ci sono molte altre classi, come commendi, Datasection e molti altri che di solito si vedono poco, quelli più importanti sono il Document e i nodi descritti sopra
Alcune classi del dom
-
Slide DOMNode

-
Slide DOMDocument e Selettori

Solitamente è complicato lavorare col DOM vanilla, tanto che l’hanno chiamato sadico chi ne è stato detrattore.

-
Slide DOMElement

Inner e OuterHTML
Andare a modificare l’HTML è molto verboso, utilizzando questi metodi è più veloce andare a creare nuovi elementi.
L’unica differenza fra i due è che Outer include anche il contenitore nella modifica, inner è solo per il contenuto
-
Slide Inner e OuterHTML

Altre note
Whitespaces in HTML
- Whitespace è ignorato (soprattutto in elementi strutturali come i table)
- Whitespace è collassato in un unico whitespace
- in pre> il whitespace è mantenuto.