Indexes
Trattiamo qui di alcuni metodi che sono utilizzati per costruire indici
Introduction to indexes
Gli indici sono una struttura di dati aggiuntiva che ci permette di ricercare più in fretta alcuni valori per le queries. In questa sezione proviamo ad approfondire in che modo possono essere costruite e gestite.
Search keys
Sono in breve la cosa che vogliamo andare a cercare. Solitamente sono nella forma <key, label>, che ci permette di trovare in fretta il label, che si potrebbe intendere come il valore che noi stiamo provando a cercare.
Labels and record identifiers (3)
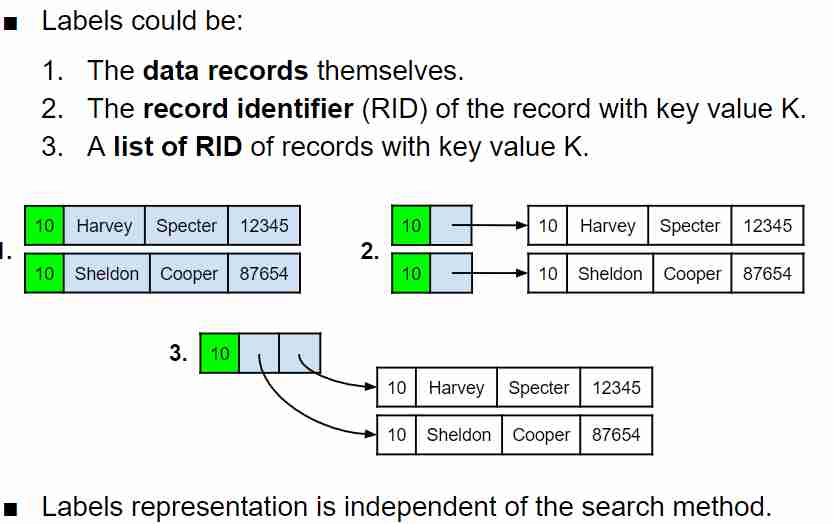
Primary vs secondary indexes
 È primary se gli attributi che vengono guardati contengono la chiave primaria della relazione
Altrimenti è secondary
È primary se gli attributi che vengono guardati contengono la chiave primaria della relazione
Altrimenti è secondary
Dense vs sparse indexes
Dense se per ogni chiave del file esiste una chiave di ricerca. Altrimenti è sparsa. Chiaramente per index sparsi abbiamo bisogno di meno spazio per storarli in memoria!
Clustered vs unclustered indexes
Clustered se viene utilizzato l’ordine dei labels (eh, non ho capito questo criterio credo.)
Chiaramente se è unclustered non abbiamo più i vantaggi della cache, e quindi è più lento accedere!
Sequential Index example
In pratica dividiamo il file in molti pezzi contigui, e proviamo ad indexarli in modo contiguo, come in figura: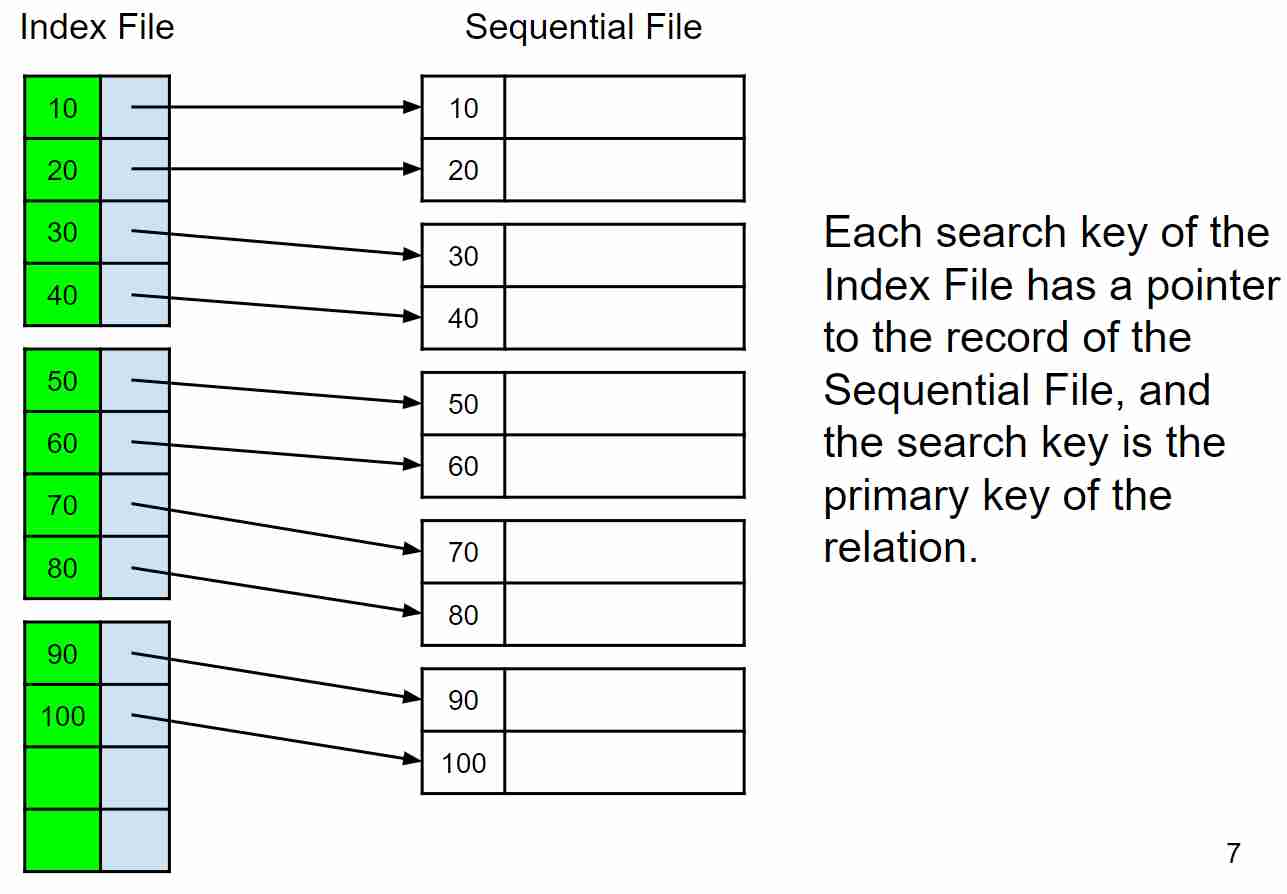 Questo metodo è denso e clustered per fare indexing, mentre per il fatto che sia primario o meno dipende!?
