Quick introduction
Si assume che la descrizione più intelligente di un qualcosa è la stringa più corta che descrive quella, un po’ forse è arbitrario, perché minore complessità, non è detto che sia direttamente relazionata con la difficoltà di descriverla.
Nel caso di AIT, diciamo che una cosa random non è compressibile, altrimenti posso scriverla in modo più compatto. È importante stabilire che l’alfabeto che abbiamo per rappresentare qualcosa è fissato a priori. Qualunque cosa che possiamo codare si può analizzare da questo punto di vista della complessità.
The complexity of an object is assessed by finding
the shortest among the available binary descriptions
of that object.
Questa cosa permette di descrivere la complessità di un oggetto in modo assoluto (cioè a sé stante, mentre la entropia)
Information is what is left when any redundant data is thrown away.
Si basa sulla ipotesi che se tolgo qualcosa comincio a non capirci più diciamo di quella cosa, quindi è tutto importante di quella stringa.
Simple is frequent
È una assunzione che si ha su AIT, però in natura non è sempre vero, perché un sasso lungo può essere semplice per noi da comprendere, però resta una cosa rara da trovare per dire. Bisogna capire bene che cosa questa metrica mi sta misurando! La cosa è che stranamente questa legge empirica sembra vera sul web! Words are optimally stored in memory according to the frequency of the use. Però non ci dice come avviene questo processo di aggiornamento della capacità della mente di fronte all’adattarsi a questi dati.
Relative complexity
Complexity of objects in different environments can vary, we say that this is a conditioned complexity: Un esempio banale: Prendiamo un insieme ordinato di elementi, allora posso rappresentare univocamente l’elemento tramite la rappresentazione del suo indice. Questo permette di semplificare molto la descrizione di quell’oggetto, ma comunque descriverlo nella sua interessa conoscendo il prior.
When an object can be retrieved from a list,
its complexity within the list can be estimated
by the length of the binary representation of its rank.
Upper bound con complexity
When an object belongs to a set of size $N$,
its complexity in that set cannot exceed $\log_{2}(N)$
Per utilizzare l’indexing di una lista, mi basta poter essere in grado di codificare il numero più alto presente, quindi la grandezza dell’insieme per descrivere l’elemento, per questo motivo posso affermare la frase di sopra. Questo bound mi permette di descrivere la complessità di oggetti senza ordine.
Rappresentazione dei Numeri interi
$$ \lceil \log_{2}(n + 1) \rceil $$Usiamo il $+1$ per risolvere il problema col logaritmo di 0, questa comunque è una buona misura. Solo che non è il codice minimo, possiamo prendere il codice $\lceil \log_{2}(n + 3) - 1 \rceil$ come un codice migliore, perché possiamo togliere 1 perché iniziamo a contare con la cifra 1. Possiamo prefixare qualcosa per scegliere il metodo di codifica. Per esempio un numero $90000$ si può encodare come $9$ con $4$ per encodare l’esponente del 10. Ma spendiamo il bit per indexare il metodo di codifica.
In generale per rappresentare cose non numeri, si possono utilizzare strutture che rappresentano univocamente quell’oggetto e poi usare la complessità su queste strutture. Non è chiaro sempre come utilizzare queste strutture.
Quasi-continuous complexity
In questa parte analizziamo come varia la lunghezza di descrizione per i numeri, notiamo che segue più o meno la curva logaritmica, con i drops previsti per i numeri rotondi, come da intuizione (lo schema di coding presentato ha questa proprietà).
$$ \lvert C(n + h) - C(n) \rvert \leq f(\lvert h \rvert ) + O(1) $$Mentre sappiamo che per una funzione continua quello dovrebbe essere 0.
