We have a classical exploration-exploitation tradeoff, see Reinforcement Learning, a introduction. Why would animals explore, even if there is no immediate reward based on it? Animals are able to adapt and explore nonetheless. It would be thus nice to understand and implement these features in artificial systems. We will attack this from an evolutionary psychology perspective: Playfulness and intrinsic motivation.
Curiosity
Here we will talk about why animals are pushed to explore.
Intrinsic motivation
One of the classical books about the topic is White, Robert W. “Motivation reconsidered: The concept of competence.” Psychological review 66.5 (1959): 297.
Three main motives
We want to understand why animals explore (why visiting new places or learning new things brings this small bump of joy? Why would you want to know more things, in the moment it is difficult that it has some reward). and activity and manipulation, for example going to jog and swim, which is costly activity but useless. Or running wheel mouse as another example, or playing with music and games (manipulation), and they feel pleasure by doing these activities.
We will focus mainly on curiosity (exploration) and playfulness (manipulation and activity)
Frameworks for Curiosity
Q-Learning
See Tabular Reinforcement Learning#Q Learning. We have states-action-value function, and have an update rule for a specific action at a specific state. Usually the error is off-policy, which is usually learnt from a database of experiences, so not updated from
The optimal policy can always be retrieved, and it will be an indicator function for the correct action at a certain state.
The bads:
- World knowledge, gathered through experience, is not utilized to guide exploration (more so with 𝜖-greedy SARSA).
- More explored state-action paths are not less favored for exploration (even under softmax), meaning we are not exploring enough.
This leads to idea like exploration bonus to balance the exploration, akin to some Rmax algorithm we studied in Tabular Reinforcement Learning.
SARSA
See Tabular Reinforcement Learning#SARSA. It’s basically the same as q-learning, but it is epsilon-greedy, it has some random exploration with some probability. And it is on-policy since we are using the action based on the policy
K-armed bandit
See Reinforcement Learning, a introduction, where we have a very small explanation of this problem.
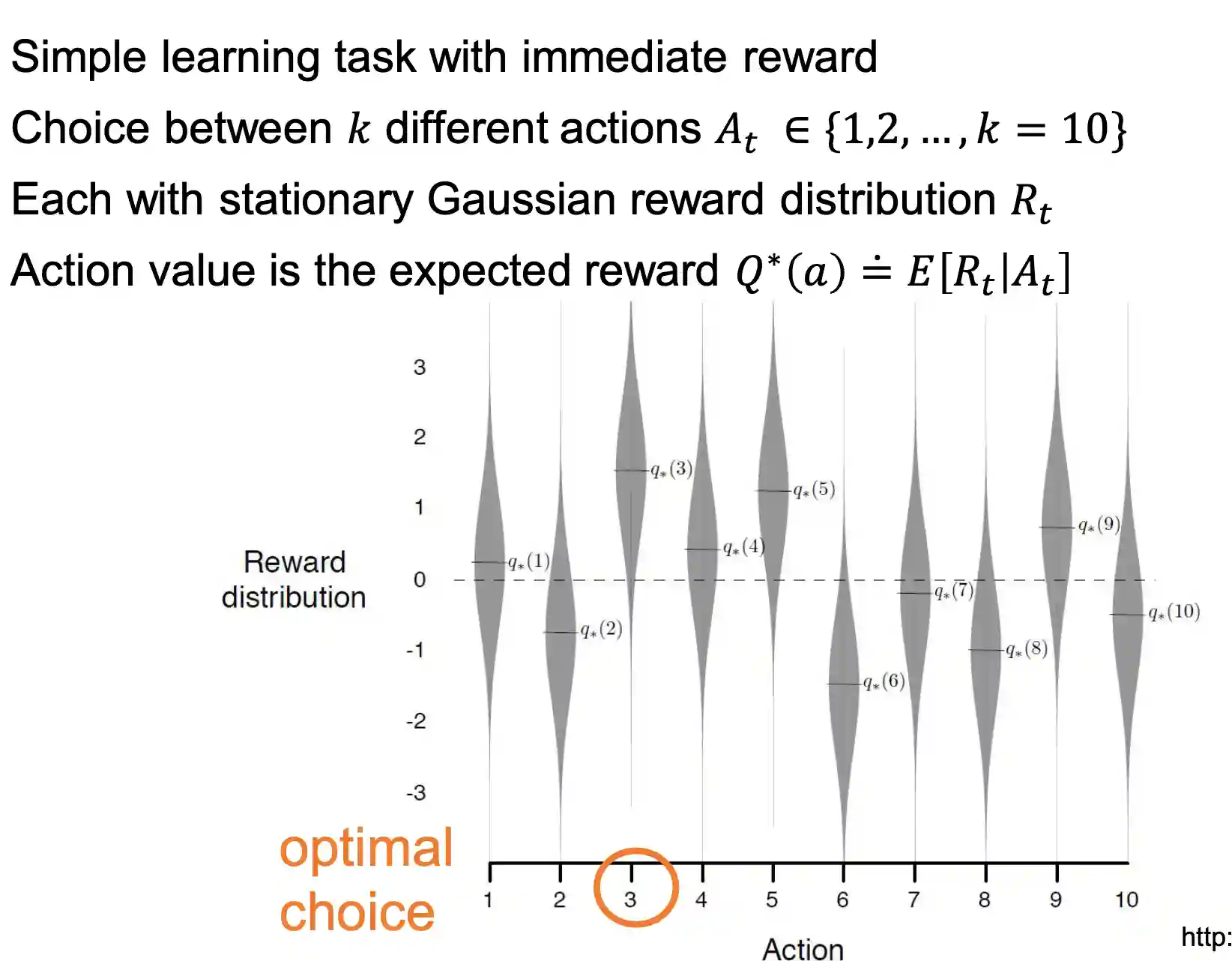
We have tradeoffs between explorations and exploitation!
Epsilon greedy exploration
Convergence for larger 𝜖 is faster, but leads to smaller average reward in the long run due to continuous exploration after convergence. Greedy action selection increases rapidly but often does not converge
Idea for improvement: make $\varepsilon$ adaptable (anneal it to zero), but it is difficult to tune. A better idea is the following section, the softmax exploration
