4.1 Caratteristiche della Memoria
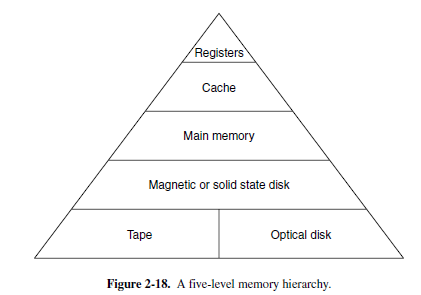
La gerarchia della memoria, più si va giù più spazio si ha, più è lento il caricamento delle informazioni
4.1.1 Catalogazione della memoria
Le tipologie di memoria sono presenti a fianco.
In generale più la memoria è veloce da riprendere, più è costosa da memorizzare (c’è poco spazio)

4.1.2 Byte e Word
Il libro a pagina 74 parte con la discussione del perché si è preferito evitare la BCD (Binary coded decimal, in cui i numeri da 0 a 9 erano codificato da 4 bit), per questioni di efficienza.
La memoria è, in modo spiccio, una serie di cellette numerate, ognuno può contenere qualche informazione. Nacque nel 1960 circa con IBM 360 nacque la definizione di byte. Word è una seguenza di byte → unità di dato che non stanno solamente in un singolo indirizzo.
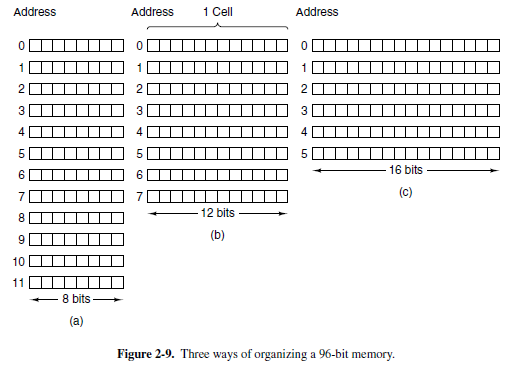
4.1.3 Endianess
Questi termini descrivono l’organizzazione dei bytes all’interno della memoria. A volte è molto conveniente netere i bytes al contrario per facilità di accesso.
4.1.4 RAM
Abbiamo presentato il funzionamento hardware della RAM nel momento in cui abbiamo descritto il funzionamento di Circuiti Sequenziali come LATCH SR, D, DFF.
4.1.5 Paginazione - Caricamento
Vedere Paginazione e segmentazione per maggiori informazioni. Una altra funzione della gerarchia di memoria è utilizzare la paginazione, ossia il caricamento di risorse utili nella ram veloce e scaricamento nella memoria secondaria di ciò che non viene utilizzato.
È gestito dal sistema operativo. Sono dei blocchi di data nella memoria principale che vengono caricati nella memoria principale nel momento del bisogno.
Quindi ci sono proprio degli algoritmi per caricare e scaricare le pagine di memoria dalla memoria principale, gestiti dal sistema operativo.
4.2 Memoria Cache
La cache è una zona di memoria condivisa alle CPU, di facile accesso (meno facile in confronto ai registri, ma comunque veloce) ma senza molto spazio.
È sempre consultata prima di andare nella memoria. Abbiamo approfondito in Cache Optimization.
Se va a cercare un word in memoria, questa viene messa nella cache dopo essere ritrovata.
Una caratteristica principale della cache è che non è necessario al programmatore sapere che esiste o meno, è solo qualcosa che si interpone in modo TRASPARENTE che può rispondere subito nel caso possieda una certa informazione.
Ma l’idea di tenere una memoria più veloce intermedia per dati più utili del prossimo futuro è una idea che si utilizza anche in altri ambiti (come Disco, accesso messaggi, e simili) e migliora molto la velocità.
4.2.1 Livelli memoria Cache

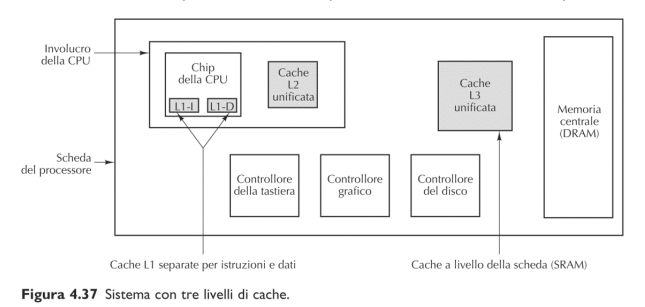
4.2.2 Principio di località spaziale e temporale
Programmi eseguiti vicini nel tempo sono messi in luoghi in memoria vicini
Si spera di guadagnare tempo in questo modo, così è più facile ritrovare delle informazioni utili quando si eseguono dei comandi vicini nella cache.