Generati da questo codice
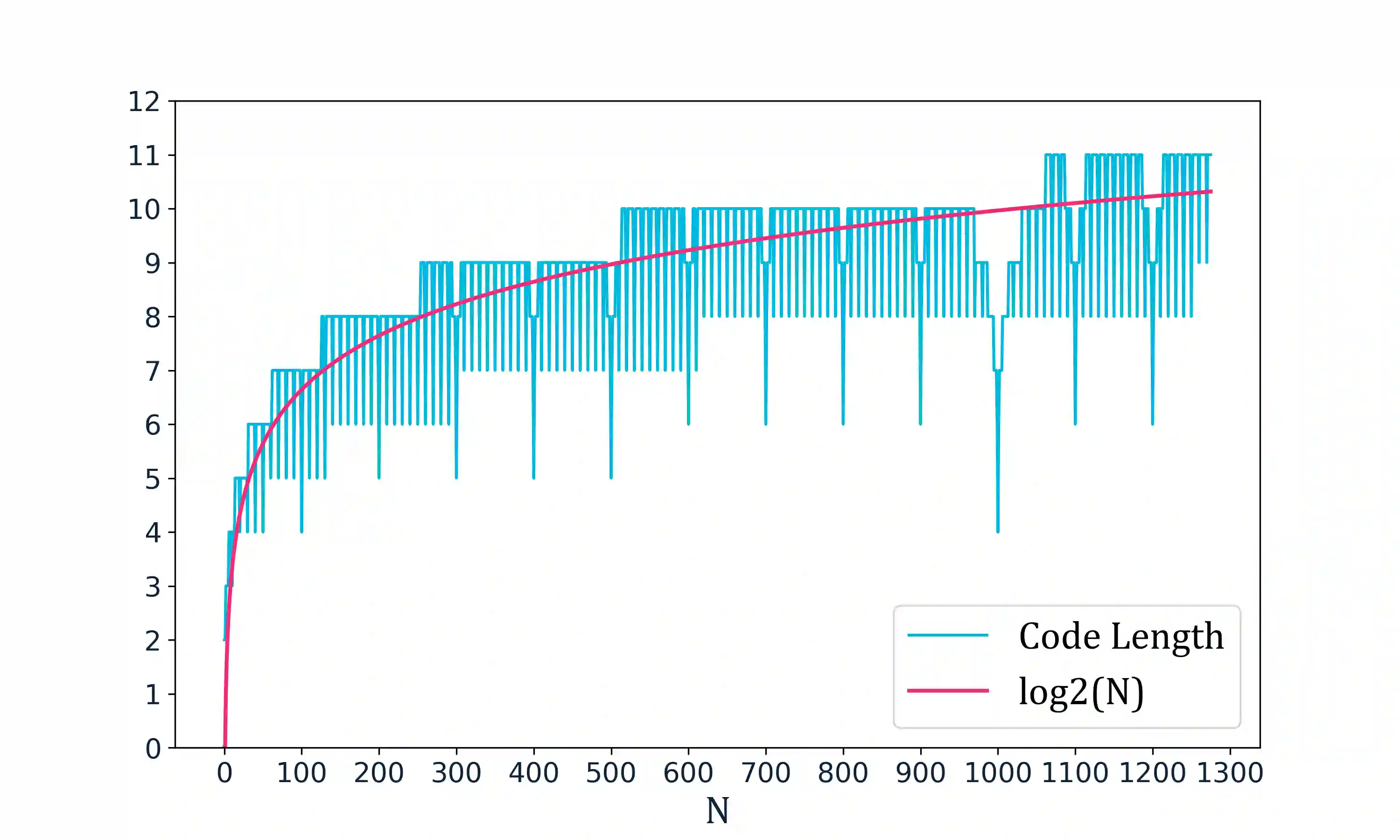
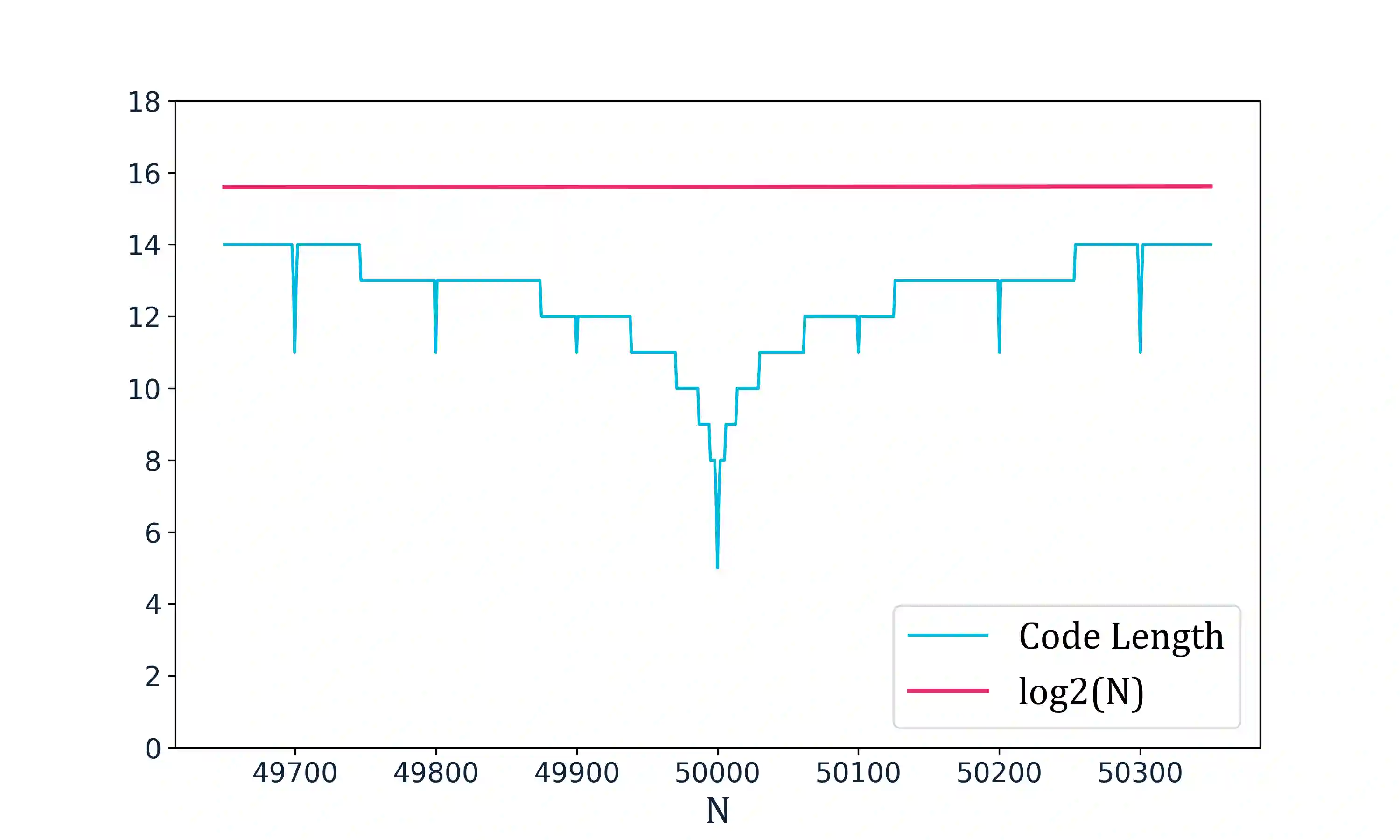
Compressibilità di stringhe binarie
Un risultato che consegue dalla limitatezza di stringhe di bassa lunghezza abbiamo che:
$$ \sum_{i=k}^{N} 2^{N - i} = 2^{N - k + 1} - 1 $$$$ \frac{2^{N - k + 1}}{2^{N}} = \frac{1}{2^{k - 1}} $$Se dati un insieme di tutte le stringhe binarie lunghe $N$, volessimo contrarre la descrizione di almeno $k$, avremmo che solo $\frac{1}{2^{k - 1}}$ delle $2^{N}$ stringhe iniziali possono essere compresse per $k$ o più digits.
E questo è un valore che decresce in modo esponenziale, per questo le stringhe compressibili di molto sono veramente veramente poche.
Una cosa interessante è che per qualunque compressore $Z$ che si possa creare, se prendiamo sequenze binarie $N$ almeno una non è compressibile.
Expanding compressors
Una osservazione banale ci dice che se il compressore è una funzione con stesso dominio e codominio, e che sia iniettiva affinché sia univocamente decodabile, allora certe stringhe vengono espande invece che compresse! Solitamente nella pratica l’espansione succede perché il compressore aggiunge dei markers per dire che è stato compresso.