Softmax exploration
We are using a softmax function to know which state to explore. See Tabular Reinforcement Learning. And we have a parameter $\beta$ or a temperature parameter $\tau$ to control the exploration exploitation tradeoff.
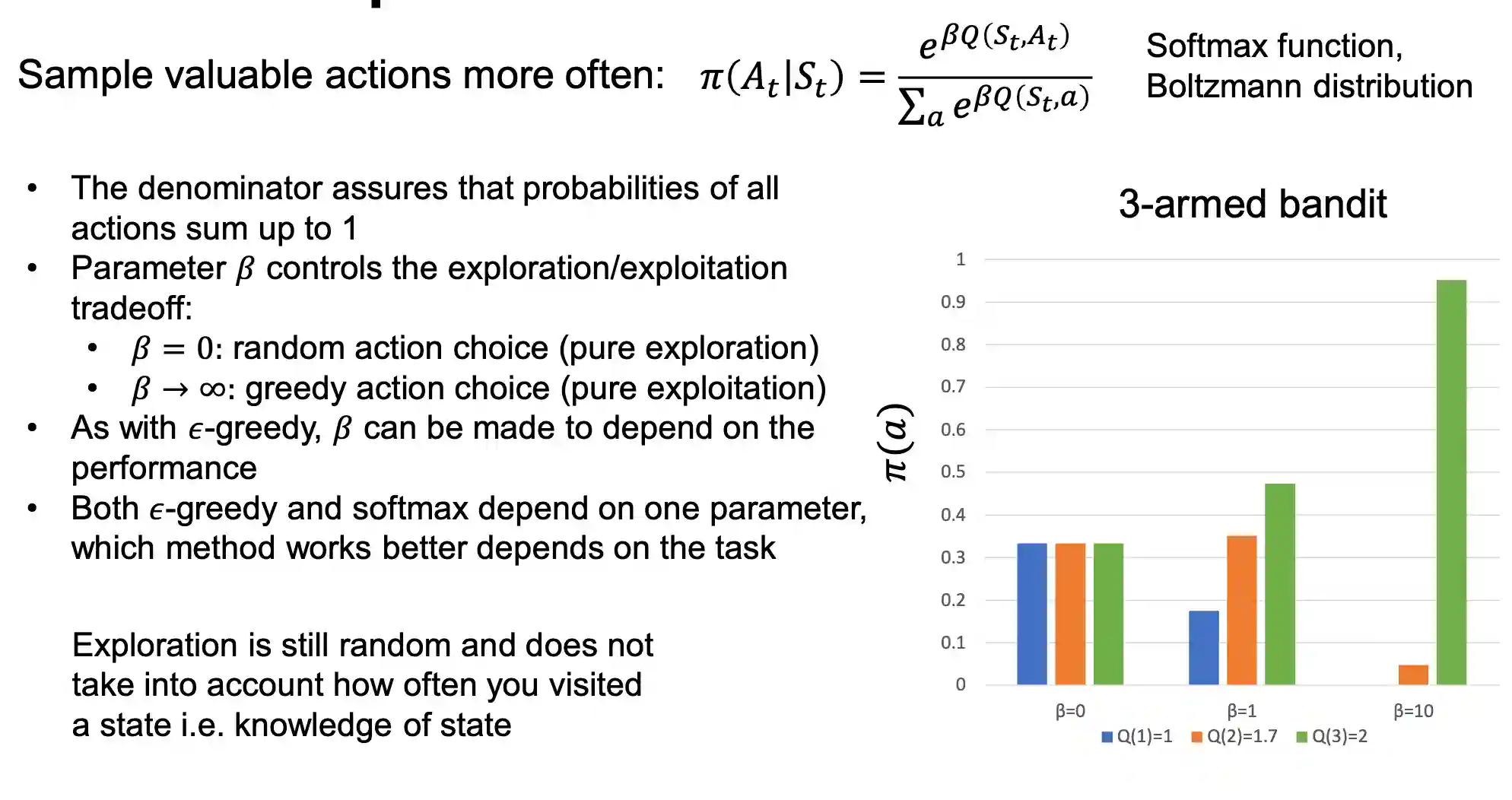
This is the most used technique now in this subfield. This doesn’t take into account the cues of the environment. It’s bad to do again a bad action just because the temperature is high for example. If the state has been visited often, we would like that to be more stable and less “hot”.
Exploration Bonus with uncertainty
The idea is to add a bias for exploration, based on the variance of the function!
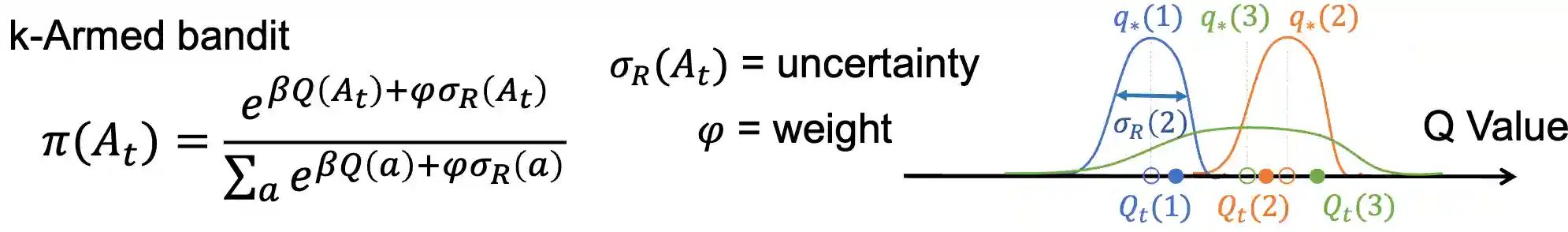
The problem is that we are attracted by randomness. We don’t want to be attracted by randomness, if it’s just noise, its not so interesting.
Counters for exploration bonus
Counters can solve this problem, to bias towards rare state action pairs. But in high dimensional spaces, this is very inefficient. Another drawback is that we are using only the immediate value but not the future values, so it is very much shortsighted measure.
Exploration Values
One idea is to introduce exploration values, like Q values in SARSA but without rewards. We assume new states have a very good reward, like 1, and update each state with the new real reward. This can act as a counter. See Tabular Reinforcement Learning, this is very close to RMAX.
