Interrupt
Descrizione iniziale
Di interrupt e trap se n’è parlato un pò in Livello ISA di architettura, ora andiamo ad approfondire come viene gestito a livello SO.
Un interrupt è un segnale che viene mandato o da un dispositivo hardware (di solito dopo la fine di un processo input output) oppure da software, in questo caso viene chiamato trap che è un interrupt software sincrono..
-
Slide Interrupt Hardware e software

Questi segnali sono utilizzati per indicare eventi che dovrebbero essere gestiti (come end of I/O, divisione per 0, ma anche semplicemente syscall e passare livello kernel).
Il segnale solitamente implica la interruzione di quanto viene svolto in questo momento, per gestire l’interrupt corrente, e poi tornare all’istruzione precedente. Solitamente perché potrebbe anche essere che il processo non sia interrompibile, e quindi l’interrupt dovrebbe essere rischedulato.
Per poter ripristinare lo stato precedente solitamente ci si devono salvare l’immagine dei registri del programma, tutte le informazioni utili a far runnare il processo (di solito messe nelle PCB), e l’istruzione di ritorno.
Quando ci si ritorna sopra basta mettere nel PC l’indirizzo della istruzione corretta.
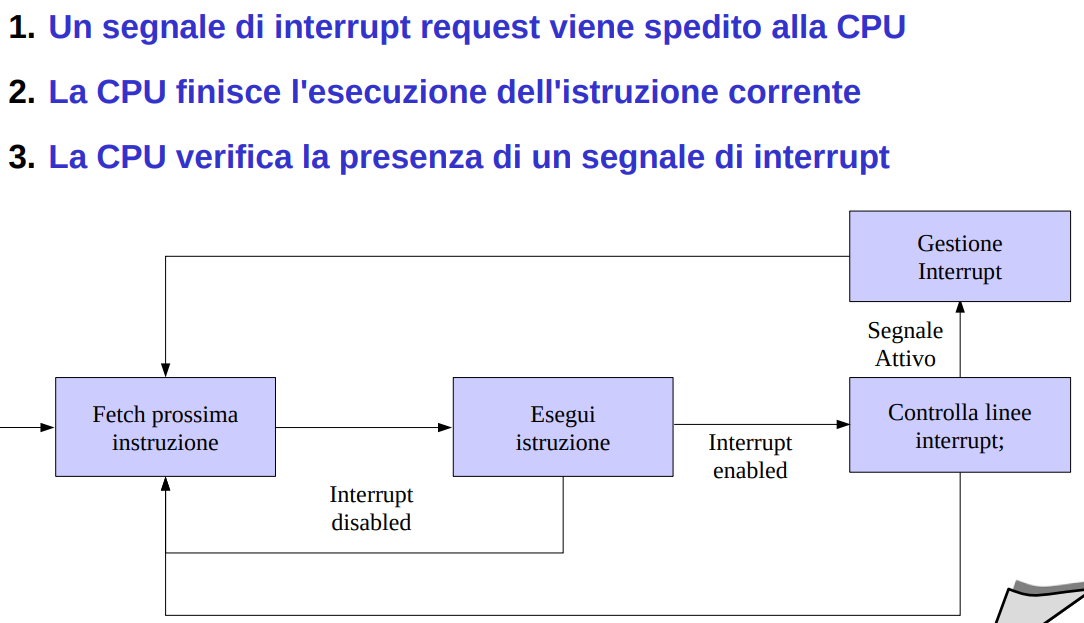
Procedimento classico di gestione interrupt
Praticamente durante il Ciclo va a fare un check per vedere se il filo dell’interrupt è settato, se sì carica istruzioni a un certo indirizzo (e si deve salvare l’istruzione attuale).
Masked se si sta facendo qualcosa che non si può interrompere, quindi è delayed. (quando il processore non può essere interrotto, ad esempio quando sei in Sezioni Critiche, o quando arrivano interrupt dello stesso tipo, se ogni interrupt ha una stack propria, andrebbe a sovrascrivere).
Se tutto va bene e non è delayed ed esiste un interrupt, ad alto livello fa:
- Sospende (in un modo che possa essere ripreso) il processo corrente
- Salta all’istruzione definito in interrupt vector **(**tabella fissa così è più veloce)
- Esegue l’interrupt
- Si ritorna al processo precedente, o altro (scheduling potrebbe far andare in altro processo).
-
Slides passi ad alto livello

