Livello trasporto
Protocolli classici
Introduzione a TCP e UPD
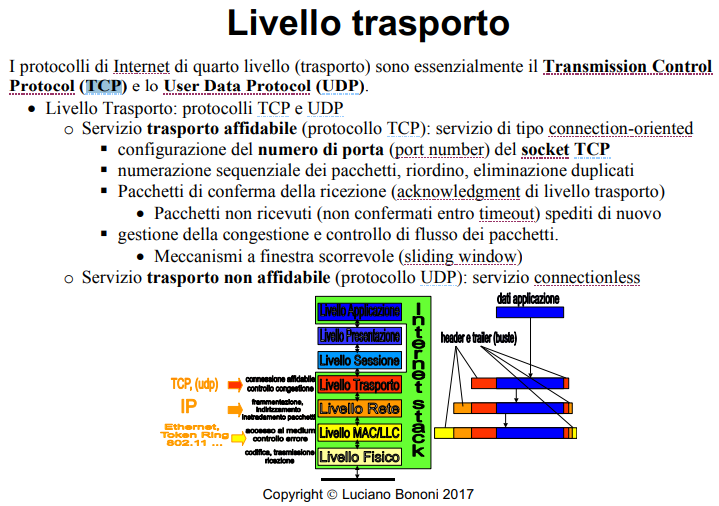
Il quarto livello dei protocolli dell’architettura di Internet è il livello trasporto (transport), ed è basato su due protocolli in particolare: il Transmission Control Protocol (TCP) e lo User Data Protocol (UDP), che possono essere usati in alternativa tra loro.
Questo è nel genere di *connession oriented e non, il primo, TCP è connection oriented, l’altro no, questa è l’unica differenza fra i due. Questa differenza è spiegata in maggior dettaglio qui [0.3.8 Servizi orientati alla connessione e non
TCP
- Connection oriented (garantire il ripristino dell’ordinamento dei pacchetti e la ri-trasmissione dei pacchetti perduti)
- Numero dell’ordine (a cui riceve ack per questo numero)
- Controllare la velocità di invio → Finestra scorrevole La parte importante di questo è che la congestione si può allargare a macchia d’olio all’interno di internet, e questo è una cosa molto brutta!
Quindi prova a risolvere gli errori di comunicazione di rete, cercando di garantire una buona trasmissione. Il problema è l’efficienza, si possono inviare segmenti in più e congestionare la rete.
Si può dire che questa è la semantica diversa.
Con la tree-way handshake si apre una connessione socket, quindi una coppia porta IP, per poter comunicare!
UDP
- È semplice perché non fa tutte le cose di TCP (no duplicati, no riordinamento, no checks)
- Tipo connectionless
Socket

-
Slide immagini
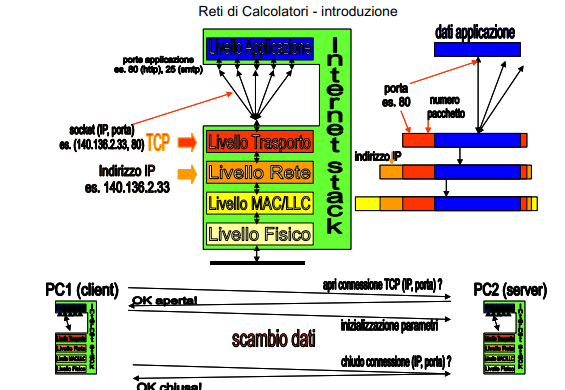
Il protocollo TCP richiede a due dispositivi che intendano comunicare di effettuare preventivamente la configurazione dei parametri del socket TCP, originando in questo modo un canale virtuale di tipo punto a punto tra due socket, ovvero tra due applicazioni di livello superiore alle quali vengono smistati i pacchetti da TCP. Quindi sono degli estremi di comunicazione!
Def socket
Un socket è un punto di arrivo o partenza (virtuale) dei dati a livello trasporto, dal quale è in atto l’invio e la ricezione di pacchetti destinati a un’applicazione, ed equivale a una coppia: (indirizzo IP, numero di porta dell’applicazione). Una volta instaurata la configurazione punto a punto tra due socket, attraverso lo scambio di pacchetti di configurazione, può iniziare lo scambio dei dati a livello trasporto. In questo senso si dice che è un trasporto TCP/IP, perché prima configurazione per IP poi effettivamente scambio.
