Introduzione a Naïve Bayes
NOTE: this note should be reviewed after the course I took in NLP. This is a very old note, not even well written.
Bisognerebbe in primo momento avere benissimo in mente il significato di probabilità condizionata e la regola di naive Bayes in seguito.
Bayes ad alto livello
Da un punto di vista intuitivo non è altro che predire la cosa che abbiamo visto più spesso in quello spazio

Assunzioni principali per naïve Bayes
- I sample di input sono condizionalmente indipendenti uno con l’altro. Questo permette di utilizzare questa ipotesi $$ P(X_{1}\dots X_{n} | Y = y_{i}) = \prod_{i}^{n} P(X_{i} | Y) $$ E permette di rendere la parte di inferenza anche molto semplice perché per classificare un caso basta prendere label con la probabilità maggiore. che è dato solamente dal numeratore durante la regola di Bayes.
Tecnica generativa
La distinzione fra generativa e discriminativa è fatta in Introduction to machine learning. Ossia cerchiamo di capire come si distribuiscono i dati? (ossia prova a capire le probabilità che abbiano generato questi dati). Mentre in modelli supervisionati classici si potrebbe dire che provano a capire $Y$ assumendo i dati esistenti di training.
Prova a capire $P(X|Y)$ diciamo e poi da questo si può ricalcolare $P(Y | X)$ grazie alla formula di Bayes una volta capito $P(X)$ e l’altro.
$$ P(Y | X) = \frac{P(X|Y)P(Y)}{P(X)} $$Classificazione lineare Bayes
Si viene a scoprire che Naïve bayes alla fine fa classificazione lineare, che ci dice che è un modello molto molto semplice.
$$ \frac{P(Y = 1, X_{1}\dots X_{n} = \vec{x})}{P(Y = 0, X_{1}\dots X_{n} = \vec{x})} = \frac{P(Y = 1 | X_{1}\dots X_{n} = \vec{x})}{P(Y = 0 | X_{1}\dots X_{n} = \vec{x})}\geq 1 $$La prima uguaglianza di sopra è ottenuta osservando che $P(Y=1, X_{1}, \dots, X_{n} = \vec{x}) = P(Y=1 | X_{1}, \dots, X_{n} = \vec{x}) \cdot P(X_{1}, \dots, X_{n} = \vec{x})$ E poi semplificando entrambi.
$$ \log \frac{P(Y=1)}{P(Y=0)} + \sum_{i} \log \frac{P(X_{i} = x_{i} | Y=1)}{P(X_{i} = x_{i} | Y=0)} \geq 0 $$E usando un trucco lo facciamo diventare lineare (vedi slide 126)
Notiamo che una funzione da booleani a booleani si può approssimare come
$$ f(x) = x f(1) + (1 - x) f(0) $$$$ \theta_{ik} = P(X_{i} = 1 | Y = y_{k}) $$Non so in che modo possa essere estesa ad altri casi, ma nel caso booleano funziona Quindi unendo le due cose abbiamo:
$$ \sum_{i} \log \frac{P(X_{i} = x_{i} | Y=1)}{P(X_{i} = x_{i} | Y=0)} = \sum_{i}x_{i} \log \frac{\theta_{i1}}{\theta_{i0}} + \sum_{i} (1 - x_{i}) \log \frac{1 - \theta_{i1}}{1- \theta_{i0}} $$Assumendo che $f(x) = \log \frac{P(X_{i} = x | Y=1)}{P(X_{i} = x | Y=0)}$ Vediamo da sopra che è lineare.
Caso continuo
Introduzione modellazione nel caso continuo
Per ora abbiamo sempre assunto che le classi da predire fossero discreti, però si può utilizzare anche in un caso continuo, e in questo caso si usa una gaussiana.
- Scegliamo una legge gaussiana perché naturalmente se sommiamo un sacco di distribuzioni, verrà che sarà una gaussiana.
- Legge dei grandi numeri, quindi è una fra le distribuzioni più naturali.
- È la distribuzione con entropia maggiore fra tutte le distribuzioni con data media e varianza.
- Se si hanno altre informazioni, sarebbe molto più sensato utilizzare una altra distribuzione, ma introdurrebbe un bias di un certo tipo.