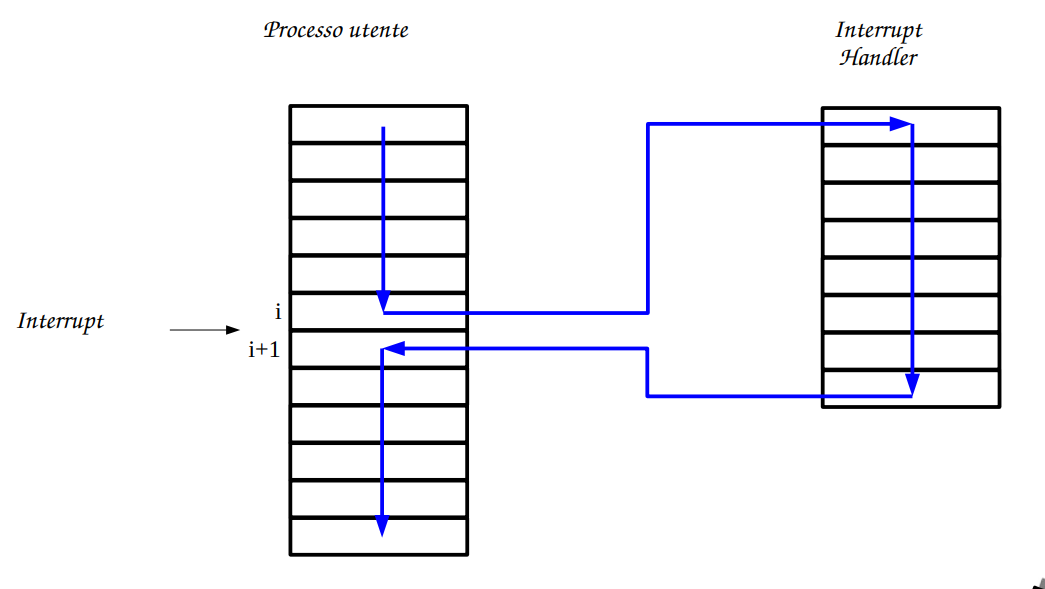
-
Slides passi a basso livello (!!!)

Fino a qui tutte le operazioni sono HARDWARE. Da ora in poi viene ripreso il ciclo FDE con il controllo dell Interrupt handler.