La richiesta di connessione
La connessione viene instaurata con una richiesta di uno dei due host (il client) nei confronti dell’host server.
- Indirizzo IP del server
- Numero della porta per l’applicazione (questo viene verificato dal server se qualche servizio ci è aperto, se sì risponde, e il client invia la configurazione).
- Poi iniziano a dialogare e alla fine liberano la porta, è una connessione punto a punto!.
Quando il server riceve il pacchetto, va a verificare se ha la porta aperta, se tutto va bene manda un messaggio di conferma, e il client invia un pacchetto di configurazione, allora possono cominciare a comunicare.
Welcoming socket and client sockets
Welcoming è l’unico socket di ricezione di un server, che prende tutto e manda al thread corretto.
Client sockets sono i molteplici sockets che il server utilizza per comunicare con il singolo client, vengono solitamente istanziati grazie al welcoming socket dopo che ho fatto richiesta di connessione.
Controllo della congestione TCP (2)
Questa parte ora è trattata meglio in [[Livello di trasporto](/notes/0.3.8-servizi-orientati-alla-connessione–e-non-
tcp
1.-connection-oriented-(garantire-il-ripristino-dell’ordinamento-dei-pacchetti-e-la-ri-trasmissione-dei-pacchetti-perduti) 2.-numero-dell’ordine-(a-cui-riceve-ack-per-questo-numero) 3.-controllare-la-velocità-di-invio-→-finestra-scorrevole la-parte-importante-di-questo-è-che-la-congestione-si-può-allargare-a-macchia-d’olio-all-interno-di-internet,-e-questo-è-una-cosa-molto-brutta!
quindi-prova-a-risolvere-gli-errori-di-comunicazione-di-rete,-cercando-di-garantire-una-buona-trasmissione.-il-problema-è-l-efficienza,-si-possono-inviare-segmenti-in-più-e-congestionare-la-rete.
si-può-dire-che-questa-è-la-semantica-diversa.
con-la-tree-way-handshake-si-apre-una-connessione-socket,-quindi-una-coppia-porta-ip,-per-poter-comunicare!
udp
1.-è-semplice-perché-non-fa-tutte-le-cose-di-tcp-(no-duplicati,-no-riordinamento,-no-checks) 2.-tipo-connectionless
###-socket <img-src="/images/notes/image/universita/ex-notion/livello-applicazione-e-socket/untitled-1.png"-style=“width:-100%"-class=“center”-alt=“image/universita/ex-notion/livello-applicazione-e-socket/untitled-1”>
–slide-immagini
—-<img-src="/images/notes/image/universita/ex-notion/livello-applicazione-e-socket/untitled-2.png”-style=“width:-100%"-class=“center”-alt=“image/universita/ex-notion/livello-applicazione-e-socket/untitled-2”>
il-protocollo-tcp-richiede-a-due-dispositivi-che-intendano-comunicare-di-effettuare-preventivamente-la-configurazione-dei-parametri-del-socket-tcp,-originando-in-questo-modo-un-canale-virtuale-di-tipo-punto-a-punto-tra-due-socket,-ovvero-tra-due-applicazioni-di-livello-superiore-alle-quali-vengono-smistati-i-pacchetti-da-tcp.-quindi-sono-degli-estremi-di-comunicazione!
def-socket
un-socket-è-un-punto-di-arrivo-o-partenza-(virtuale)-dei-dati-a-livello-trasporto,-dal-quale-è-in-atto-l’invio-e-la-ricezione-di-pacchetti-destinati-a-un’applicazione,-ed-equivale-a-una-coppia:-(indirizzo-ip,-numero-di-porta-dell’applicazione).-una-volta-instaurata-la-configurazione-punto-a-punto-tra-due-socket,-attraverso-lo-scambio-di-pacchetti-di-configurazione,-può-iniziare-lo-scambio-dei-dati-a-livello-trasporto.-in-questo-senso-si-dice-che-è-un-trasporto-tcp/ip,-perché-prima-configurazione-per-ip-poi-effettivamente-scambio.
la-richiesta-di-connessione
la-connessione-viene-instaurata-con-una-richiesta-di-uno-dei-due-host-(il-client)-nei-confronti-dell’host-server.
