Memoria virtuale
Perché è utile la MV?
I programmi non usano tutta la memoria, ma pensano di averla tutta disponibile dal suo punto di vista. L’idea principale è che molte zone di memoria sono inutili per lungo tempo, possono essere utilizzati per altro.
- caricamento codice dinamico Per esempio anche a caricare il codice di un compilatore è diviso in fasi, se andiamo a caricare tutto, stiamo utilizzando solo un pezzo piccolo, tanta inefficienza, se una pagina contiene una parte del compilatore potrei caricare in memoria solamente le parti eseguite sul momento, giusto per fare un esempio diciamo.
- Crescita dei segmenti stack, heap, ad esempio ci permette di far crescere come ci pare la stack, e anche caricare solamente le parti della stack che ci servono, e mantenere la memoria libera per altro.
- Gestione degli errori. che utilizzerà i dati solamente della parte di gestione di memoria attuale diciamo.
Paginazione a richiesta
Questo è un aspetto della cache delle pagine di cui abbiamo già parlato in Livello OS.
-
Slide paginazione a richiesta

in pratica nella cache è presente un bit, chiamato valid bit, che ci dice se la pagina correntemente caricata è valida o meno.
Se non è presente una pagina valida, allora chiamiamo trap di page fault, e il pager si occupa di caricare la nuova pagina ed aggiornare la pagina vecchia.
-
Esempio di demand paging
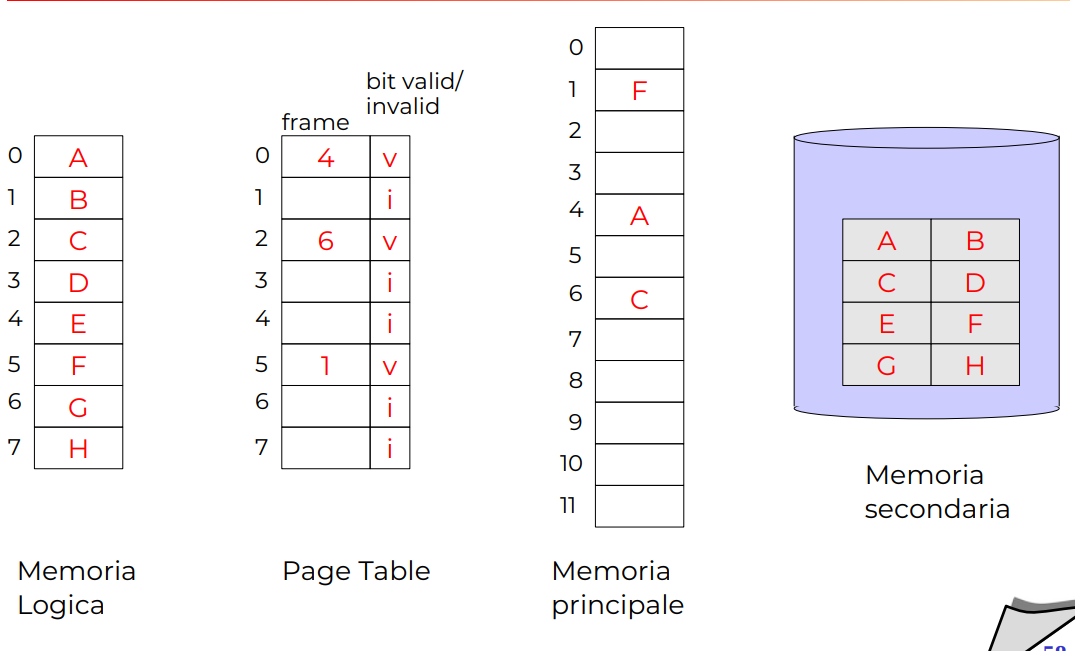
NOTA: la memoria secondaria con questo metodo ha l’intero contenuto, in questo senso la memoria principale è utilizzata come se fosse cache.
-
Esempio completo con page fault
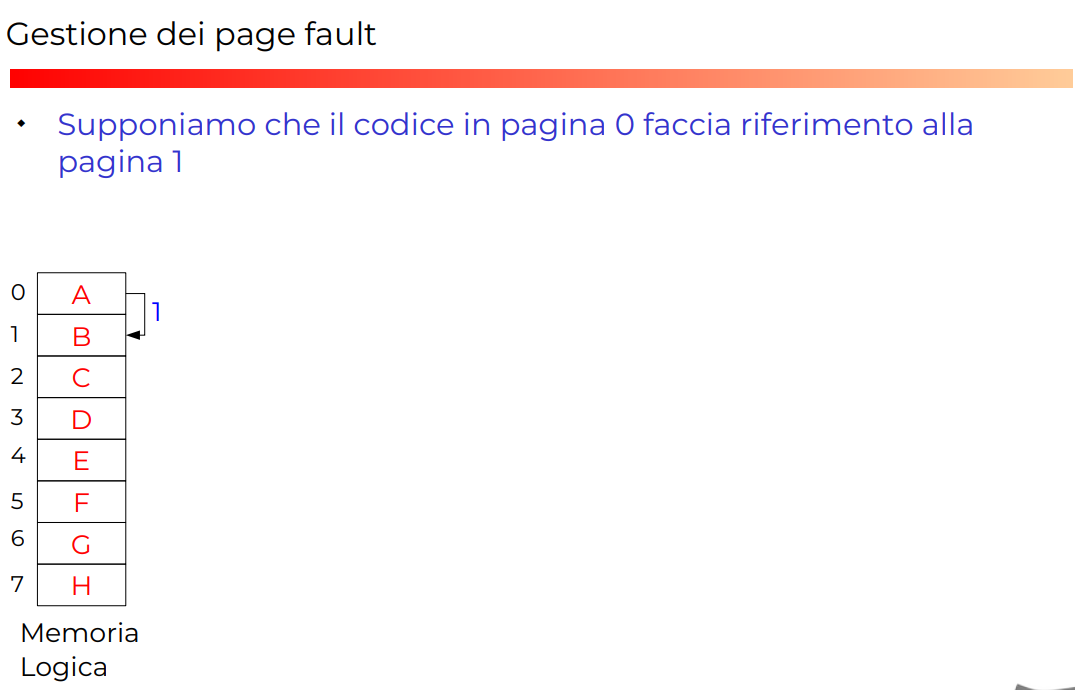
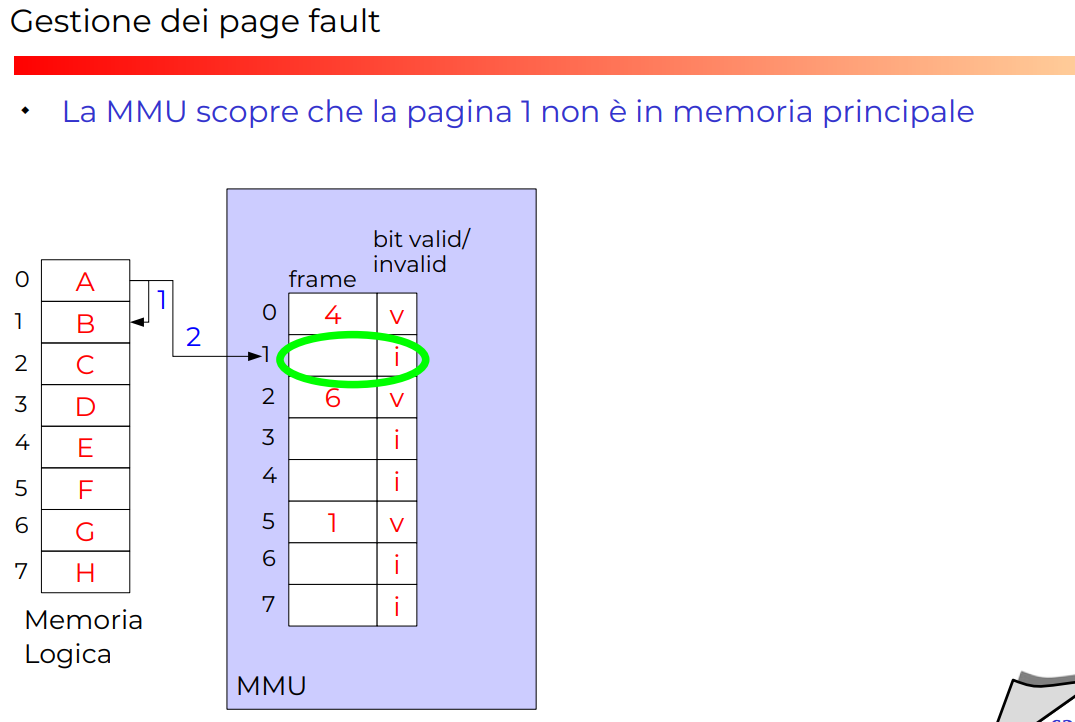
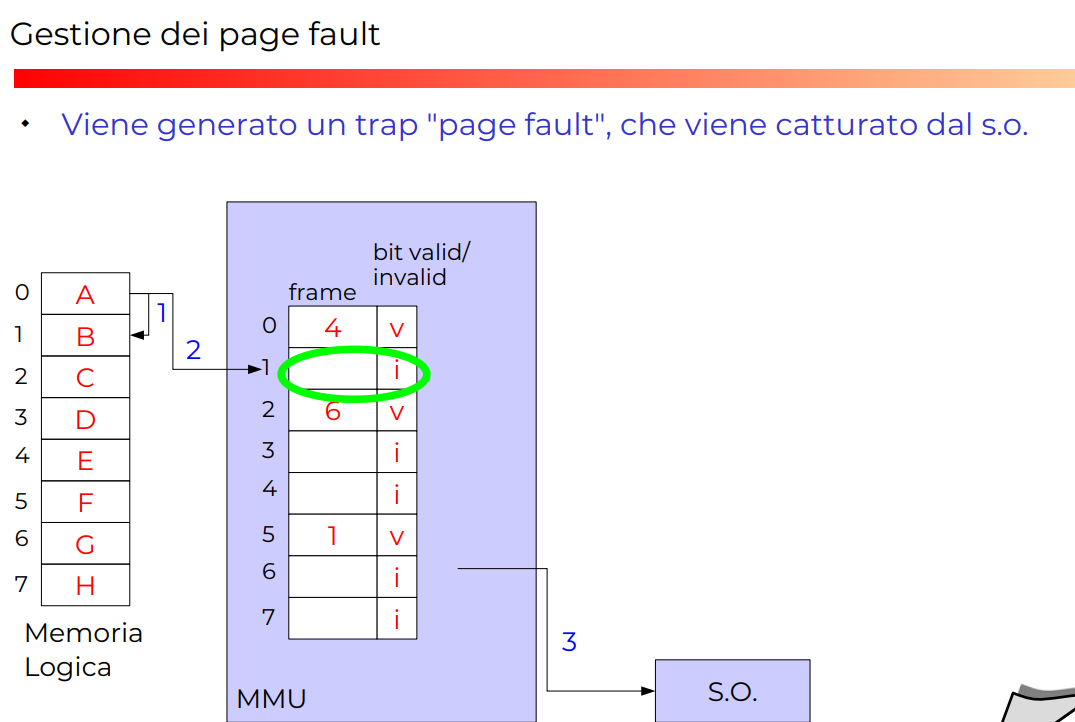
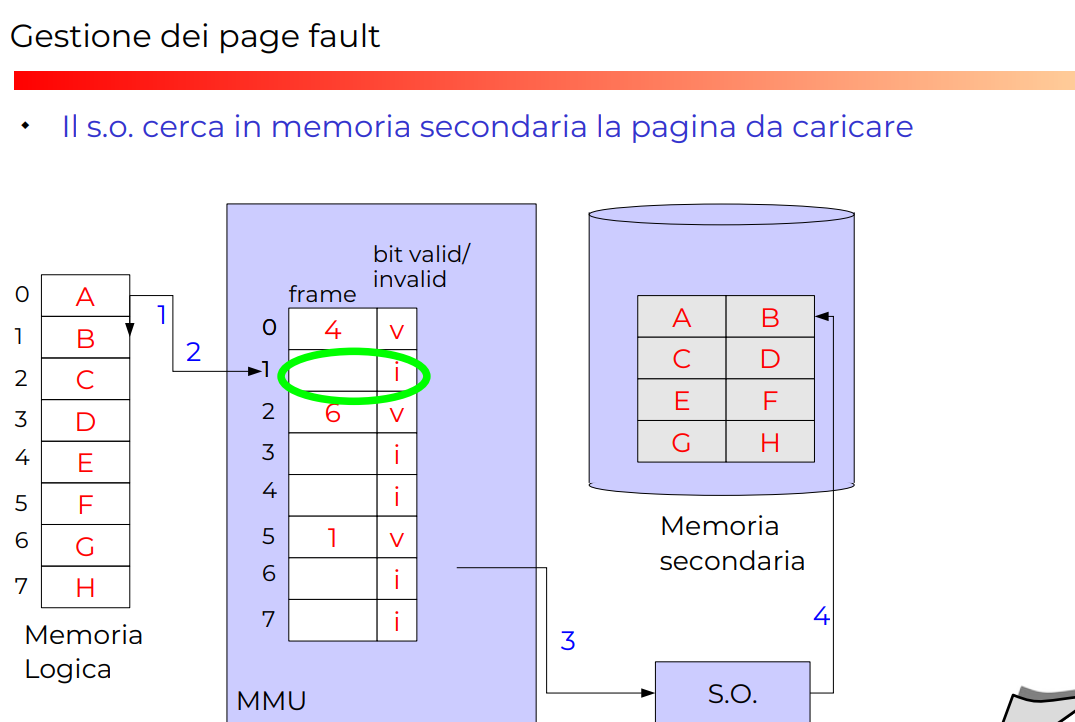
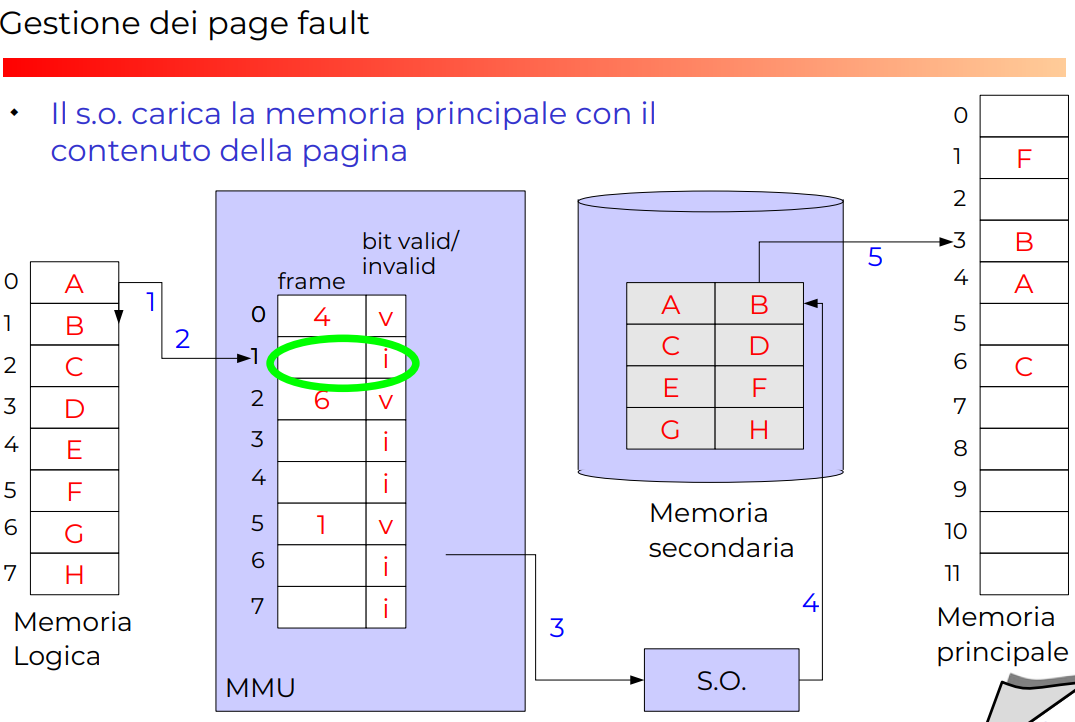
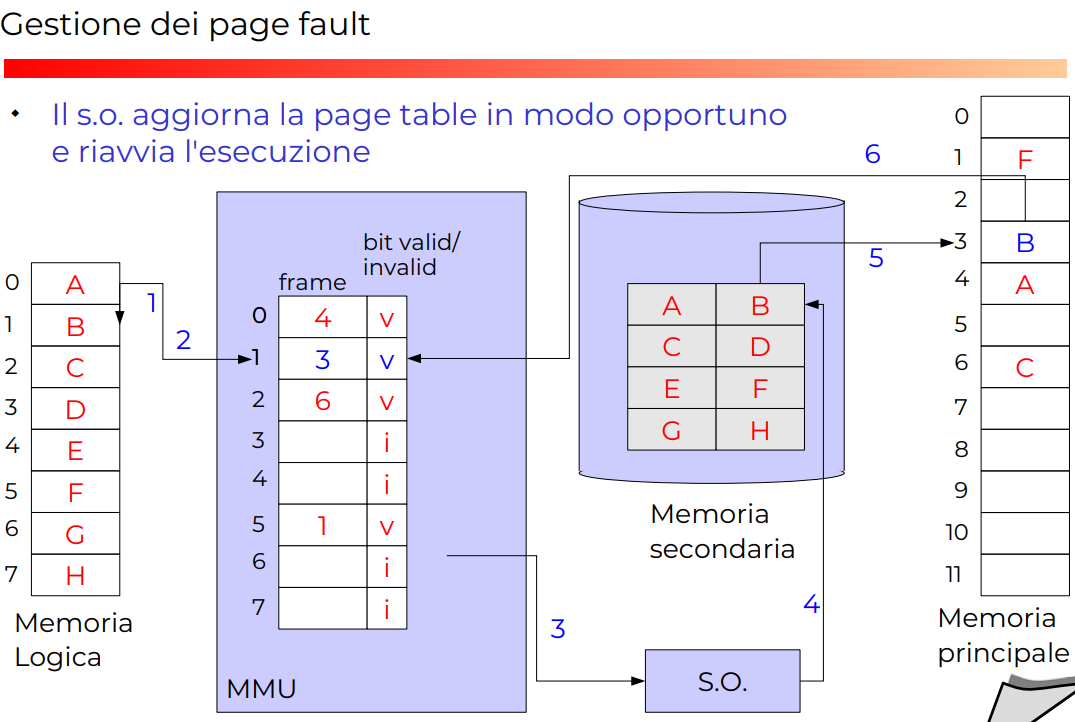
*ALGORITMO GENERALE DI DEMAND PAGING
-
Slide demand paging