Questo metodo è denso e clustered per fare indexing, mentre per il fatto che sia primario o meno dipende!?
B-trees
La differenza fra B-trees e B+-trees è che il primo può tenere valori anche nei nodi intermedi, mentre il secondo tiene valori solamente nelle foglie.
Abbiamo circa 40ms per l’accesso al blocco, solitamente di tipo 4k bytes. La osservazione principale è che gli algoritmi non lavorano più in RAM, che è facile accedere subito (nanosecondi ad accedere), quindi è più facile fare algoritmi che tengano in conto questa cosa.. La base di dati ha bisogno di indici, perché in questo modo utilizzo permette il miglior accesso
- un index è interamente di grandezza del blocco. Dipendente da chiavi valori. Un indice un singolo blocco diciamo (quindi abbiamo centinaia di archi) (il costo è $\log_{n}(N)$) con $n$ il branching factor.
- Con pochi livelli, posso accedere a molte cose! (quindi faccio pochi seek per raggiungere i valori).
B-trees
Nodi interi e nodi foglia
Abbiamo che è un albero con più rami, solitamente largo per non necessitare di più letture per andare a leggere (ricorda che ram è circa un milione di volte più veloce!). Praticamente
Insertion and deletion
Quando ho trovato il nodo in cui inserire, e trovando che il nodo è pieno, dovrei provare a spezzare, e creare un nuovo nodo genitore e c’è lo stesso il processo ricorsivo anche sul genitore, se non c’è spazio continuo a dividere (anche la radice si può splittare). Vedi slide 30 Lab06 Per la deletion la slide è 39.
C’è un fattore di riempimento che si dovrebbe andare a considerare, per capire se posso fondere più nodi assieme, in modo che non debbano prendere troppo spazio.