1.-indirizzo-ip-del-server 2.-numero-della-porta-per-l-applicazione-(questo-viene-verificato-dal-server-se-qualche-servizio-ci-è-aperto,-se-sì-risponde,-e-il-client-invia-la-configurazione). 3.-poi-iniziano-a-dialogare-e-alla-fine-liberano-la-porta,-è-una-connessione-punto-a-punto!.
quando-il-server-riceve-il-pacchetto,-va-a-verificare-se-ha-la-porta-aperta,-se-tutto-va-bene-manda-un-messaggio-di-conferma,-e-il-client-invia-un-pacchetto-di-configurazione,-allora-possono-cominciare-a-comunicare.
welcoming-socket-and-client-sockets
welcoming-è-l-unico-socket-di-ricezione-di-un-server,-che-prende-tutto-e-manda-al-thread-corretto.
client-sockets-sono-i-molteplici-sockets-che-il-server-utilizza-per-comunicare-con-il-singolo-client,-vengono-solitamente-istanziati-grazie-al-welcoming-socket-dopo-che-ho-fatto-richiesta-di-connessione.
###-controllo-della-congestione-tcp-(2)
questa-parte-ora-è-trattata-meglio-in-[[livello-di-trasporto)
-
Slide

-
Schema
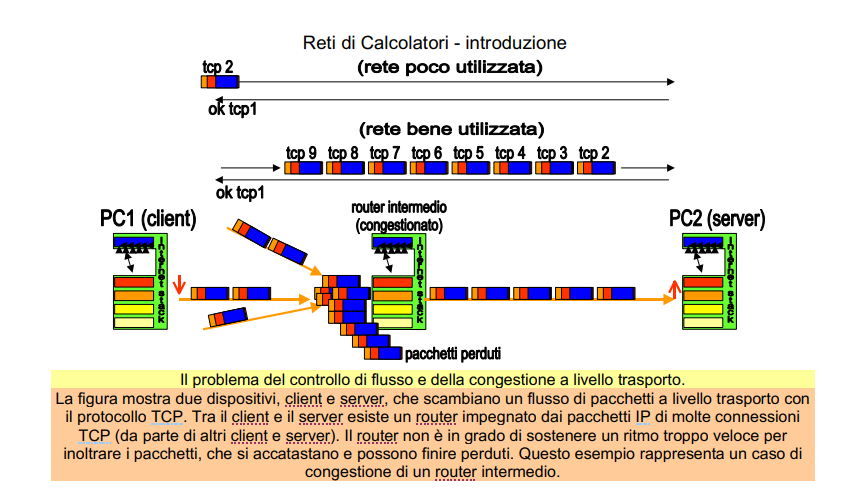
TCP utilizza un protocollo molto particolare, e a prima vista non intuitivo per gestire la congestione della rete.
L’idea generale è che provo ad aumentare l’invio finché posso, e quando mi accorgo che inizio a perdere chiudo tutto e ricomincio dal singolo pacchetto.
Come si è detto in precedenza, TCP richiede una conferma per ogni pacchetto inviato. La distanza tra due dispositivi che scambiano pacchetti a livello trasporto può essere molto significativa. Il tempo per inviare un pacchetto e ottenere la conferma dell’avvenuta ricezione può quindi diventare dell’ordine dei secondi. Il problema del controllo di flusso dei pacchetti nel protocollo TCP si basa su due scopi apparentemente in contraddizione tra loro.
- è quello di saturare il più possibile la rete di pacchetti, inviandoli a un ritmo elevato. Questo favorisce l’utilizzo delle risorse e le prestazioni della rete (si spediscono e si ricevono tanti bit al secondo). Se si decidesse di inviare un pacchetto e aspettare l’arrivo della conferma, la rete sarebbe usata solo in minima percentuale, e si riuscirebbero a spedire solo pochi bit al secondo. Quindi la rete, pur essendo veloce nell’invio dei bit, verrebbe sfruttata al minimo delle potenzialità. E’ quindi evidente quanto sia opportuno spedire i pacchetti a un ritmo il più veloce possibile.