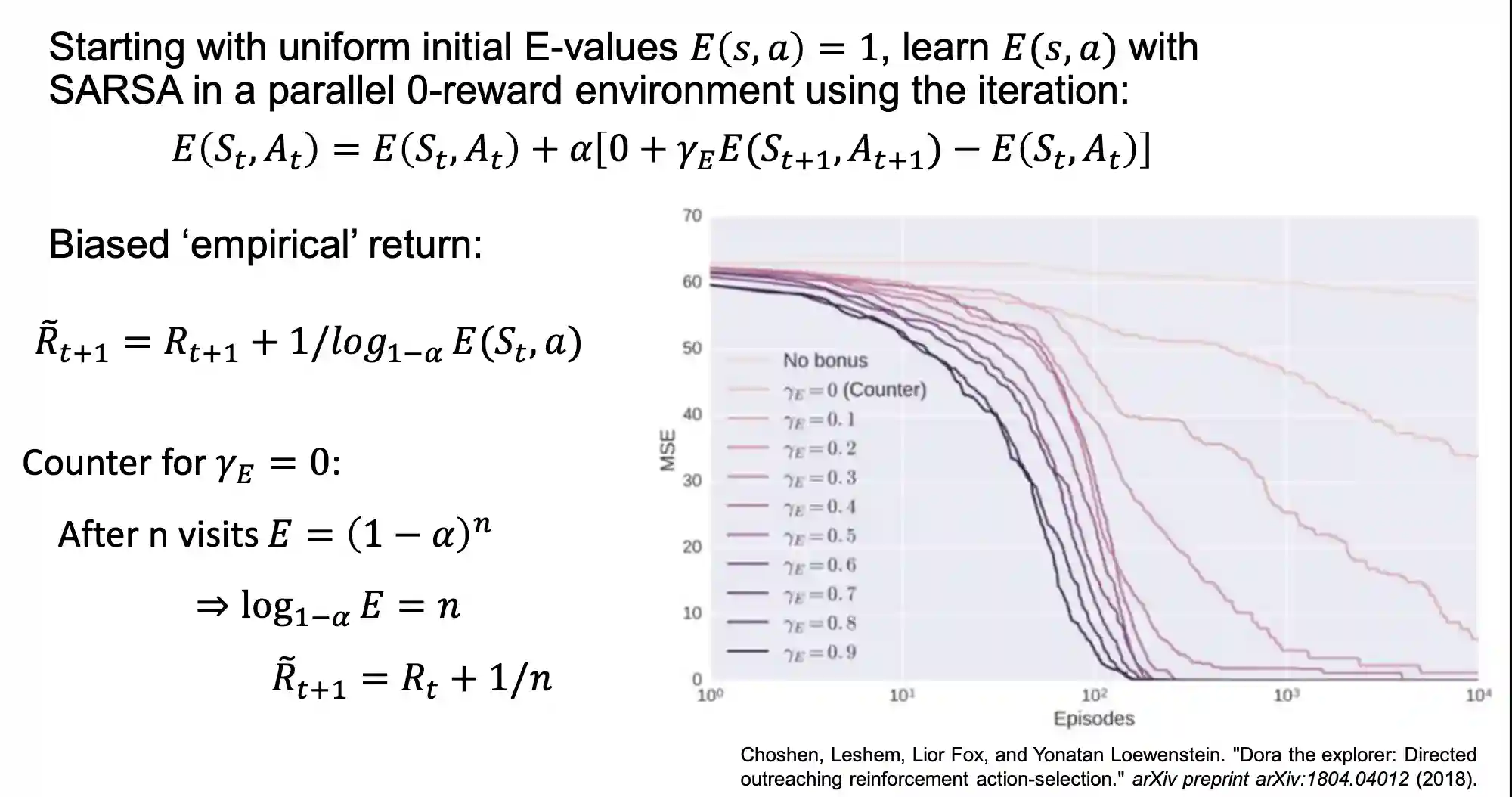 The more times we visit, the less the reward will be, in this way it acts as a counter.
This is some sort of generalized counter.
The more times we visit, the less the reward will be, in this way it acts as a counter.
This is some sort of generalized counter.
The problem is that some problems are not yet solved by these algorithm because their reward is very sparse, or a lot of noise.
Forward-Inverse Models
“Define the intrinsic reward in proportion to the error made by the agent in predicting the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model.”
We want to predict the parts of the environment that are caused by our agent. We want to work with the transformation of the sensory states.
