Introduzione ai metodi di discesa.
Generali sui metodi di discesa
Vogliamo creare algoritmi che riescano a trovare i punti di minimo delle funzioni non vincolate.
In generale si trova un punto stazionario (condizioni necessarie) ma non è garantito lo stato ottimo.

Solitamente sono divisi in first order methods in cui viene considerata solamente la derivata prima della funzione. E cose di metodi superiori.
Condizioni di arresto classiche (2)
-
Slide


- Differenza fra due iterati è minore a una tolleranza, in modo simile a quanto fatto in Equazioni non lineari sulla tolleranza per il metodo delle approssimazioni
I criteri di arresto sono i sempre classici
- Numero di iterazioni superate
- Tolleranza sull’obiettivo ossia gradiente $\simeq$ 0 per il punto di stazionarietà.
Idea principale dei metodi di discesa
-
Slide

- Trovare una direzione di discesa
- Aggiornare x in modo da andare in quella direzione di un passo fissato. direzione di ricerca e lunghezza del passo sono due nuovi termini di interesse per questa roba
Ottimizzazione non vincolata (non studiare)
In pratica questa parte è un ripasso molto veloce di 2 mesi di analisi 2… E poi ovviamente fatti molto male!
Guarda Massimi minimi multi-variabile. In pratica ottimizzazione è trovare il massimo o il minimo di una funzione…
Discesa
Condizione per direzione di discesa
-
Slide

Si può osservare che io stia proprio scendendo, in questo senso vado a cercare qualcosa che sia uguale a 0.
-
Interpretazione geometrica della condizione di discesa

Se forma angolo ottuso con il gradiente è OK!
E guardare le curve di livello è una cosa molto buona.
Algoritmo generale di GD
-
Slide

Si può notare che la scelta del passo è la parte critica di questo algoritmo. Scegliere un alpha fisso non garantisce la convergenza, devono essere soddisfatte certe proprietà.
Ricerca dell’alpha
Scelta della alpha (linea esatta)
-
Definizione di funzione dipendente da alpha


Vado a scegliere l’alpha in modo tale che assuma il valore più piccolo possibile, significa minimizzare questa funzione di alpha.
Solitamente si utilizza quando f è in forma quadratica, per resto spesso non si utilizza (perché la f si calcola in modo molto veloce, di solito è molto lento. dimostrato converge! punto minimo o massimo boh.
linea inesatta
-
Slide

Quindi inesatta perché devo trovare l’insieme di alpha buoni, non quell preciso
Condizioni di Wolfe
Due funzioni costituiscono le condizioni di Wolfe:
- Condizione di Armijo: $f(x_{k} + \alpha p_{k}) \leq f(x_{k}) + c_{1}\alpha \nabla f(x_{k})^{T} p_{k}$ assicura una decrescita sufficiente di $f$ nella direzione trovata $p$. Questa condizione è anche chiamata condizione della decrescita sufficiente.
- Condizione della curvatura: $\nabla f(x_{k} + \alpha_{k} p_{k})^{T} p_{k} \geq c_{2} \nabla f(x_{k})^{T} p_{k}$ impedisce che $\alpha_{k}$ diventi troppo piccolo.
- Slide
Armijo e backtracking
-
Intro a backtracking

-
backtracking

-
L’algoritmo
NOTA: bisgona anche mettere una condizione di maxit, se si esce per quella allora è perché non si può trovare! (molto probabilmente)

Condizioni di ottimalità
Definizione
Quando sono in un minimo locale o globale per la nostra funzione.
Andiamo a definire una condizione di ottimalità di primo secondo oordine perché andiamo a guardare le derivata
Condizione necessaria e sufficiente al primo e secondo ordine
Primo ordine
Questo non è altro che il teorema di fermat del secondo ordine che puoi trovare qui 11.1.2 Condizione di stazionarietà (fermat) !!!-!!!)
-
Slide

Non esiste una condizione sufficiente al primo ordine
Secondo ordine
Questo è il modo con cui trovavamo i punti di minimo, è anche una condizione sufficiente se è definita positiva
Ottimalità per funzioni convesse !

Funzioni quadratiche
Questo tipo di funzioni ci piace molto perché sono convesse e le funzioni convesse sono facili da analizzare per sta robba.
Quadratiche convesse
-
Slide

Con $Q$ matrice simmetrica
Con $q$ convessa se la matrice è semidefinita positiva, e convessa stretta se è definita positiva.
Questa funzione ci può essere utile per la risoluzione dei Minimi quadrati. Quando mi calcolavo la norma quadrata per quel problema, avevo una funzione quadratica convessa (quasi, credo che il termine noto non fa male)!
Soluzioni eq. normali
-
Slide

Con la roba di sopra dimostro anche che una soluzione ottima (ricorda che è ottima anche una soluzione locale) esiste sempre.
Metodo di newton puro
L’unica cosa che cambia nello step di newton è che la direzione di discesa è calcolata in modo differente, in particolare possiamo vedere che lo step sia:
$p_k = H(x_k) ^{-1} \nabla f(x_k)$, le ragioni sono sconosciute (a me), e non è conveniente in termini di tempo provare a capire questo. lo step è sempre di 1.
- La velocità di convergenza è quadratica come nel caso descritto per newton in Equazioni non lineari.
L’hessiana solitamente contiene informazioni sulla curvatura che permette, soprattutto nei casi in cui la nostra funzione è quadratica, di convergere più velocemente (invece di oscillare tanto, probabilmente va diretto nel minimo).
Ripasso (roba di analisi)
Derivata parziale
Guardare Calcolo differenziale. Ma è una roba troppo base sta roba 😑
Hessiana
Questa matrice ci da informazioni sulle derivate seconde
- Matrice simmetrica
- derivata $ij$, prima derivo su $i$, poi su $j$.
Ricordarsi il teorema di Schwarz, che è sufficiente per dimostrare che la matrice è simmetrica
Jacobiana
Questa ci da informazioni sulle derivate prime per tutti i modi possibili!
$f: \mathbb{R}^n \to \mathbb{R}^m$, $J(f) : \mathbb{R}^n \to \mathbb{R}^{m\times n}$
- In particolare sulle righe ho tutte le derivate parziali possibili
- Sulle colonne ho la derivata fatta su tutte le funzioni possibili
Analogo minimimo massimo
Se ho il massimo e voglio il minimo, basta costruirsi la funzione swappata
$$ \arg \max_{x} f(x) = \arg \min_{x} - f(x) $$Teorema sulle funzioni differenziabili
Calcolo differenziale Spiega bene questo teorema, con
Se le derivate parziali esistono e sono continue, allora la funzione si dice differenziabile con continuità $C$.
Punti di minimo locali e globali
Globale
Quando è minimo per tutto il dominio.
Locale
Se è un punto di minimo globale con dominio ridotto ad un intorno (basta che esista un interno).
Funzioni convesse
Questa parte è trattata in analisi in Convessità (cenni)%20b097c1a254f84bd3926b796fb1179c89.md)
-
Slides
!
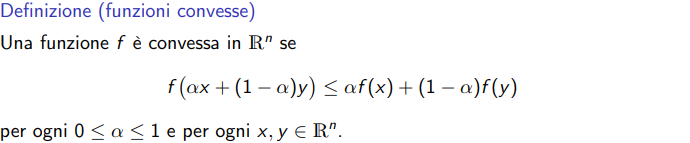
-
Slide
!