Come in immagine:
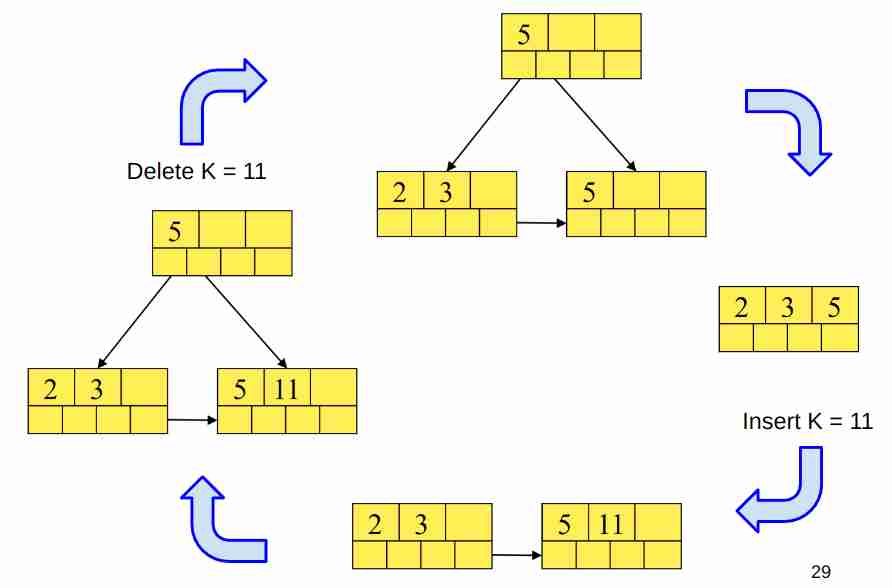
L’algoritmo è molto chiaro se visto con le immagini e gli steps, poi in questa occasione non ci interessa analizzarlo.
Notare: questa è una implementazione un po’ meno efficiente perché i valori effettivi possono essere presenti solamente sulle foglie, sarebbe più efficiente se si vede che in un nodo intermedio il valore esiste allora esisterà anche sulle foglie per cui si può già restituire il risultato. Questo applicativo ha una versione più efficiente: https://www.cs.usfca.edu/~galles/visualization/BTree.html.
Hashes
Gli hash sono utili per la ricerca di chiavi uguali tipo per indici oppure per database piccoli (credo) che non hanno bisogno di b-trees.
Static Hash
Per questa tipologia di hash allochiamo uno spazio fisso non estensibile. Data una certa chiave di ricerca, andiamo a prendere il bucket con quel valore. Se è già pieno si possono usare linked list o alberi per memorizzare il valore.
Anche in questo caso, come per i B-trees, si invita a guardare le slides, oppure disegnare per una comprensione migliore dell’argomento.
Extensive hash
Elementi di rilievo:
- Ogni singolo blocco ha un contatore che indica il numero di bits utilizzati per indexarlo.
- Abbiamo un blocco intermedio di puntatori che vanno sui singolo blocchi di dati, contiene anche un dato che indica numero di bits per indexare il singolo bucket.
L’algoritmo di insertion è un po’ più complicato, e differenzia caso in cui il numero di bit per indexare il blocco sia uguale o minore rispetto a quello per i bucket. Anche in questo caso dovresti descrivere l’esecuzione dell’algoritmo con immagini, aiuta molto.
L’unica cosa negativa è il fatto di crescere in modo esponenziale per lo spazio nelle directories in casi proprio avversariali (o comunque molto difficili con una distribuzione normale diciamo).
Linear Hash
In questo caso cresce un blocco alla volta, finché un certo threshold di record/numbero di buckets viene soddisfatto si resta, altrimenti prova a crescere. Anche in questo caso come static hash, usiamo gli overflow blocks.
Inverted indexes
introduzione sul funzionamento
Per gestire cose come testo a volte può risultare utile fare questo genere di index per trovarlo. In pratica, supponiamo di avere n indici, allora possiamo fare una tabella nella forma
Parola -> Doc(posizione) In pratica, se ho un match per ogni singola parola con il documento e la posizione all’interno del documento che la parola ha, in questo modo posso fare ricerca veloce nelle posizioni in cui la parola compare.
Quando cerco una stringa esatta posso prendere l’intersezione fra i documenti in cui compaiono e restituire solamente quelle
Linguistic preprocessing
Sono metodi per diminuire la varietà delle parole in modo che io abbia bisogno di meno spazio poi per memorizzare l’inverted index. Posso fare cose come
Stemming: in cui rimuovo lo stemdella parole, quindi suffissi o prefissi ricorrenti Normalization: ad esempio metto tutto minuscolo. Rimozione stop worlds: perché sono inutili ché non danno molte informazioni