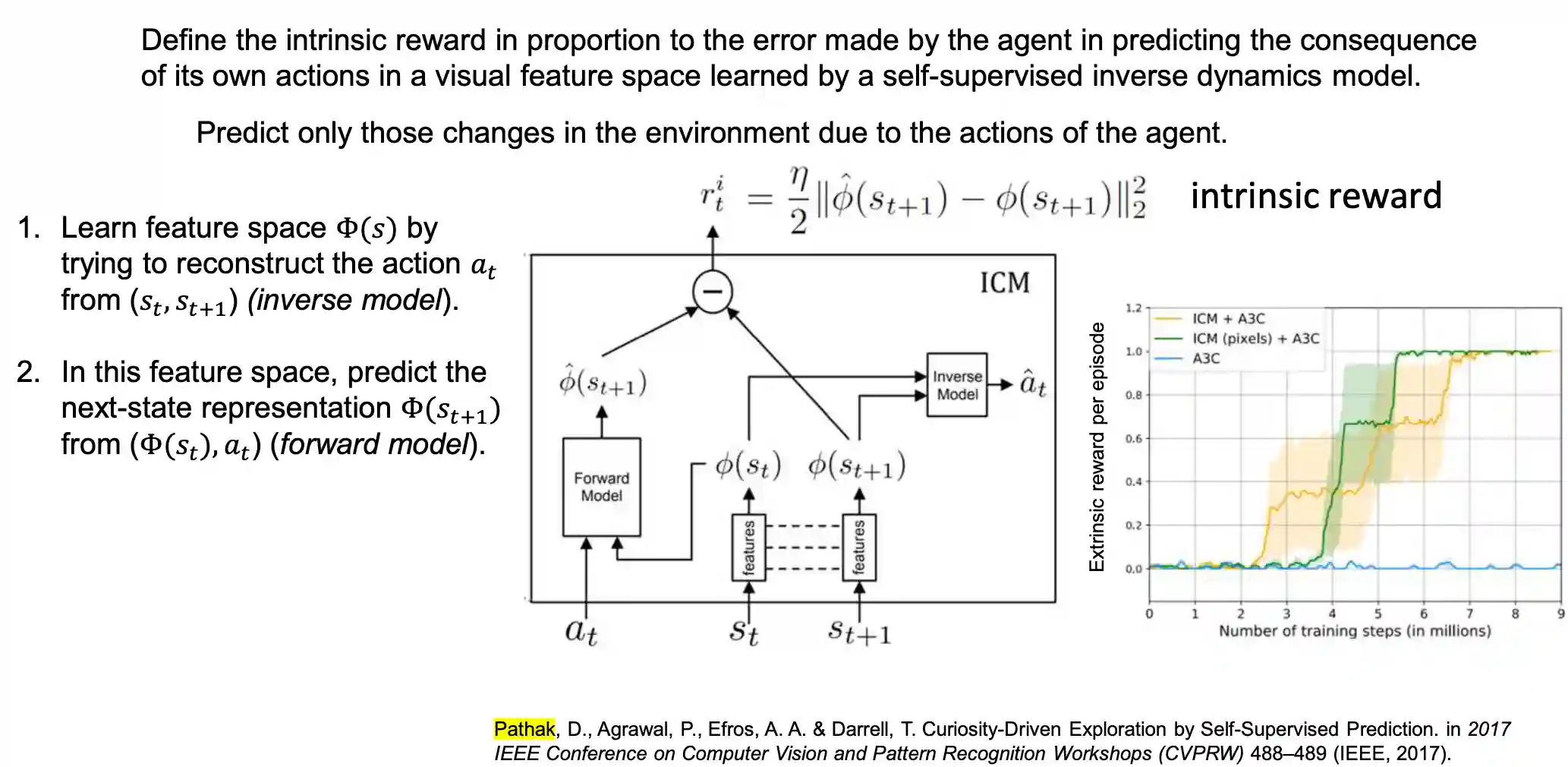
The intrinsic reward is the difference of the predicted features and the actual features. Bigger difference means bigger surprise. The idea is to try to build features that are only relevant to your action. So for the first time it was able to play games with lots of noise.
One drawback is that it leads the agent to be interested in the noisy TV problem.
Playfulness
Difference with Curiosity
How can we distinguish manipulation seeking and knowledge seeking behaviours? Manipulation can be used as the discriminator for usefulness against the noisy TV problem.
One fundamental difference is that curiosity is consumed, playfulness is not.
For example consider sensory substitution.
Sensory substitution
Image to sound for the blind. But people hate this sensory substitution:
- A lot of training to learn this
- They use a lot of auditory information to orient themselves, and this adds a lot of noise.
A better device is a vibratory device on the skin, but it takes still a lot of effort. One interesting thing happens for the birds see Birdsong and Song System. Singing towards a female makes them more stereotyped (female is exploiting, else they would explore more). Same thing for humans, when they get older they explore a lot less.
