Questo documento è totalmente concentrato sull’analisi del problema della selezione del k-esimo elemento.
7.1 Introduzione al problema
Dato un array di elementi vogliamo cercare di trovare un modo efficiente per selezionare il k-esimo elemento, ossia un elemento che sia maggiore di k-1 elementi
7.1.1 Note sull’utilizzo
Questo algoritmo è utile per esempio per sapere cosa displayare in una pagina di ricerca, perché per esempio posso avere blocchi di tanta roba 140k, mentre ovviamente posso selezionare solamente un blocco ristretto.
Es: mostrare i primi k in ordine di rilevanza!
7.2 Prime soluzioni
Notiamo che possiamo riadattare le soluzioni ai problemi di ordinamento per trovare il k-esimo elemento.
7.2.1 Selezione del minimo
Questo è un algoritmo che va a modificare il selection sort (utilizzando la stessa idea per creare un subarray crescente).
-
Slide

Faccio k cicli per trovare i k minimi per circa n volte, anche se l’analisi esatta è data da questa sommatoria, che è qualcosa di simile, ma non esattamente quello.
$\sum_{i = n - k + 1} ^{n} i$
7.2.2 HeapSelect
Io utilizzo una heap per trovare i k-esimi minimi, praticamente sto facendo un heap sort, ma con l’altra heap, e sto espellendo piccoli elementi uno alla volta..
-
Slide

-
Piccole note sul costo (funziona se ordini inferiori!)
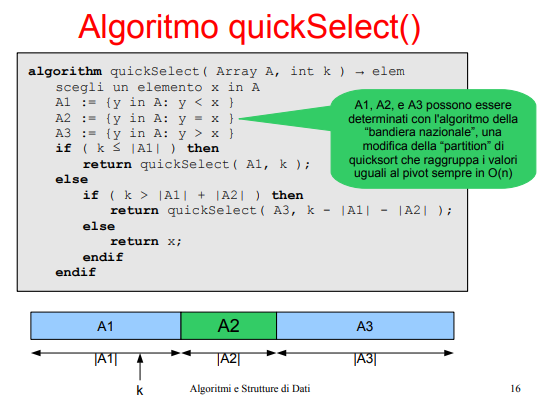
7.2.3 QuickSelect
Un primo approccio potrebbe essere utile cercare di ordinare l’array con questo e prendere il k-esimo elemento.
Poi noto che posso sfruttare il divide e conquer di qucksort per sapere quanti elementi sono minori di k! ho principalmente 3 casi:
-
Pseudoalgo mio (molto a parole) ho esattamente k - 1 elementi minori di x nel primo insieme dopo il partition, quindi ritorno x. Ho meno elementi di k - 1 minori di x dopo il partition, quindi vado a cercare il k esimo in questo insieme qui. Ho più elementi di k - 1 minori di x dopo il partition, vado a cercare l’offset corretto nell’altro insieme.
-
Pseudocodice di slide
-
Pseudocodice bandiera nazionale che serve qui

Analisi nel caso ottimo e pessimo (e medio)
L’ottimo e pessimo è abbastanza facile perché si riconduce esattamente all’analisi di quicksort
In pratica O(n) nel caso migliore (perché ora ho una chiamata ricorsiva in meno)
O(n2) nel caso peggiore perché è identico a quicksort.
Il caso medio è un pò più difficile da analizzare, dimostreremo che è in O(n). vediamo perché
-
Analisi medio
Supponiamo che scegliamo sempre la partizione sfavorevole (quindi da n/2 a n), allora la relazione di ricorrenza (supponendo distribuzione uniforme semplice di queste possibilità) ho

Posso dimostrare utilizzando la sostituzione questo. fine
8 Priority-Queue
È di solito implementata con la Heap. Iniziamo a fare una descrizione di questa strututra
- Altre implementazioni che però non sono richieste ma interessanti
- Binomial Heap
- fibo-heap
8.1 Introduzione
Questa struttura di dati sarà utile in seguito per algoritmi di grafi come Dijstra o Prim per il MST.
Questa struttura come la Heap (anche fattibile con fibo-heap o heap binomiali!), manterrà il minimo, non è esattamente FIFO o LIFO come stack e queue
8.1.1 Interfaccia della struttura
- Insertion (log n)
- Deletion (log n)
- Creation (n)
-
Slide delle operazioni

