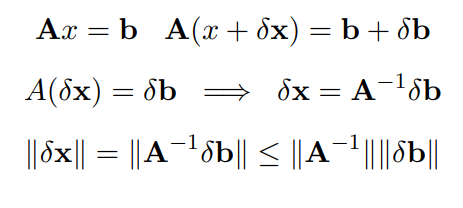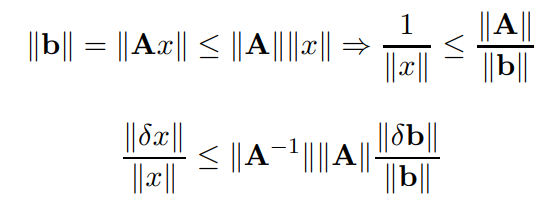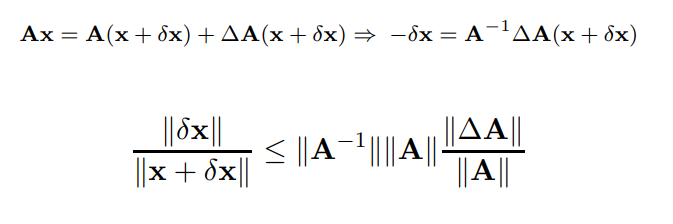Errore inerente
Bisogna cercare di generalizzare il concetto di errore e lo si fa con la norma
Norma vettoriale
È una funzione da indicata con due barrette, questa funzione mi dà un concetto di distanza.
Proprietà della norma
Si definisce una norma una funzione che soddisfa queste proprietà
- per ogni
- per ogni e
- Vale la disuguaglianza triangolare, ossia .
Convessità
Analizzato meglio in Analisi di Convessità. Si può dimostrare tramite la proprietà 3 e 4 che la norma è una funzione convessa. Infatti sia la funzione che soddisfa le proprietà della norma (quindi effettivamente si può chiamare norma). Allora:
Che finisce la dimostrazione.
Norma p
Nel caso in cui si chiama norma euclidea o viva
Nel caso è la distanza di manhattan
Norma di chebichev
quando ho è definita come e si indica con
Equivalenza fra le norme
Questo è un teorema che ci permette di asserire che più o meno tutte le norme hanno la stessa proprietà di definire il concetto di distanza fra due punti poiché
Siano due norme differenti, allora , ma questo vale solo se siamo in un campo finito.
Norma matriciale
Proprietà
Vogliamo riprendere tutte le proprietà descritte per la norma vettoriale, in più vogliamo andare ad aggiungere un quinto punto ossia
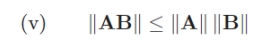
Norma naturale (o indotte)
Considero solamente le righe, come se compattassi tutte le colonne in una
La norma-1 indotta è molto simile, solo che ora compatto sulle colonne
Norma 2, o norma spettrale:
Con simmetrica e semidefinita positiva. con gli autovalori di Se ha rango massimo allora è definita positiva, che è il rango qui? Le norme dell’identità in tutte queste cose indotte è 1
Norma di frobenius
-
Slide relazione fra le norme matriciali
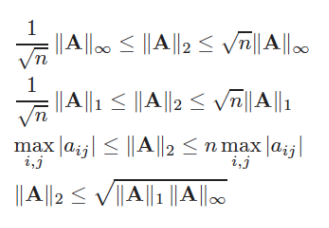
Condizionamento
Vogliamo andare a definire il concetto di condizionamento per il sistema lineare.
Ossia vorremmo valutare quanto un piccolo cambiamento della matrice influisca sul risultato finale.

Chiamiamo come errore inerente la distanza fra il risultato vero e il risultato perturbato. Questo errore dipende fortemente da una natura dei dati in input (che sono mal condizionati)
Mal condizionamento
si verifica quando a piccoli cambi della matrice di partenza, si ha un grande errore nel risultato (potremmo dire ordini di grandezza diversi, solitamente questo è una cosa che non vorremmo che ci fosse)
E la differenza fra i risultati è un errore inerente, che dipende dai dati, ma non dall'algoritmo
Perturbazione e n-condizionamento
Vogliamo ora vedere quanto siano grandi gli effetti di una perturbazione su una matrice. si può dimostrare che
Con il numero di condizione della matrice, solamente più è grande più l'errore viene amplificato., se questo valore è sempre maggiore o uguale a 1 è non singolare.
-
Slide ricavo relazioni condizionamento