Tipologie di gestione di interrupt Multipli (2)
Quando ho interrupt multipli diventa leggermente più difficile gestire questi interrupt. Potrebbero interagire, che succede quando mi arriva un interrupt da device 1 mentre sto runnando l’interrupt handler di device 2???
Disabilitazione degli interrupt
Questa è la forma più semplice per la gestione dell’interrupt, in pratica quando sto gestendo un interrupt, li disabilito, in modo che non possa riceverne altri, così sono sicuro che non posso ricevere nessun altro interrupt. Una soluzione simile per le CS ne abbiamo discusso in Sezioni Critiche
Quando sto per finire riattivo gli interrupt e così posso vedere se ce ne erano alcuni pendenti.
Ho alcuni svantaggi come:
- Non ho un concetto di priorità degli interrupt a questo livello
-
Slide idea di gestione
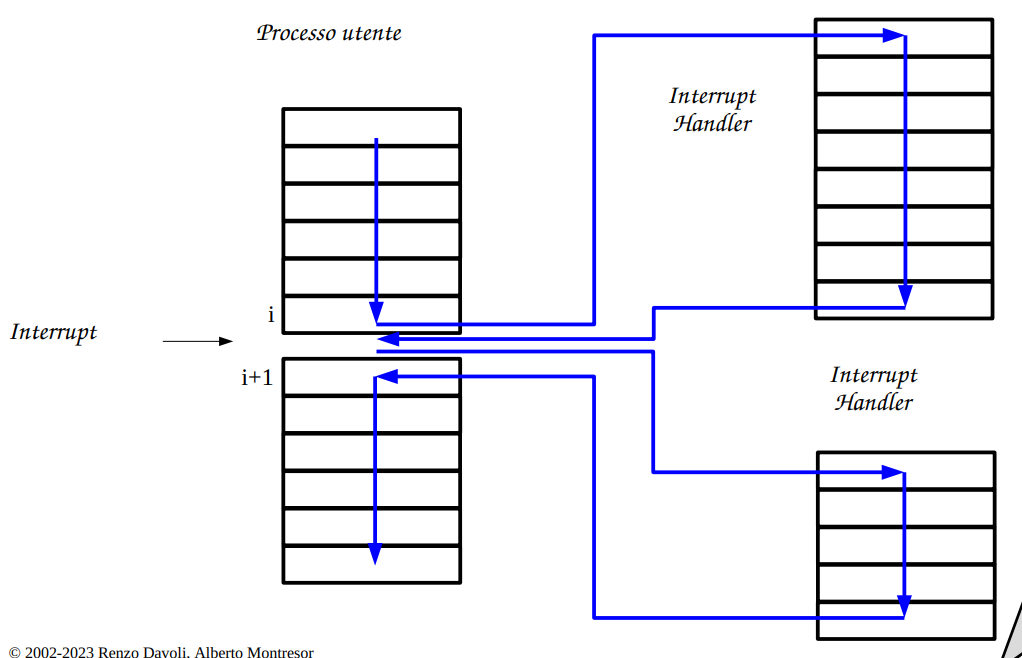
Annidamento degli interrupt
Questa è la soluzione più moderna, ed è anche la più efficiente che permette di
- Avere un concetto di priorità di interrupts
- Necessita di stack separati (se gli interrupt utilizzano la stessa stack, potrebbero sovrascriversi alcune informazioni!) quindi più difficile da implementare.
- Forse ogni interrupt ha una propria stack, se viene stetsso tipo di interrupt sono maskerati!
PI/O, or Interrupt based I/O
PI/O
In questo caso la CPU setta tutti i valori utili al controllore del device driver. e poi fa polling per chiedere al driver se ha finito o meno (attraverso un controllo sul registro di stato del driver).
Se il driver ha finito, la CPU si mette a copiare i dati di output del device alla propria memoria. Un chiaro svantaggio è che il polling è molto inefficiente per la soluzione di questo tipo di problemi.
Interrupt Driven I/O
Questa è la soluzione moderna, quella più utilizzata, dato che ora è il dispositivo driver a comunicare quando un processo I/O è stato completato o men, così la CPU è a conoscenza di questo evento e può comportarsi di conseguenza. (quindi quando gestire l’interrupt, e poi effettivamente runnare il codice corrispondente quando l’interrupt è avvenuto).
Memoria
Vedi Memoria.
Direct Memory Access
Per copiare alcuni dati utili per I/O dalla memoria RAM alla memoria del controllore bisognerebbe spendere tanti cicli di clock della CPU, di solito questa è una operazione molto lenta.
DMA ci permette di accedere direttamente alla memoria, quindi il controllore stesso è programmato con l’indirizzo su cui andare a prelevare la memoria corretta, sollevando la CPU da questo primo lavoro.
Chiaramente il vantaggio principale di questo metodo è la velocità, dato che abbiamo più cicli di clock per la CPU, oltre a questo, crea una interfaccia più facile da gestire, quindi i drivers sono più semplici.
Uno svantaggio è la contesa del BUS, che per trasferire c’è bisogno che il bus sia libero.
Sicurezza
Questo è un possibile falla di sicurezza, infatti se il codice del controller è malevolo potrebbe fare attacchi al sistema di certo tipo.
Secondo Renzo sarebbe meglio che questo codice fosse open, in modo che sia molto probabile di trovare cose maligne.
Ram
È semplificata da poche istruzioni di accesso, che di solito sono solo LOAD E STORE. (Tutti i dettagli fisici sono astratti, la CPU non si interessa di questi, sono built-in del calcolatore!).
Di solito (in modi che non so), sono gestiti da MMU.
NOTA: ci mettono un pò i condensatori a scaricarsi. (possibile recuperare un pò di informazioni se tipo congeli la RAM subito).
Le ROM esistono ancora, ma sono per cose basilari, come per la parte del boot.
Memory Mapped I/O
Alcune aree di memoria, come quelle del video grafico, sono scritti e letti subito da alcuni driver e sono utilizzati per sapere cosa mostrare sullo schermo per esempio.
Ma dato che 2 componenti (read and write) devono sincronizzarci nella lettura. Questa sincronizzazione di solito è fatta a livello hardware.
Dischi e SSD
Abbiamo spiegato meglio questa parte in Devices OS
Dischi memorizzano in maniera magnetica, e lo fanno in maniera non-volatile, cioè possiamo ritrovare i nostri dati.
Sono a accesso diretto, in contrasto con i nastri che erano sequenziali. leggermente accennato in Memoria. E per capire dove leggere e scrivere si devono impostante movimenti di settore del cilindro e testina per leggere il settore corretto. Settore si aspetta che giri, testina si aspetta che si sposti. È lento, nell’ordine dei microsecondi.
Operazioni possibili dei Dischi
READ, WRITE e anche Seek (quando vado a spostare la testina da altre parti!)