8.1.2 Esempi di utilizzi
- Base per altri algoritmi (come Dijstra o Prim)
- Processing di pacchetti per il routing
- Qualunque posto in cui c’è bisogno di processare secondo un certo ordine
8.2 D-heap
La differena con la heap normale è che questo è un albero che abbia d-rami.
-
Slide di descrizione

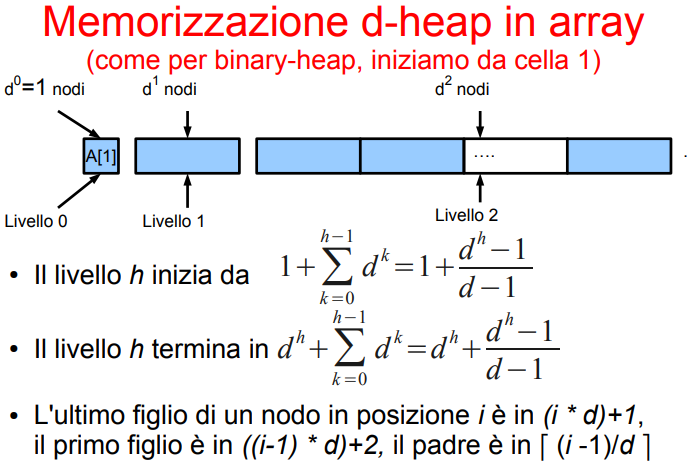
8.2.1 Altezza e Memorizzazione
-
Lemma altezza della heap

Questa dimostrazione sull’altezza dell’heap è molto simile a tutti gli alberi binari. Come gli alberi binari possiamo memorizzarli facendo un offset sulla cella attuale!
-
Memorizzazione della d-heap
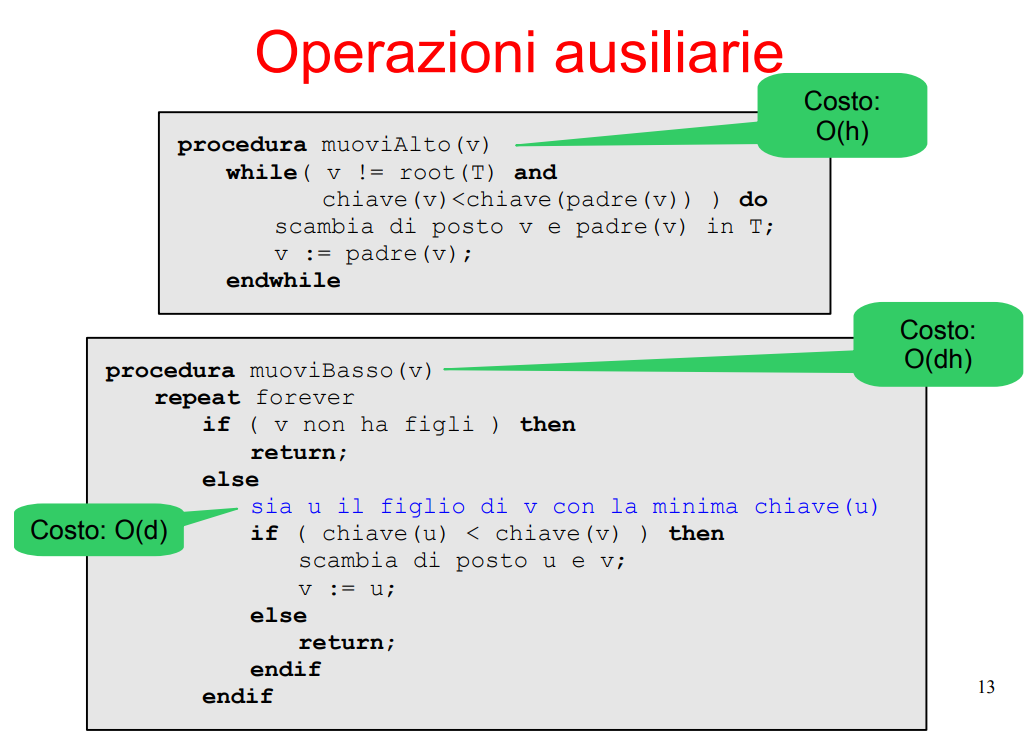
Operazioni helper importanti:
Sono molto utilizzate per le operazioni di delete, insertion e simili.
-
Muovi alto e muovi basso
8.2.2 Sunto dei costi e note
L’unica operazione che può essere complessa è la deletion, in cui bisogna contemplare anche il bubble up (viene eseguito solo una volta questa oppure bubble down).
-
Riassunto in slide