Questo ci dice che il compressor non deve comprimere sempre, ma solamente comprimere in modo dipendente dal contesto secondo me.
Zipf’s Law
Elaborato insieme a un altro tizio che si chiama Condon relaziona la frequenza di una parola nel linguaggio con il rank, ossia un dizionario che ordina le parole per frequenza d’uso. https://babel.hathitrust.org/cgi/pt?id=mdp.39015008729983&view=1up&seq=7 Il contributo di Zips è una spiegazione di questo fenomeno empirico dato da Condon.
Enunciato di Zipf
$$ r_{f}(w) \approx \frac{c}{f(w)} $$dove $f(w)$ è la frequenza della parola, e $r_{f}(w)$ è il suo rank, con una costante a caso $c$.
This means that the 10th most frequent word is 10 times more frequent than the 100th most frequent word, which is itself 10 times more frequent than the 1000th most frequent word, which is itself 10 times more frequent than the 10 000th most frequent word, and so on
Sembra che questa legge valga per molte lingue, non solo l’inglese.
Minimize effort and time to find the right word to use. Questa è la spiegazione a questo fenomeno.
Corrispondenza sulla complessità dei codici
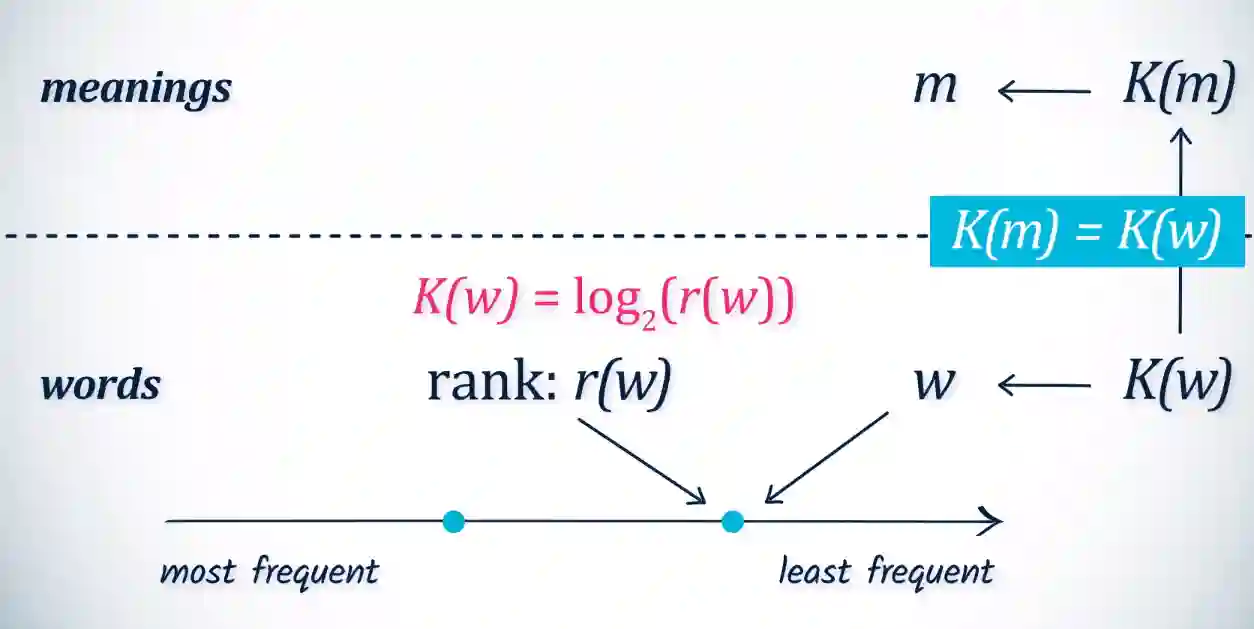
- Complexity of the meaning = complexity of word
- Complexity is related to the frequency of the word
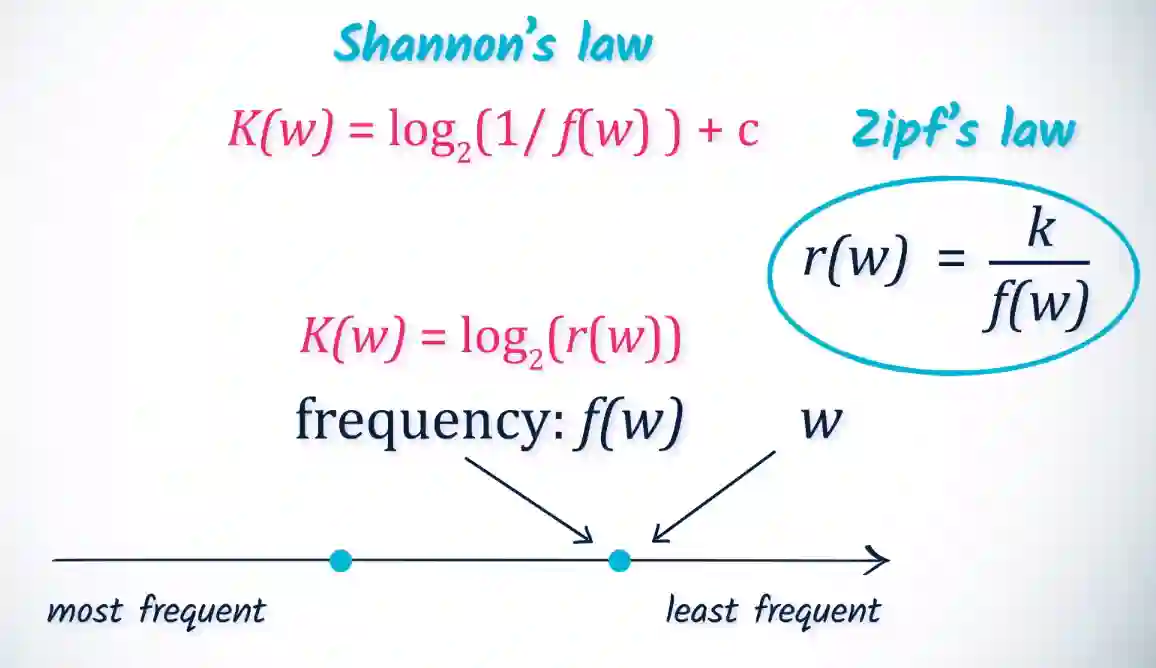
Questo spiega anche cose sulla ripetizione spaziata in (Brown et al. 2014). E ha senso, cose che vediamo più spesso ci appaiono come semplici, cose che vediamo singola volta sono abbastanza complesse, la relazione sulla complessità sembra essere fortemente legata alla frequenza della parola. Che bella idea.