NOTA: la cosa importante è il fatto che invalida subito la pagina scelta da sostituire. Non vorremmo che se un altro processo chieda quella pagina possa ancora scriverci o leggerci (e quindi problemi di concorrenza).
Memoria di Swap
In realtà quando un intero processo è caricato in memoria secondaria, questa parte in memoria secondaria è l’area di swap.
Ma questo metodo qui è come se fosse uno swap pigro. (se un processo è vecchio, nel senso che non utilizza la pagina per tanto tempo, è probabile che la sua memoria è messa in memoria secondaria).
il termine swap area per indicare l’area del disco utilizzata per ospitare le pagine in memoria secondaria
Algoritmi di rimpiazzamento
AKA Paginazione.
Obiettivo del rimpiazzamento
Quando la memoria centrale è piena, come si gestisce il processo di rimpiazzamento? In che modo si decide quale sia la pagina da togliere? Su quali basi andare a valutare per fare questa decisione?
- Utilità, nel senso meno utilizzata
- Sarà utilizzata fra più tempo.
- Minimizzare il numero di page faults possibili.
vorremmo evitare di togliere e rimpiazzare subito.
NUMERO DI FRAME E PAGE FAULTS
Non è che il numero dei frame aumenta implica che il numero di faults sia minore? Ma stranamente non è sempre così, gli algoritmi di rimpiazzamento potrebbero fare peggio se hai troppa memoria, per esempio [Algoritmi FIFO
Questo fenomeno è proprio studiato, ed è conosciuto nel nome di [[Anomalia di belady
Stringa di riferimenti
È la sequenza degl iindirizzi di memoria al quale un processo accede durante la sua esecuzione, (ci importa solamente il numero di pagina!) Questo ci dà un criterio per valutare quanto buona è una pagina in memoria
-
Slide stringa di riferimenti