Sulla velocità
Non ci converrebbe avere uno stesso file messo in posti molto diversi fra di loro all’intenro del disco!
Cose di scheduling in modo da leggere cose che siano vicine. (Ma anche il filesystem, in modo che cose che cose che vengono utilizzate spesso siano vicine, ma questa roba la vedremo dopo)
Solid State Disk
Anche conosciuti come SSD, questi sono per cose non volatili.
Solitamente scrivono ad insieme di blocchi! e lo si fa in cicli di scrittura perché non scrive ad ogni singola scrittura, ma sono in un buffer, e saranno scritti insieme in tutti in un ciclo di scrittura, questo è per rendere più efficiente questa operazione.
Per ssd a volte tengo la RAM come una cache intermedia per la scrittura.
Gerarchie di memoria
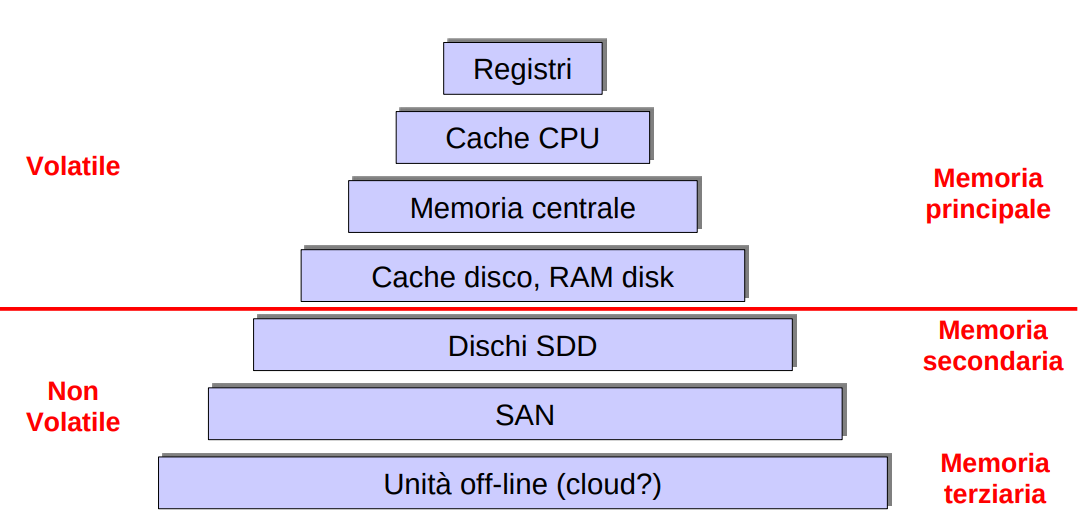

L’altro argomento si parlerebbe di Cache, ma penso sia trattato già benissimo in Memoria#4.2 Memoria Cache.
Quindi guardare lì, guardare la piramide della memoria il tradeoff velocità e quantità di memoria, il costo di accesso (in termini di tempo ed energia).
Sicurezza
Il processo
- Non dovrebbe accedere ad aree di memoria a cui non dovrebbe accedere
- Non dovrebbe accedere direttamente ai dispositivi I/O, altrimenti potrei accedere e modificare qualunque cosa sui driver, e qualunque processo potrebbe farlo.
È importante garantire la sicurezza anche per l’affidabilità del sistema, anche per proteggere il programmatore stesso, quando fa qualcosa in modo accidentale, in modo da evitare danni brutti. al sistema
Mode Bit
nella realtà le protezioni principali sono due, messe a livello hardware
- Un Mode bit che sta a specificare se il CPU è in Kernel mode o user mode.
- Questi metodi sono importanti perché il modo kernel permette accesso totale controllo totale sulla memoria, sull’IO, mentre user solamente gli indirizzi a lui illegali. Questo metodo permette di entrare in kernel mode in modo controllato, in modo che riesca sempre a gestire questa protezione.
- Ovviamente il cambio del mode bit è privilegiato, un programma normalmente non può cambiare mode con una singola istruzione, deve passare con system call che sono le interrupt software o trap, con una istruzione specifica per mandare interrupt. È l’unico modo!.
- Nota: ovviamente quando il computer parte, in boostrap è in modalità kernel, che appena finisce tornerà in User Mode (è il processo INIT!)
- Una mappatura a indirizzi illegali per il programma, in modo che possa accedere solamente a quello a cui dovrebbe accedere.
Protezione memoria

Questo pezzo di hardware ha il ruolo di tradurre indirizzi logici in fisici, e gestire l’accesso (ritorna l’errore se non si potrebbe fare).
È importante che sia in Hardware perché:
- Deve essere molto veloce, perché sono operazioni molto veloci
- Si potrebbe bypassare e allora avresti accesso a tutta la memoria ugualmente.
System call
La sistem call è una unica istruzione, mediante la quale è possibile accedere al kernel mode, in grado di accedere a tutto, utile per la protezione e affidabilità del sistema, e non permettere programmi di fare tutto.
Esistono convenzioni di chiamata, perché si aspetta in un certo registro la presenza di un codice che specifichi la tipologia di system call, poi la sistem call ritornerà il valore corretto in un certo registro.