- Evitare di saturare la rete occorre evitare che un ritmo di invio troppo elevato possa causare il sorgere della congestione nei router intermedi del cammino dei pacchetti, dal mittente TCP (client) al destinatario TCP (server). Se un router si trova a dover inoltrare troppi pacchetti, provenienti da flussi TCP diversi, i pacchetti si accumulano fino ad andare perduti e la rete va in crisi. In tal caso si deve ricorrere a una tecnica di controllo della congestione. Una forma di congestione può comparire anche sul destinatario finale, nel caso in cui esso non sia in grado di ricevere i pacchetti inviati troppo velocemente. In tal caso si deve ricorrere a una tecnica di controllo di flusso.
Finestra scorrevole
Si parla di metodi di congestione, viene trattato meglio in Livello di trasporto

Osservando l’esempio, partendo con SW uguale a 1, se la conferma è ricevuta, la finestra viene raddoppiata, spedendo due pacchetti al massimo ritmo di invio. Se entrambi i pacchetti vengono confermati, si passa alla finestra di dimensione quattro, inviando quattro pacchetti al massimo ritmo di invio. Se i pacchetti sono confermati si passa a finestra di otto pacchetti. A questo punto, nell’esempio, almeno uno degli otto pacchetti non viene confermato. Si suppone che questo fatto sia dovuto a un router congestionato e quindi si rallenta il ritmo di invio ripartendo dalla finestra minima (pari a uno). Il massimo grado sostenibile di invio per la rete in esame nell’esempio è stato quindi ottenuto con finestra pari a quattro.
<img src="/images/notes/image/universita/ex-notion/Livello applicazione e socket/Untitled 6.png" style="width: 100%" class="center" alt="image/universita/ex-notion/Livello applicazione e socket/Untitled 6">
TCP usa un meccanismo per il controllo di flusso, detto a finestra scorrevole (sliding window), e un meccanismo per il controllo della congestione, basato sul dimensionamento della finestra scorrevole. Tutto ciò per cercare il massimo ritmo di spedizione che possa garantire l’inoltro dei pacchetti da parte del router più lento del cammino, e prevenire la saturazione del destinatario finale.
Idea della sliding window
La finestra scorrevole è un valore intero, cha parte da un valore minimo (ad esempio il valore uno). L’idea alla base del controllo di flusso a finestra scorrevole è quello di spedire non più di Sliding Window pacchetti consecutivi, a partire dall’ultimo pacchetto non confermato, e quindi attendere la ricezione di una conferma. Un valore di SW uguale a 1 significa che solo un pacchetto può essere spedito, poi occorre aspettare di ricevere la conferma della ricezione. In questo caso la rete è poco utilizzata. Ogni volta che alcuni pacchetti spediti sono confermati, allora è possibile spedire i pacchetti successivi mantenendosi entro il limite massimo di SW pacchetti dall’ultimo pacchetto non ancora confermato. Eventuali pacchetti non confermati sono rispediti fino al ricevimento della conferma.
Il senso di questo meccanismo è quello di lasciare in sospeso non più di SW pacchetti, per evitare di saturare il mittente. Questo meccanismo, molto semplificato, realizza il controllo di flusso di TCP. Se i pacchetti vengono confermati, si può adottare un meccanismo dinamico per accelerare gradualmente il ritmo di invio dei pacchetti, ovvero la dimensione della finestra SW, fino a che non si nota la perdita di almeno un pacchetto tra quelli inviati.
Comportamento a perdita di pacchetti
Se i pacchetti vanno perduti, TCP assume anche che la causa di ciò sia la presenza di un router intermedio congestionato, e quindi rallenta il ritmo di invio dei pacchetti per dare modo al router congestionato di smaltire i pacchetti accumulati. Tale meccanismo, sommariamente descritto, è il meccanismo di controllo della congestione di rete di TCP.
Multiplexing e Demultiplexing e porte
Questi termini non hanno una traduzione diretta con l’italiano, la cosa più simile possibile è aggregare e disaggregare, perché da una unica scheda direte arriva tutto, questa cosa deve essere demultiplexata alla porta corretta, e multiplexata all’unica scheda di rete che si ha.
Le well known ports sono di solito minori di 1023.
Le porte alte sono decise da noi, basta che nell ostess ocomputer non ci sia un conflitto di porte.