Algoritmi FIFO
Questo l’abbiamo studiato anche in [[Scheduler](/notes/algoritmi-fifo-
questo-fenomeno-è-proprio-studiato,-ed-è-conosciuto-nel-nome-di-[[anomalia-di-belady-
###-stringa-di-riferimenti-
è-la-sequenza-degl-iindirizzi-di-memoria-al-quale-un-processo-accede-durante-la-sua-esecuzione,-(ci-importa-solamente-il-numero-di-pagina!)-questo-ci-dà-un-criterio-per-valutare-quanto-buona-è-una-pagina-in-memoria
–slide-stringa-di-riferimenti
—-<img-src="/images/notes/image/universita/ex-notion/memoria-virtuale/untitled-9.png"-style=“width:-100%"-class=“center”-alt=“image/universita/ex-notion/memoria-virtuale/untitled-9”>
—-<img-src="/images/notes/image/universita/ex-notion/memoria-virtuale/untitled-10.png”-style=“width:-100%"-class=“center”-alt=“image/universita/ex-notion/memoria-virtuale/untitled-10”>
###-algoritmi-fifo-
questo-l-abbiamo-studiato-anche-in-[[scheduler), oppure Data Plane per i routers.
Praticamente la pagina che dovrà uscire sarà la pagina in memoria da piu`tempo. Ma non è detto che la pagina caricata da più tempo sia anche poco utilizzata! potrebbe essere ancora utilizzata!
-
Esempio di paginazione fifo