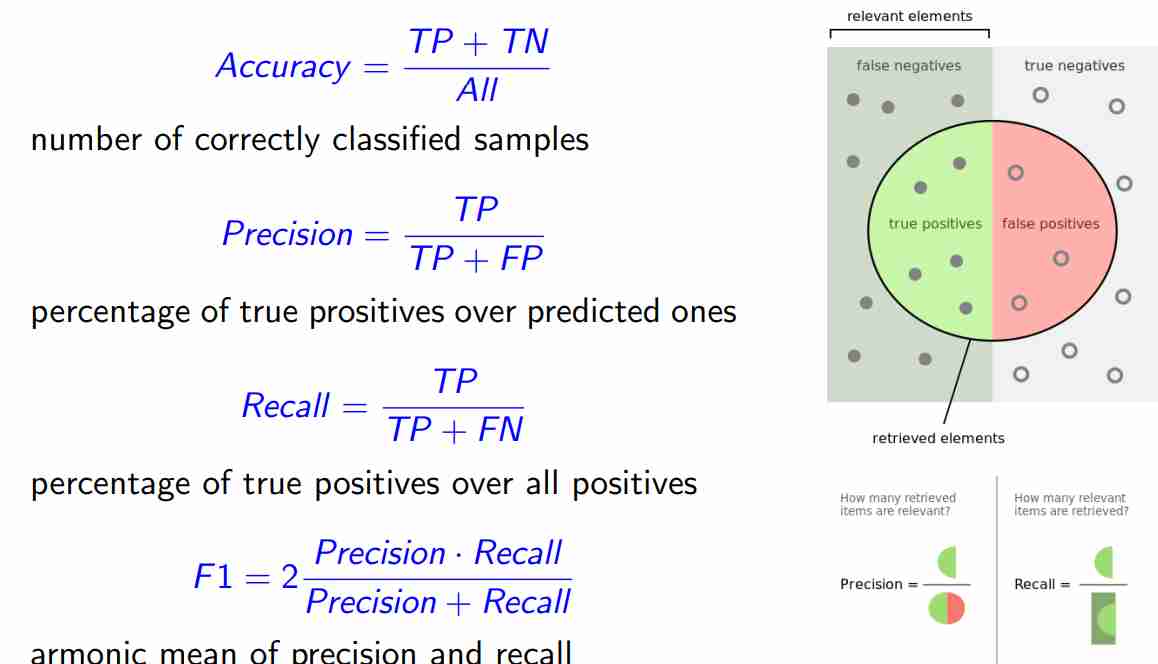
Metriche TP FP TN FN
Questa parte è molto importante per sapere quali metriche siano importanti, riguardo
- True positives
- False positives
- True Negatives
- False positives
E con queste possiamo definire concetti come accuratezza, recall e precisione
Inferenza nel caso continuo
Sembra molto simile a una Gaussian Mixture Model, perché alla fine è una interpolazione in un certo senso, solo che è motivato in modo diverso.

Training nel caso continuo
 E probabilmente si può dimostrare, facendo un ragionamento come Maximum Likelihood extimate anche in questo caso.
E probabilmente si può dimostrare, facendo un ragionamento come Maximum Likelihood extimate anche in questo caso.
Algoritmo di fitting
 Si tratta quindi di creare tutti i parametri $\theta_{ijk}$, anche se in questo momento non sto capendo in che modo
Si tratta quindi di creare tutti i parametri $\theta_{ijk}$, anche se in questo momento non sto capendo in che modo
Al fine di stimare questo usiamo maximum likelihood extimate. Guardare #Sul MLE sotto per capire in che modo sono stimati.
Stima P(Y)
Poniamo la cosa più banale, la stima di $P(Y = y_{i})$ è solamente la percentuale delle labels che abbiamo, ossia
$$ \pi_{i} = P(Y = y_{i}) = \frac{\#D(Y = y_{i})}{\lvert D \rvert} $$Utilizziamo $\pi$ per scrivere in modo più veloce la probabilità del singolo label.
Stima parametri P(X|Y)
$$ \theta_{ijk} = P(X = x_{ij} | Y = y_{k}) = \frac{\#D(X_{i} = x_{i,j} \cap Y = y_{k})}{\#D(Y=y_{k})} $$Edge cases (2)
Probabilità id zero: Non vogliamo avere che $P(X_{i}|Y) = 0$ perché produrrebbe sempre nullo (questo succede per esempio per i modelli di testo mi pareva), è improbabile che sia 0 perché noi per ora ci stiamo concentrando su una stima, una cosa che fanno è aggiungere sempre almeno un esempio perché così non ho una probabilità nulla per tutto in questo caso.
Casi non indipendenti Questo è molto difficile da gestire, dipende da come abbiamo generato i dati, quindi è esterna a questa fase di scelta del modello diciamo. Bayes è probabilmente non molto utile in questi casi, perché questo caso viola l’assunzione iniziale, si dovrebbe probabilmente fare preprocessing per cercare di limitare la dipendenza.
Maximum Likelihood estimation
Di questo parleremo molto meglio in Parametric Modeling.
Introduzione al problema
C’è una parte teorica molto più interessante per quanto si tratta di maximum likelihood estimation. Andiamo a giustificare il motivo per cui stime molto semplici ed intuitive come quelli presenti in #Stima P(Y)) e #Stima parametri P(X Y)) possono funzionare. Ci chiediamo in questa istanza quale sia il caso più probabile ossia quello con maximum likelihood
MLE su bernoulli
Supponiamo di avere $n$ lanci con una moneta unfair, ossia $p(X) \neq 0.5$ di avere testa. Date certe osservazioni, quale è il valore più probabile di $P(X)$?
Consideriamo $X^{n}$ la variabile aleatoria che misura il numero di 0 all’interno del nostro problema, allora questo segue la legge di Bernoulli.
$$ P(X^{n} = \alpha_{0} | \theta) = \binom{n}{\alpha_{0}} \theta^{\alpha_{0}} (1 - \theta)^{n-\alpha_{0}} $$Seguendo l’idea del più probabile quello che noi stiamo cercando è
$$ \hat{\theta} = \arg\max_{\theta} P(X^{n} = \alpha_{0} | \theta) $$Soluzione problema analitico Prendiamo il logaritmo, che non cambia il nostro massimo, dato che è monotona, ma ci semplifica un sacco l’analisi
$$ \ln(\theta^{\alpha} (1- \theta)^{n - \alpha }) = \alpha \ln \theta + (n- \alpha) \ln(1 - \theta) $$Derivando rispetto a $\theta$ abbiamo che
$$ \frac{\alpha}{\theta} - \frac{n - \alpha}{1- \theta} = \frac{\alpha - \alpha \theta - (n - \alpha) \theta}{\theta (1 - \theta)} $$$$ \alpha - \alpha \theta - (n - \alpha) \theta = 0 \implies \theta = \frac{\alpha}{n} $$E se ben ricordiamo, $\alpha$ non era altro che il numero di samples negativi, quindi questo è un esempio locale in cui MLE è la soluzione ottimale per stimare.