Multiplexing perché ho molte porte, ma unica scheda di rete, quindi far girare da una unica source tutto il resto. (per il mandante serve0
Demultiplexing perché così posso mandare alla porta corretta, ricevendo
-
Slide multiplexing
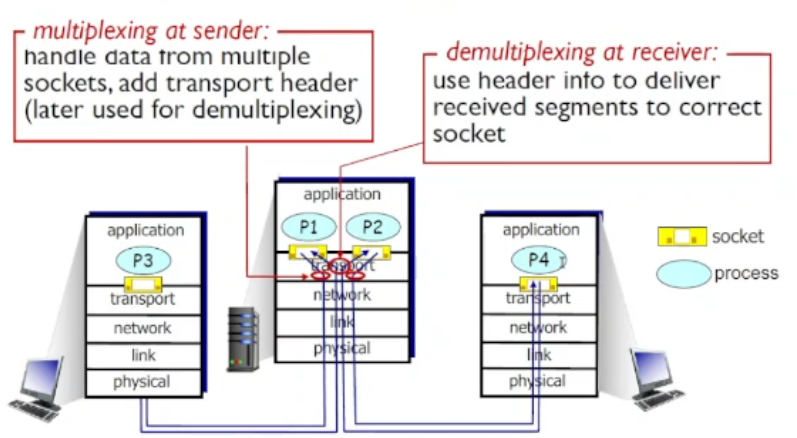
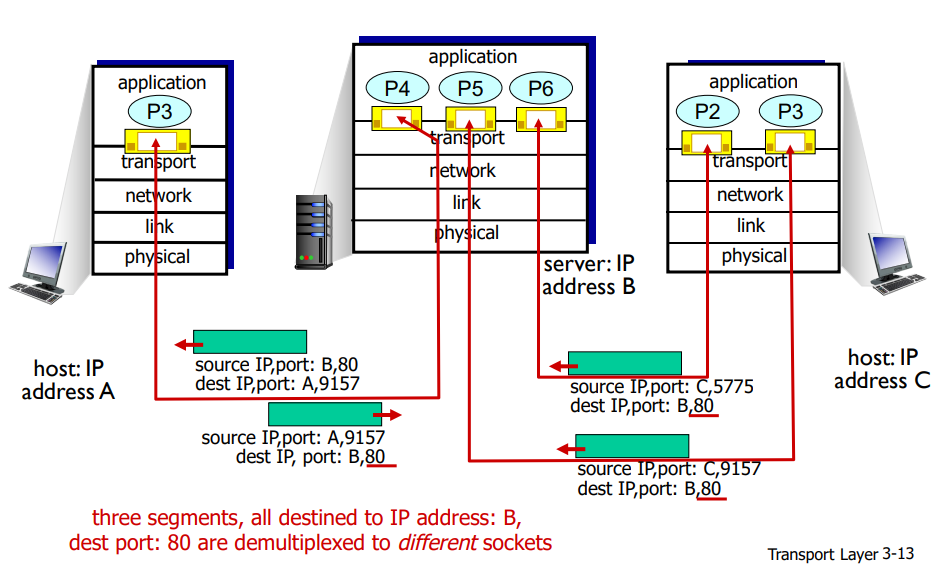
In pratica il server con una singola porta non sarebbe in grado di rispondere a connessioni multiple! Ricorda che socket è end-to-end, non saprei a quale client starei parlando.
Si parla quindi di welcoming socket per il server, e quando si stabilisce la connessione ti dice in quale porta andare sopra per continuare a comunicare.
-
Esempio di demux server
Applicazione
Introduzione livello applicazione (non fo)
Il livello applicazione dei protocolli di Internet contiene l’implementazione delle funzioni e dei servizi che permettono alle applicazioni di rete in esecuzione sull’host di spedire e ricevere i dati. I protocolli sottostanti di Presentazione e Sessione, previsti dallo Standard ISO/OSI, non sono quasi mai considerati nell’architettura dei protocolli di Internet.