9 Union-Find
9.1 Introduzione
Questa struttura di dati ci sarà utile per gestire insiemi disgiunti
9.1.1 Interfaccia della struttura
- Vedere se due elementi appartengono allo stesso insieme
- trovare il rappresentante
- Unire degli insiemi
-
Slide interfaccia

Ogni insieme è indicato da uno e un solo rappresentante, un suo elemento che fa finta di essere l’insieme stesso. Questa è l’idea più importante per comprendere la rappresentazione di questa struttura di dati.
9.1.2 Intuizione sull’utilizzo
Ho un insieme di ingredienti che siano tutti separati, vorrei unirli con magari un certo ordine, creando delle nuove cose. E continuare a vedere se li ho già uniti o meno.
Alla fine vedo l’unione degli elementi in questo modo
-
Esempio di problema risolto con DSU

-
Slide possibili implementazione (trattati subito dopo

9.2 QuickFind
- Find in tempo costante e union in tempo lineare (possibile ammortizzare a tempo costante)
9.2.1 Metodi di rappresentazione (only lista)
Un insieme è rappresentato tramite un albero di altezza UNO.
Questo è possibile tramite una lista concatenata, in cui ogni nodo punta sempre al nodo rappresentante.
-
Slide rappresentazione tramite liste
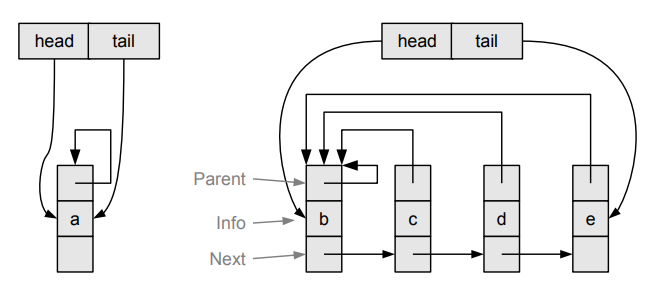
Ci aggiungo io che si può utilizzare anche un semplice array e l’index come un pointer per creare tale struttura.
9.2.2 Union e sunto delle operazioni
L’union di due insiemi è una sovrascrittura del pointer del rappresentante dell’insieme che viene unito, come si può intuire nell’esempio di union.
Il find è immediato, perché deve risalire di solamente un arco.
-
Esempio di operazione di union
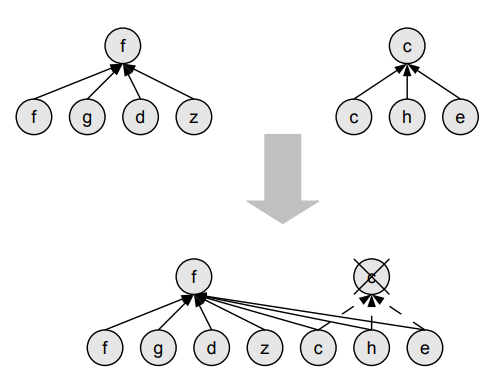
-
Riassunto delle operazioni

9.2.3 Euristica del peso (!!)
Voglio cercare di limitare il tempo di unione di due insiemi.
L’idea è unire l’insieme con meno figli a quello con di più. mi mantengo questa informazione sulla radice dell’albero.
-
Slide dell’idea
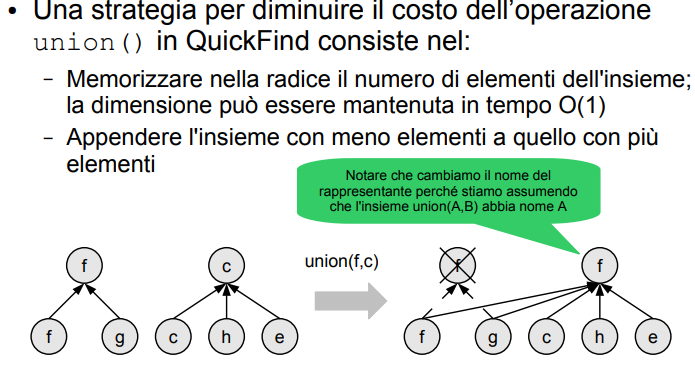
Costo di Union
Il tempo resta lineare, però è almeno dimezzato l’upper bound del tempo necessario per fare questa operazione.
Costo ammortizzato
Posso osservare che per la proprietà sopra, se una foglia cambia radice l’insieme di arrivo è grande almeno il doppio dell’insieme precedente, questa proprietà mi permette di concludere che al massimo posso swappare log n volte.
Questo ragionamento mi permette di concludere un costo ammortizzato per questa operazione di union
-
Analisi union ammortizzato
Notiamo che al massimo, in una union, $n/2$ elementi possono cambiare parente Quindi il caso pessimo di union in questo modo resta in $O(n)$, ma possiamo fare di meglio.