Light substitution in Zebra finches
Hearing birds can learn when the light is off. Deaf birds follow the light, they but I did not understand this part… They can learn by light. They adapt very fast to light stimuli. These birds don’t know what they are producing, but they can get light feedback into them. This experiment is about whether if Zebra finches can learn just by feedback of light, when they are deaf.
Time of adaptation in Zebra finches
They can learn to change the pitch very precisely. They learn faster when they are deaf. But their feedback must be reliable! They prefer reliable feedback but low signal against noisy feedback. No reinforcement learning can cleanly explain this.
A model for sensorimotor behaviour of birds
The model must be reliable, we studied something very similar in Conditioning Theory. If not, the association is not so strong.
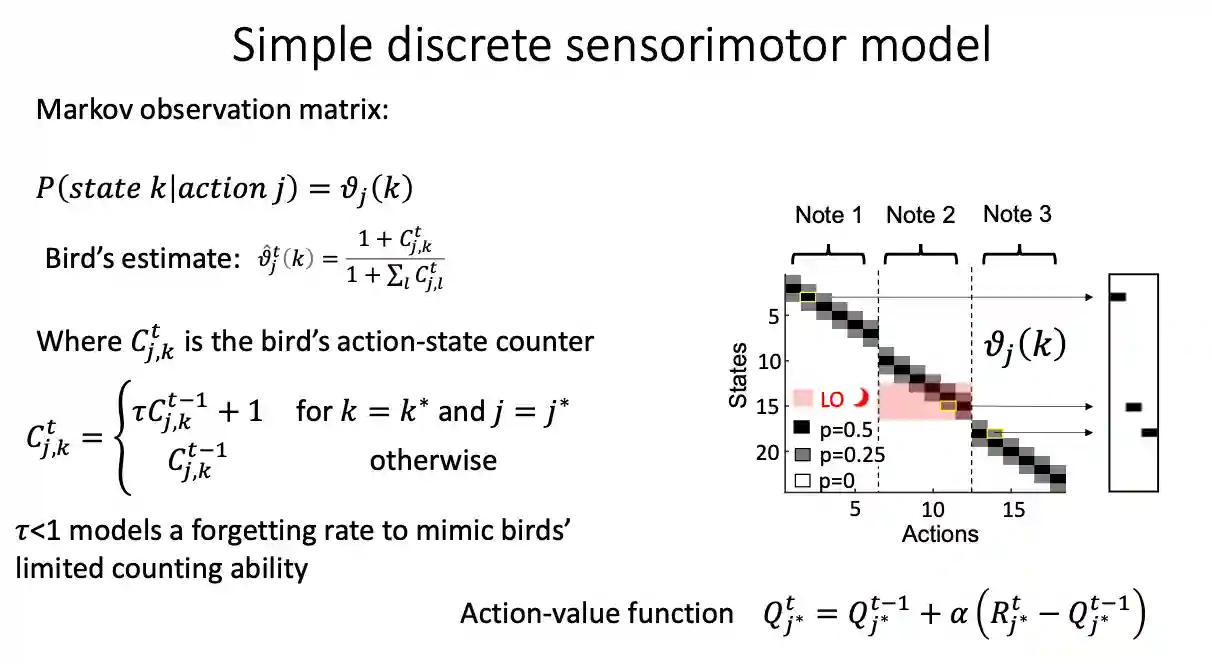 $$
R_{j}^{t} = E_{j}^{T} + M_{j}^{T} + r_{j}
$$
$$
R_{j}^{t} = E_{j}^{T} + M_{j}^{T} + r_{j}
$$Where $r_{J}$ is some intrinsic punishment. They maximize by choosing some light off things.
Pitch Contingent Singing
Birds like to sing if it is correlated to their pitch, if its random they don’t like to sing (leading to the empowerment theory). Meaning empowerment is linked to sensory substitution. They actually need to be able to act and modify on that.
Empowerment
$$ E = C(p(s_{t + 1} \mid a_{t})) = \max_{p(a_{t})} I(A_{t} ; S_{t + 1}) $$This is what the agent wants to do, its related to playfulness and complementary to curiosity so to say.
$$ I(A; S) = H(S) - H(S \mid A) $$Meaning high entropy environments (complex environment) and complete determinism of my own actions, define the largest empowerment signal, which is deep reward.
Sea squirt is some animal that behaves like this.