-
Esempio paginazione 2 fifo

-
Esempio brutto, di maggiori faults con aumento memori

Anomalia di belady
-
Slide anomalia di belady
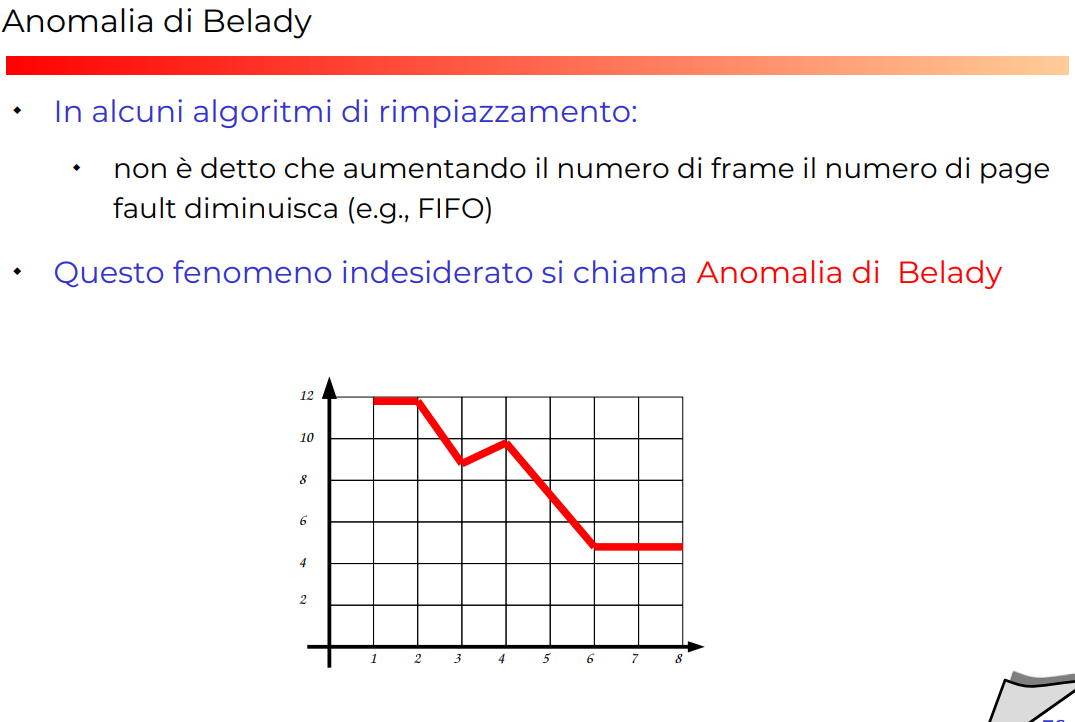
Un buon algoritmo di rimpiazzamento dovrebbe essere immune a questa anomalia! Perché non avrebbe senso che aggiungere memoria renda il sistema più lento!
In questo paragrafo: Implementazione a stack parliamo di una condizione sufficiente affinché non si verifichi questa condizione.
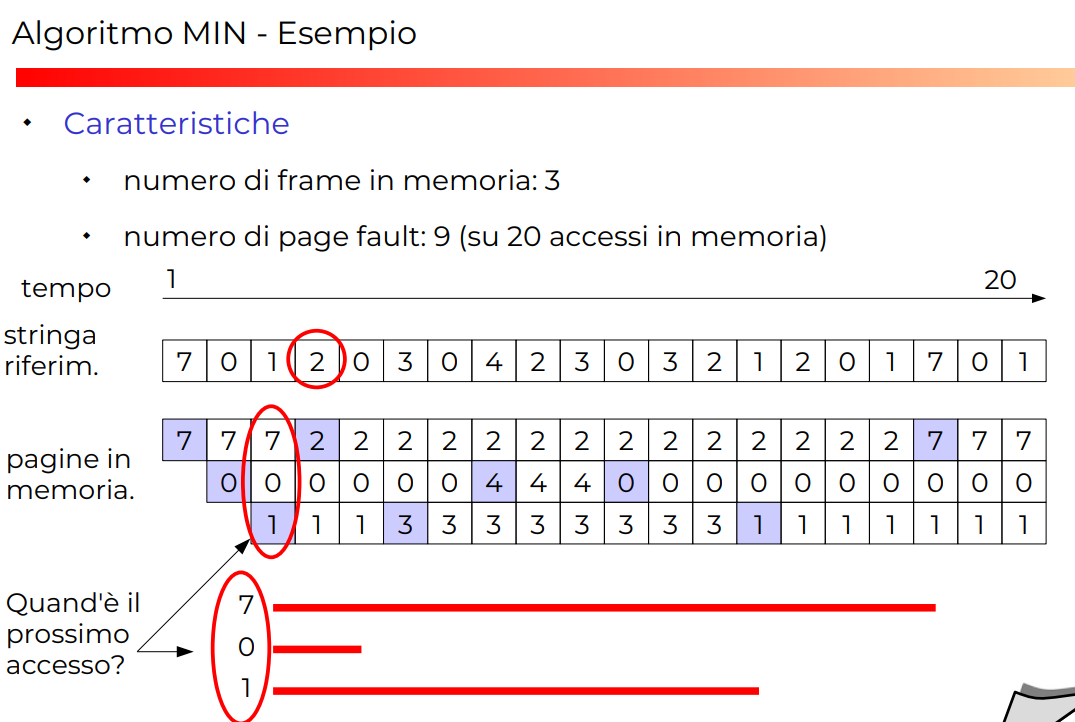
Algoritmo MIN
Questo è l’algoritmo ottimale, ma utilizza informazioni che non abbiamo già, perché non sappiamo quando i processi accederanno a cosa. Quindi buon algoritmo in teoria (perché utilizza informazioni che non abbiamo ancora nel presente), nessun uso ora.
Però si può dimostrare che questo algo genera il minor numero di faults.
Seleziona come pagina vittima una pagina che non sarà più acceduta o la pagina che verrà acceduta nel futuro più lontano
È un buon algoritmo per utilizzare come paragone di altri algoritmi reali, cioè questi reali quanto bene fanno rispetto a questo algoritmo perfetto!
-
Slide algoritmo MIN
Least Frequently used
-
Slide LFU