Nota: dopo n - 1 union, sto facendo union con se stesso, che non ha senso, quindi resto con n - 1, che è il caso pessimo d union).
9.3 QuickUnion
È una altra rappresentazione dell’union find, in cui è presente una foresta (uguale alla precedente, ma in questo caso posso avere anche altezza superiore a 1!)
9.3.1 Introduzione alla struttura e implementazione (array)
-
Slide sulla struttura
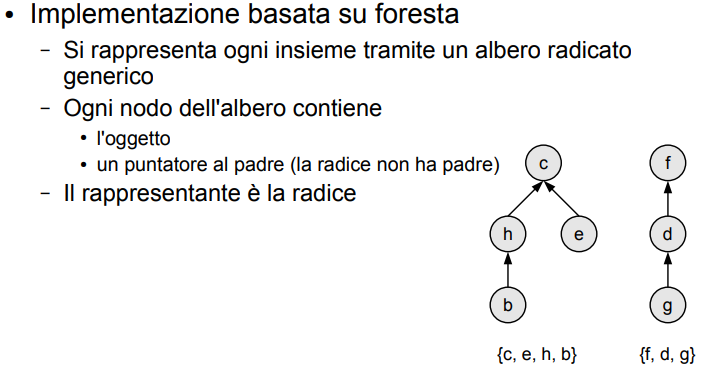
-
Slide di rappresentazione dell’array
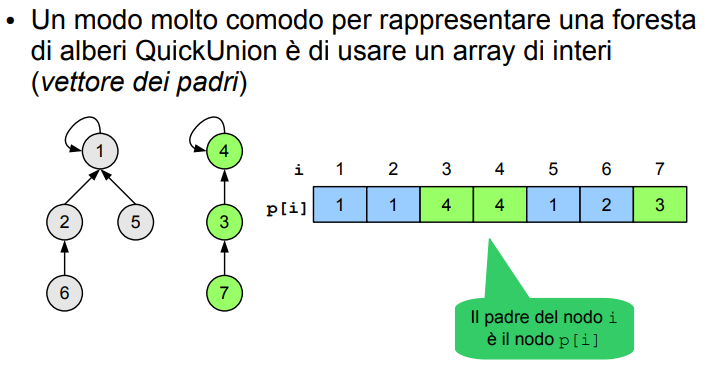
Si utilizza il parent vector!
9.3.2 Find e sunto delle operazioni
Per union basta infatti prendere la radice del primo insieme e farla puntare alla radice dell’insieme in cui si vuole unire, invece che farlo puntare a sé stesso (fa questa ultima cosa perché era la radice)
-
Slide di riassunto

9.3.3 Euristica del rank (!!)
Voglio cercare di limitare il tempo di ricerca del rappresentante. L’idea è nel momento di fare l’union, lo faccio scegliendo di unire l’elemento con rank minore (ovvero con altezza dell’albero minore) con quello maggiore.
Analisi caso pessimo
-
Upper bound rank di x (dim)

La dimostrazione è abbastanza noiosa, basta che tengo in considerazione i tre casi: quando rank(a) = rank(b), quando è minore, e quando è maggiore, sapendo l’ipotesi induttiva, non dovrebbe essere tanto difficile concludere quanto voluto.
(se ho una limitazione superiore all’altezza dell’albero allora è chiaro che il find è in log n.
In questo modo riesco proprio a creare un upper bound logaritmico al find, a differenza del costo ammortizzato di questo con l’euristica del peso in quickfind.