Il livello Applicazione si appoggia direttamente sul livello trasporto e, in particolare, molte applicazioni che richiedono servizi connection-oriented si basano sul protocollo TCP, attraverso numeri di porta che nel tempo sono diventati standard “de facto”. Ad esempio, la spedizione e il trasferimento dei messaggi di posta elettronica, basati sul protocollo di livello applicazione Simple Mail Transfer Protocol (SMTP) è comunemente associata alla porta di livello applicazione 25. La porta 80 è destinata al protocollo di trasferimento di ipertesti HyperText Transfer Protocol (HTTP) alla base del trasferimento delle pagine di siti del World Wide Web.
Altri esempi di protocolli e servizi che si collocano al livello applicazione sono il protocollo e servizio di Domain Name Service (DNS) e i protocolli IMAP e POP3 per la consegna della posta elettronica. Una dettagliata illustrazione sul mondo dei servizi e protocolli applicativi di Internet sarà oggetto di un modulo apposito
HTTP1 (non fare)
All’inizio bisognava aprire connessione per ogni singolo file che bisognava richiedere, quindi molto lento, ora sappiamo riuscire a creare socket di connessione che non si chiudono subito
Molto bene è descritto in HTTP e REST
Domain Name System

- Immagine di spiegazione
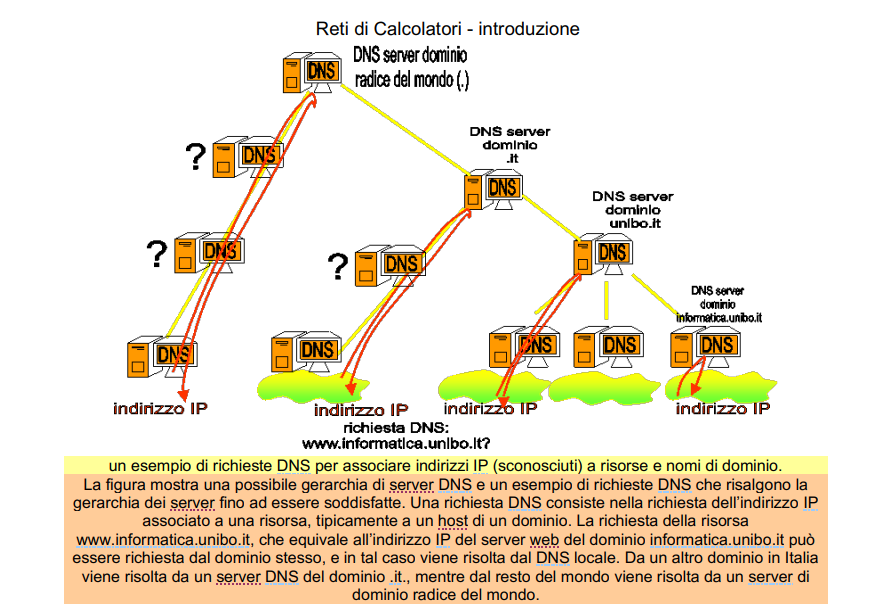
Vorremmo avere un metodo molto semplice per umani per poter trovare un sito, ma il livello di rete non li sa gestire, ha bisogno di IP, allora ho bisogno di alcuni server dedicati che mi restituiscono l’IP dato un nome di dominio! Questo è unico, altrimenti ci sarebbe ambiguità riguardo al nome. E altra cosa, ci sono i server DNS che sappiano dare l’IP corretto a seguito del DNS.
Problema
Gli utenti di Internet preferiscono usare nomi mnemonici per identificare le risorse in rete, ad esempio nomi di host appartenenti a una certa rete, oppure indirizzi di e-mail di utenti di una certa rete. Anche le reti, risultano spesso facilmente identificabili attraverso i nomi di dominio della rete. I nomi di dominio hanno quindi lo stesso senso degli indirizzi IP, e infatti vengono assegnati da enti internazionali, come gli indirizzi IP, per evitare confusione e nomi duplicati. Le risorse appartenenti a un dominio possono avere nomi scelti arbitrariamente (ad esempio nomi di host, indirizzi di e-mail) purchè non siano duplicati all’interno del dominio stesso. Nomi di risorse duplicati sono ammessi in domini diversi, (ad esempio, pippo@topolinia.it e pippo@paperopoli.com). I nomi di dominio hanno una struttura gerarchica del tipo (nomerisorsa.sottodominio.sottodominio.dominioradice). Ad esempio www.informatica.unibo.it è il nome dell’host che agisce da web server per il sottodominio informatica, del sottodominio Università di Bologna, del sottodominio di livello massimo .it (Italia). In realtà il dominio radice del mondo, che esiste implicitamente, non si scrive mai. Tutto ciò è comodo ma viola le esigenze del livello rete e dei router che pretendono solo indirizzi IP.