Ma solitamente questo, come FIFO, non è che venga utilizzata.
Vado a considerare il concetto di frequenza, definita in questo modo: contatore / tempo di permanenza in memoria.
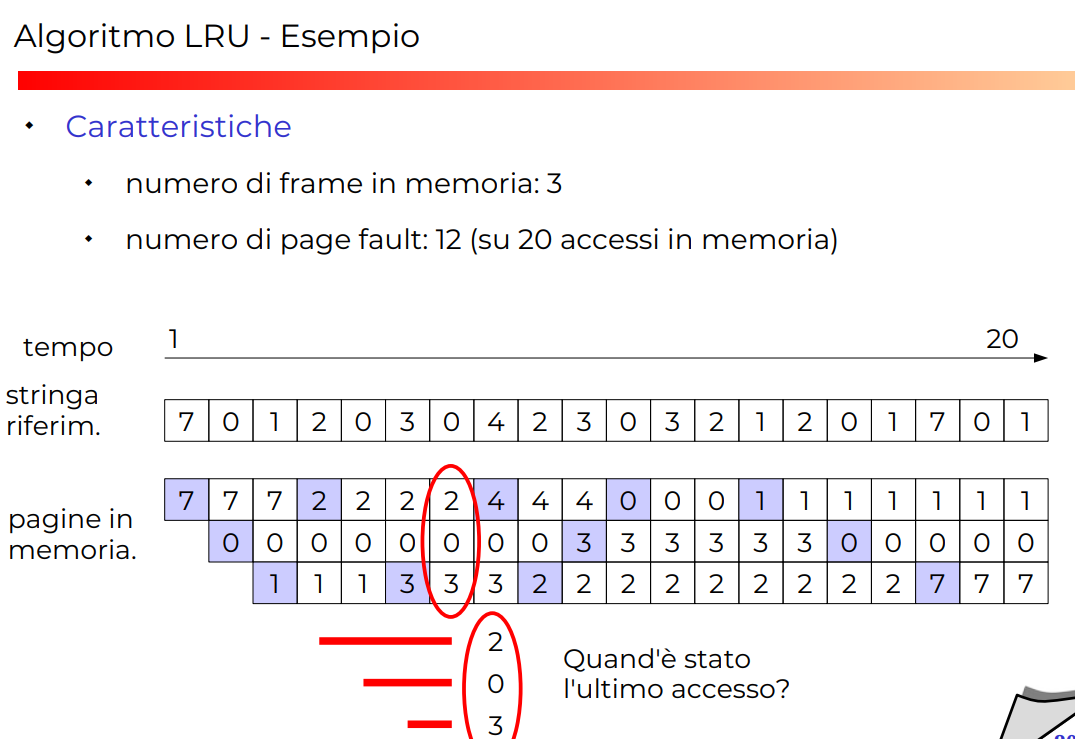
Algoritmo di LRU
Per le cache, ci sono algoritmi migliori di LRU, vedere Content Delivery Networks. Ne abbiamo parlato anche in architettura, qui Paginazione e segmentazione.
seleziona come pagina vittima la pagina che è stata usata meno recentemente nel passato
In pratica provo a stimare l’utilizzo della pagina in base a quanti accessi abbia fatto in passato.
-
Esempio LRU
Implementazione LRU
Come facciamo a capire quanto spesso è stato utilizzato una pagina? Non possiamo mica aggiungere il numero di accesso a tutte le risoluzioni MMU, deve essere implementato in hardware stesso, in MMU.
-
Slide implementazione MMU