Chiaramente se un programma continua a saltare da un indirizzo della memoria a un altro questo principio non ha più senso e la cache servirebbe a poco.
Località spaziale e temporale
Un programma naturale di solito utilizza la cache (un programma potrebbe essere progettato in modo che usi 0 cache, ma sarebbe uno spreco di risorse).
Temporale: la stessa cella viene acceduta a breve distanza di tempo (come Stack). Spaziale: celle vicine possono essere prese a breve tempo di distanza. (per esempio accedere ad un array, accesso sequenziale che ha un nome suo di località sequenziale).
È molto facile che la cache debba accedere alla stessa risorsa in termini brevi di tempo
Località secondo WIKI

4.2.3 Efficienza della cache
La velocità d’accesso alla cache è di granlunga minore rispetto a quello della memoria, di solito il tempo speso per memorizzare qualcosa qui viene sempre recuperato.
Usiamo un pò di matematica ora per descrivere questa cosa un pochino più rigorosamente: $c << m$ con $c$ il tempo per accedere alla cache e $m$ il tempo per accedere alla memoria.
Allora si ha che il tempo medio per accedere alle informazioni, tenendo $h$ come hit rate è di:
$$ hc + (1 - h)(c + m) = c + (1-h)m $$4.2.4 Cache ad accesso diretto
Linee di cache, vanno k mod n, ogni linea di cache di dimensione m. ok? È una cosa temporale, a seconda di cosa ci sia ora.
Data: è effettivamente il data che sto prendendo n è il numero di linee di cache (che decide quanto grande sia la cache). Tag serve per sapere quale blocco sto utilizzando (quindi se 0-31 oppure 65536 e simili) Valid se è un blocco valido, se è 0 vuol dire che non è roba interessante.
- Esempio di query cache Teniamo 5 bit per l’indicizzazione dentro i 32 bit di data. 11 bit per sapere quale linea di cache utilizzare 16 bit per confrontare con il tag e vedere se è giusto oppure no. Così riesco a trovare in modo univoco la linea di cache che mi serve.
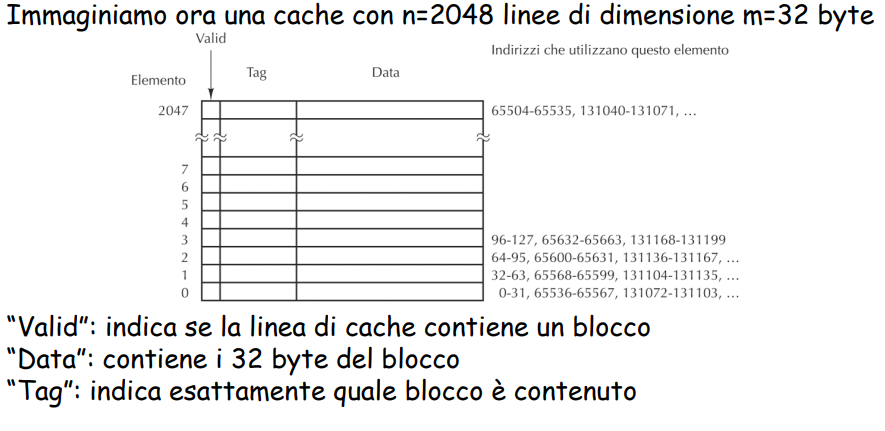
4.2.5 Cache hit and miss
Si dice che si ha un cache hit oppure cache miss a seconda del caso in cui la cache è riuscita a dare la richiesta oppure meno.
Miss
- Riportare la cache in memoria centrale in quanto potrebbe essere modificata ora, è un aggiornamento della roba nella memoria centrale
- Caricare la nuova memoria.
Se però si tenta di accedere alla cache allo stesso momento, si possono esserci data race e quindi bisognerebbe bloccare l’accesso all’inizio
Se vuoi approfondire su algoritmi per la gestione della cache:
https://en.wikipedia.org/wiki/Cache-oblivious_algorithm
4.3 Memoria secondaria
Storicamente le velocità delle CPU si sono sviluppate molto più velocemente rispetto alle memorie secondarie.