DNS per risolvere il problema
Per risolvere il problema, è nato il servizio Domain Name System (DNS) che attraverso una gerarchia di server e un protocollo standard per le richieste permette di risolvere l’associazione tra nome della risorsa e indirizzo IP. Ogni host in rete deve conoscere un server DNS al quale inviare le richieste e ogni server DNS deve conoscere almeno un server DNS di livello superiore. I server di livello superiore conoscono un numero sempre maggiore di nomi e relativi indirizzi IP, ma sono sempre meno per motivi di costo.
L’esempio mostra come viene soddisfatta una richiesta DNS a seconda del punto della rete di server DNS dalla quale parte. Se un server DNS non conosce la risposta passa la richiesta al livello superiore, finché qualcuno non conosce l’indirizzo IP.
Note sull’affidabilità
È una cosa molto brutta tenere un singolo server che possieda questo server DNS, perché se fallisce nessuno può più raggiungerlo!. Quindi vogliamo andare a creare una alta ridondanza riguardo questo server DNS.
- Replicare servizi anche in zone differenti (ne basta una su e il servizio apparentemente è su, ecco il sistema distribuito!).
Iterativo/Ricorsivo
Iterativo il DNS ti risponde col nuovo dns server da contattare per poter avere una risposta
Ricoversivo quando il DNS stesso va a chiedere, e quindi quando ti risponde ti da già il risultato corretto.
Quindi in un caso si pone molto più onere sul client che ha richiesto, nel secondo caso si pone onere sul server DNS. Quindi a seconda di quanto hai bisogno puoi fare l’uno o l’altro direi.
Typosquatting attack
Questo è un attacco sui DNS. Sappiamo che questo servizi risolvono testo in IPs che poi vengono utilizzati per mandare le richieste sulla rete. Però questo approccio è attaccabile da domini che hanno codifiche diverse, ma carattere uguale all’utilizzatore.
In questo modo un utente può essere ingannato a cliccare su quell’url, anche se il domain name originale è diverso perché invece di A scrive А, per esempio hex-dump di A А è 41 20 d0 90 a vediamo chiaramente che la seconda A in cirillico è rappresentato da tre bytes, anche se sembrano esattamente essere uguali. Questo può essere utilizzato e attaccato.
Sulla connessione
Riassumento, per poterci connettere sulla rete abbiamo bisogno di queste informazioni e stack di rete qui:
- Stack TCP/IP
- firewall
- (IP, default router, maschera di rete)
- DNS
- DHCP
Architetture a livello applicazione
- Client/server
- Peer To peer
Le applicazioni e i servizi su Internet possono essere realizzati secondo almeno due modalità architetturali distinte: Architettura Client/Server e architettura Peer to Peer (P2P).
-
Client/Server, i Client sono host che spediscono richieste di servizio ai Server. I Server sono i soli host sui quali sono in esecuzione i servizi che permettono di soddisfare le richieste. Un esempio di servizi di tipo Client/Server sono: il servizio DNS, dove ogni host può agire da client spedendo richieste degli indirizzi IP ai DNS server, oppure il servizio World Wide Web, e il servizio di posta elettronica, entrambi basati su client che chiedono pagine web o spediscono e-mail, e server che mantengono le informazioni o memorizzano le e-mail spedite.
-
Peer to Peer (P2P), invece, tutti gli host sono contemporaneamente sia client che server. Ogni host agisce da Server cercando di soddisfare, se possibile, le richieste ricevute da altri host. Ogni host agisce da Client quando spedisce ad altri host le sue richieste, o per conto personale, o per cercare di soddisfare richieste di terzi. Un esempio di servizi P2P sono: i servizi di condivisione dati (file-sharing) basati su protocolli Freenet, Gnutella, Kazaa. Esistono anche servizi ibridi, nei quali esistono server che aiutano solo a trovare più rapidamente gli host P2P migliori per comunicare e implementare servizi P2P (esempio: file-sharing con Napster).