-
Accessi in memoria in più
-
La MMU dovrebbe tenersi i timestamps e dovrebbe gestire gli overflows
-
O(n) per scandire la tabella di frame, e trovare la pagina
Quindi è molto lenta, ma almeno è realizzabile.
IMPLEMENTAZIONE A STACK
Ossia quando accediamo una pagina, la mettiamo sopra la stack. Ma è brutto perché in hardware dovrei aggiornare 6 puntatori, che non dovrebbe essere cosa da niente, per questo non è utilizzato.
La cosa carina però è che avrei in cima le cose utilizzate in basso quelle meno utilizzate!
Implementazione a stack
-
Slide definizione di algoritmi a stack

Si noti che la condizione è molto simile a una sufficiente per risolvere la condizione di belady, ci sta dicendo che in pratica: l’insieme delle pagine mantenute in memoria è contanuto allo stesso algoritmo con più pagine in memoria!
È anche una condizione sufficiente per dire: avere fage faults in meno, non più, perché contiene sempre le stesse pagine con una versione a più.
Per dimostrare che FIFO non è a stack, basta un esempio.
ACCENNO DIMOSTRAZIONE LRU È STACK
Si utilizza una dimostrazione costruttiva per induzione (altra tecnica è per assurdo). Questo lo facciamo sul tempo.
- Passo base: al tempo 0 la stack è vuota, non ci importa quale numero di stack, la memoria resta la stessa.
- Supponiamo al tempo t-1 che la condizione di stack sia verificata.
Ora abbiamo due casi: non c’è abbstanza spazio, o c’è ancora spazio:
- Se c’è abbastanza spazio, allora non ci cambia per un m numero di frame maggiore
- Se non c’è abbastanza spazio, quello minore deve cambiare, dovrà scegliere uno a caso, scegliendone uno a caso allora l’insieme delle pagine è ancora incluso. Al passo successivo ancora, l’elemento che esce dovrà essere lo stesso, o comunque offsettato non di tanto credo, in pratica quello grosso elimini cose solamente eliminate già da quello piccolo!. E questa cosa con LRU l’abbiamo. Non è che ho formalizzato molto bene questa parte.
Additional reference bit
Andiamo ora a parlare di approssimazione di LRU perché col discorso a stack non è proprio fattibile con l’hardware attuale.
Quando accedo a una pagina, il bit viene messo a 1, inizialmente sono tutte 0, meglio descritta nella slide:
-
Slide descrizione reference bit

basta fare shift e assegnamento! Quindi easy! Andiamo a prendere la pagina con valore minore poi.
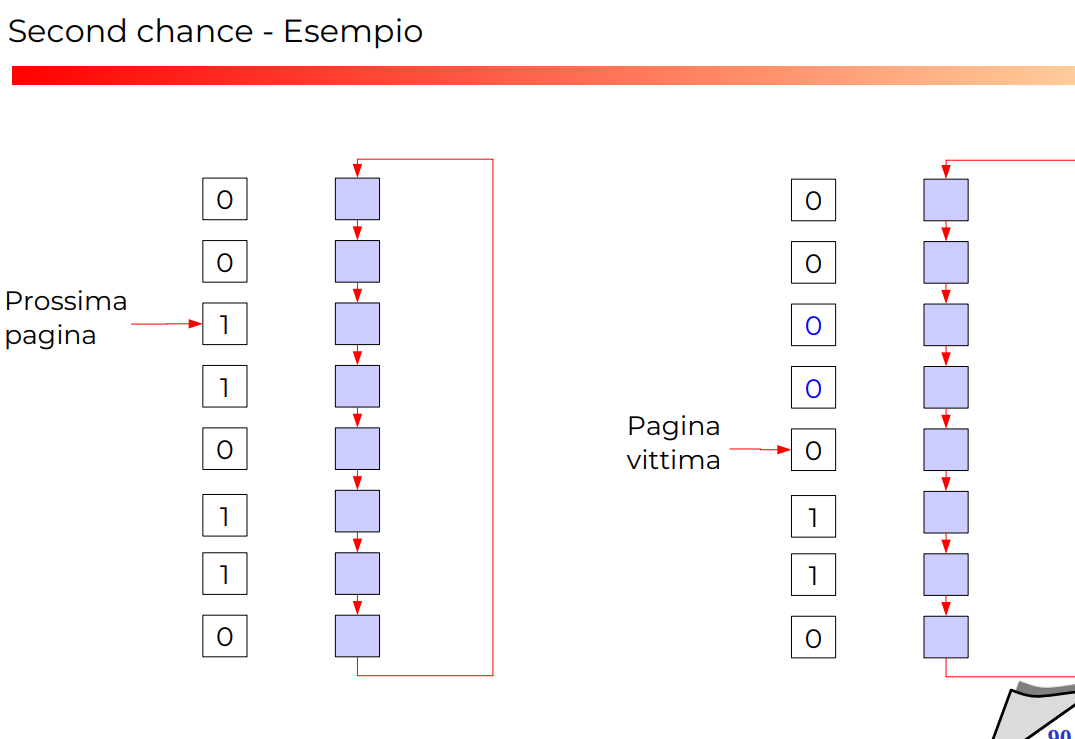
VARIANTE: SECOND CHANGE ALGO
-
Slide second change (storia = 1)

Vengono gestiti come una lista circolare, per questo motivo è anche detto algoritmo dell’orologio.
In pratica scandisco la lista con questo algo:
- Bit a 1? Allora lo metto a 0 e vado avanti
- Bit a 0? Allora tolgo questa! E sostituisco.
-
Esempio di second change algo
Non si capisce sto esempio lol
Allocazione della memoria virtuale
Tipologie di allocamento (3)
-
Slide allocazione