Normalized information distance
Basato su (Li et al. 2004).
For any pair of objects, NID determines what is common to them, and only keeps their difference to measure the distance that separates them.
Calcolo del NID
- Misurare la differenza di informazione attraverso il Kolmogorov Condizionato quindi $max[K(x|y), K(y|x)]$ il max ci aiuta a rendere la distanza simmetrica.
- Normalizzare la differenza di informazione, perché vogliamo una nota relativa di questa misura. $max(K(x), K(y))$ che rappresenta la massima complessità di entrambi gli oggetti che vogliamo confrontare.
- Usare Kolmogorov complexity#Chain Rule cosicché possiamo riscrivere il numeratore.
Questo non è computabile perché $K$ non è computabile, ma possiamo stimarlo con un compressore reale. La cosa triste è che il compressore non prende in considerazione la semantica. Per la semantica è interessante usare la (Cilibrasi & Vitanyi 2007), usando google per stimare la distanza. e questa la chiama la Normalized Google Distance.
Universal distance
$$ \forall D; \forall x, y: D_{U}(x, y) < D(x, y) + C_{D} $$Questo: $max[K(x|y), K(y|x)]$ è una distanza universale. Che è una cosa molto interessante.
References
[1] Cilibrasi & Vitanyi “The Google Similarity Distance” arXiv preprint arXiv:cs/0412098 2007
[2] Li et al. “The Similarity Metric” IEEE Transactions on Information Theory Vol. 50(12), pp. 3250--3264 2004
[3] Brown et al. “Make It Stick: The Science of Successful Learning” Harvard University Press 2014