4.3.1 Hard Disk (4)
I dischi magnetici oppure Hard disk sono generalmente in tre parti:
- Settore è il nome di una traccia specifica di memoria di dimensione fissata.
- Traccia è una sequenza di bit circolari
- Testina che magnetizza e modifica il contenuto nel disco.
- Controllore Disco .
Ogni settore comincia con un preamble che dovrebbe aiutare a diminuire gli errori di lettura.
Per dare un senso, circa in un centimetro di Hard Disk ci possono stare parecchi giga di informazioni.
I dati posso essere messi in due modi:
- Stessa densità per angolo (più rientri più hai i dati in modo compatto)
- Diverso numero di settori (la parte esterna del disco contiene più settori)
Processo di recupero di dati:
- La CPU dice di andare a recuperare un blocco in un certo indirizzo di memoria
- La testina gira e va fisicamente a recuperare la zona di memoria
4.3.2 SSD
SSD or Solid State drive non hanno nessuna parte che si muove quindi sono meno soliti a rompersi meccanicamente, tutto elettronico.
Storicamente sono state utilizzate per portatili per resistenza ad urti, ma poi si possono utilizzare anche per altro data la loro velocità (per minore spazio).
4.4 RAID
https://en.wikipedia.org/wiki/Standard_RAID_levels
Redundant array of indipendend disks (originariamente inexpensive, per contrapporla a Single Large Expensive Disk ossia SLED, ma poi hanno scoperto che anche RAID costa, LMAO.
See Cloud Reliability and Redundant Array of Independent Disks.
4.5 Errori
Controllare come sono causati gli errori E tipologie di errori
Questa parte è scritta molto meglio in Rappresentazione delle informazioni
dove si parla di hamming distance e correzione errori.
4.5.1 Cause degli errori
Gli errori possono essere causati da:
- Raggi cosmici provenienti dal sole
- Vibrazioni fisiche
Esistono codici per correggere gli errori, puoi trovare più informazioni qui: Rappresentazione delle informazioni
4.6 Altri dispositivi
4.6.1 Dischi ottici
Un laser va a leggere i pattern di Pit-land e Land-pit, pit-pit presenti sul compact disk.
I dischi sono sostanzialmente uguali per quanto riguarda l’encoding di 1 e 0 ma sono diversi per quanto riguarda il materiale impiegato, il raggio impiegato **lo spazio presente fra le varie linee di informazioni (la compattezza dei bit) e simili.

4.6.2 Output-Input
Per gestire tutti i pixel c’è la necessità di avere architetture molto complicate, circa devono fare update di milioni di pixel in decimi di secondo (altrimenti l’occhio capisce che c’è la distanza)
- Core complessi per la gestione di di milioni di Pixel.
- Linguaggi di programmazione specifici perché più efficienti della CPU per programmi non grafici e.g. Cuda-C.
4.6.3 Bus per dispositivi
sono legati tramite BUS, collegamenti elettrici.
- BUS di dati
- BUS di indirizzi
I bus trasportano piccole quantità di informazioni. Si possono dividere in sotto-bus.
I bus si sono evoluti nel tempo, partendo da standard ISA (industry standard architetture) sono state creati moderni bus molto più veloci PCI, PCIe e simili.
Collegamento con memoria e CPU
- Controller collega gli attacchi ai dispositivi ai Bus che si collegano all’unità di controllo. (la scrittura sul bus è controllata dalla CPU)
- Altri dispositivi parlano direttamente alla memoria DMA mandano e ricevono degli interrupt. (se non usasse interrupt altra soluzione sarebbe continuamente inviare delle richieste per chiedere se sta ancora andando o meno)
Direct Memory Access
Di questo ne parliamo un pò meglio, anche se alla fine è lo stesso concetto in Note sull’architettura
Per saperne di più su interrupt e trap.
Sarebbe molto inefficiente leggere e inviare continuamente, quindi mettiamo un trasferimento RAM → Disco senza passare dalla CPU. Quando finisce il trasferimento il dispositivo invia un Interrupt che viene gestito subito dalla CPU interrompendo il processo corrente, iniziando un interrupt handler che gestisca eventuali errori del dispositivo e informa il sistema operativo che è finito il processo di I/O. l processo corrente, iniziando un interrupt handler che gestisca eventuali errori del dispositivo e informa il sistema operativo che è finito il processo di I/O.