- Algo di allocazione: risponde alla domanda su come allocare i frame per un certo processo.
- Allocazione globale: permetto di allocare l’intero programma (male → thrashing)
- Allocazione locale: il processo è a conoscenza dei propri frame, ma non è molto flessibile, di solito fanno meglio quelli globali,
Praticamente fin’ora abbiamo parlato di metodi per sostituire delle pagine in caso di page faults, ma non abbiamo mai definito in che modo decidiamo quanti frames allocare a un processo, nel momento del bisogno. Allocazione globale e locale sono dei modi per fare questa decisione.
- Locale → implica che posso sostituire solamente i frames del mio processo, in queto senso sono poco flessibile, se qualcun’altro ha più roba che posso sottrarre converrebbe fare quello.
- Globale → implica che posso sostituire i processi di chissivoglia.
Normalmente si utilizzano anche delle euristiche per sapere quante pagine allocare: per esempio se ho troppi page faults, probabilmente il processo ha bisogno di più memoria, se ne ho troppi pochi probabilmente il processo ne ha troppa, e si può allocare ad altri.
Thrashing
un processo (o un sistema) si dice che è in trashing quando spende più tempo per la paginazione che per l’esecuzione
Questo è quindi un effetto molto brutto! Va a finire che l’intero sistema si impalli. rubano le pagine a vicenda, l’effetto più classico è questo: non riescono a tenere in memoria i frame utili a breve termine (perchè altri processi chiedono frame liberi) e quindi generano page fault ogni pochi passi di avanzamento) In pratica quasi ogni operazione è un page fault.
Per evitare questo, massimo 2x memoria virtuale, altrimenti potrei andare in thrashing.
-
Esempio di effetto di thrashing

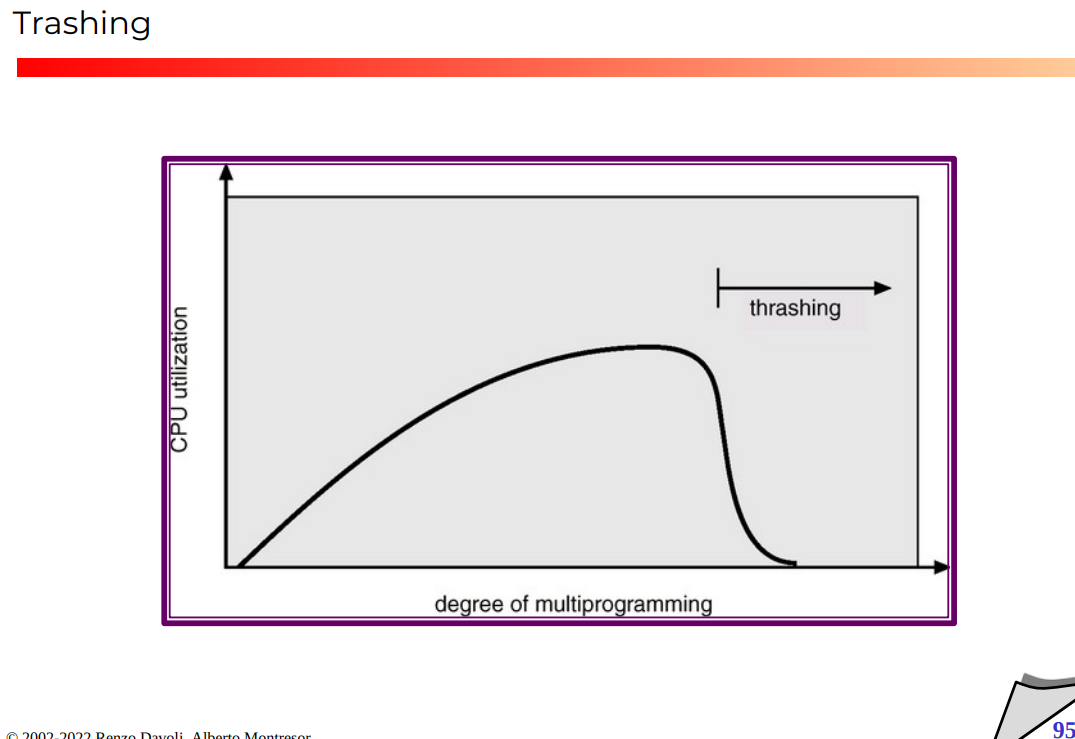
L’efficienza cade di interi ordini di grandezza!
Working set
si definisce working set di finestra Δ l’insieme delle pagine accedute nei più recenti Δ riferimenti
Questo è utile per stimare se il sistema è in thrashing. Questo è utile per avere un concetto di località delle pagine, vogliamo avere una stima delle pagine attualmente utili, e utilizziamo questo per andare a decidere se una pagina è ancora utile o meno.
-
Slide valutazione working set per thrashing

Se la somma di tutti i pages di cui ho bisogno nel breve è maggiore di più pagine presenti in RAM, allora sicuramente quando questa si riattiva crea page faults! Ecco il criterio per i page faults.
-
Scelta del delta

SOLUZIONE PROPOSTA
Basta sospendere alcuni processi, in modo che alcuni terminino senza andare in troppi page faults, in modo che la somma di tutti working set stiano ancora dentro.
-
Slide della soluzione
