XOR operation
È una operazione binaria abbastanza semplice però ci sarà importante per andare ad analizzare dei cifrari di un certo genere. Come il ONE TIME PAD che faremo fra poco in OTP and Stream Ciphers.
Teorema cifratura con XOR
Prendiamo $X$ una variabile aleatoria in $\left\{ 0,1 \right\}^{n}$ uniforme, sia $Y$ una variabile aleatoria su uno stesso dominio come vogliamo. Tali per cui $X, Y$ siano indipendenti Allora avremo che $C = X \oplus Y$ è una variabile aleatoria uniforme.
$$ \mathbb{P}(C=0) = \mathbb{P}((X,Y) = (0,0)) + \mathbb{P}((X, Y) =(1,1)) = \frac{p_{0}}{2} + \frac{p_{1}}{2} = \frac{1}{2} $$Quindi $\mathbb{P}(C=1) = \frac{1}{2}$ e si continua provando ad aggiungere parti.
One Time Pad Cipher
Inventato da Vernam 1917. e 1926 sempre lui, infatti questo è il cipher che è nella teoria veramente unbreakable! Lo ha chiamato BSS = Binary Symmetric source, vedi: https://cs.ioc.ee/yik/schools/win2006/massey/slides1.pdf
Descrizione del cipher
$$ E(k, m) = k \oplus m $$$$ D(k, C) = k \oplus C $$La cosa importante è che $k$ è usato solo una volta, altrimenti ho problemi di sicurezza molto importanti (vedi many-time-pad). Una altra cosa importante è che $k$ sia uniforme, che poi usando il teorema di XOR di sopra, possiamo avere massima sicurezza (entropia massima)
Necessità del mezzo comunicativo
Ci sono anche restrizioni sulla generazione e sulla conoscenza della chiave dai due parties che cercano di comunicare!

Dimostrazione segretezza perfetta
Si basa sulla definizione in Classical Cyphers#Security of the Key.
Vogliamo dimostrare $\mathbb{P}(E(k, m_{0}) = c) = \mathbb{P}(E(k, m_{1}) = c)$, assumendo di fare sampling di $k$ in modo uniforme.
$$ \forall m,c: \mathbb{P}(E(k, m) = c)] = \frac{\#\text{Chiavi tali per cui } E(k,m) = c}{\lvert K \rvert } $$Va vale il fatto che $\forall m, c$ $\#\left\{ k \in K: E(k, m) = c \right\} = 1$ Quindi abbiamo la segretezza. (è 1 perché con OTP è unica la chiave che viene utilizzata per ottenere quello).
Questo è importante perché dimostra che non esistono attacchi ciphertext only per OTP
Svantaggi OTP
La difficoltà di utilizzo di OTP, nonostante le forti garanzie teoriche è dalla lunghezza della chiave. Vedi Classical Cyphers#Security of the Key per maggiori dettagli.
- La chiave deve avere stessa lunghezza del messaggio (overhead, difficoltà per mandare messaggi lunghi)
- Distruzione della chiave dopo l’utilizzo (che si fa solo una volta!)
- La comunicazione della chiave.
Per questo motivo non si utilizza per applicazioni commerciali.
Attacks on OTP
Many time pad attack
$$ c_{1} \oplus c_{2} = k \oplus m_{1} \oplus k \oplus m_{2} = m_{1} \oplus m_{2} $$Questo è stato usato nel verona project (‘41 - ‘80)
American National Security Agency decrypted Soviet messages that were transmitted in the 1940s. That was possible because the Soviets reused the keys in the one-time pad scheme.
Nel caso vecchio di MS-pptp è stato possibile attaccarlo, perché la chiave viene riutilizzata per server-client e client to server. Stessa cosa per il WEP.
No integrità
Un attaccante può cambiare a suo piacimento il valore del plaintext iniziale, questo è soprattutto utile se sa bene cosa cambiare, altrimenti un umano probabilmente può capire che il messaggio è senza senso, ma nella teoria è giusto, il ricevente non può capire se il messaggio è stato modificato, o originariamente è stato mandato così:
Se attaccante modifica $c$ creando $c^{*} = c \oplus p$ il ricevente avrà $m \oplus p$ quindi è modificato, e non sa che è stato cambiato.
NOTA particolare Questo attacco è particolarmente pericolo quanso
- Si sa la posizione del testo da cambiare
- Si sa il contenuto del testo cifrato in quella posizione. Se si hanno queste informazioni posso metterci un valore a piacere in quella zona. Questa cosa dovresti riuscire a capire perché sia così. Ad alto livello ti dico: fai xor con quella parte di testo, così hai 0 in plaintext, poi rifai xor col tuo messaggio per metterci quello che ti pare.
Real-world attacks
L’unico takeaway è non usare chiavi ripetute, che vedi sopra.
Windows NT PPT (non fare)
Perché veniva ripetuta la chiave sia client che server
WEP (non fare)
- IV veniva ripetuta ongi 16M frames, che era presente
- Le chiavi generate per i vari frame sono molto correlate, perché cambia solo IV in seguente (dice la prof. che inviava anche in chiaro). Non so esattamente i dettagli ma non dovrebbe essere importante.
Stream Ciphers
Now we talk about stream ciphers, next about block ciphers, after that asymmetric cipher.., con questra struttura
Introduction
Motivation and basic stuff
LSM was first kind of crypto for cellphones, and it was a stream cipher (fast, at least 12 y ago confronted with the other ciphers that existed).
- Encrypting individual bits! when block ciphers encrypt blocks of it.
- This leads to simple encryption and decryption operations. (this is a big addendum! most of embeeded devices use this because its easy and fast!) The hardware is nice for these cyphers.
Standard template of encrypt decrypt (non fare)

And we can note it’s an shift cipher (affine cipher) discussed in the Classical Cyphers.
A note is that the decryption uses the Plus! This is because we are in modulus 2, and a sum is actually a xor operation. (see the logic table of it).
-
Proof of why the two operations are the same
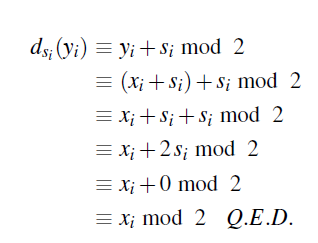
Sempre dalla tavola logica si può vedere che uno 0 può essere criptato 50% a 0 e 50% a1, quindi è resistente ad attacchi di analisi delle frequenze (ma questo solo se ho un generatore randomico buono !).
Random generators
As the security of the scream cipher is dependent on the keys, we need to have a way to generate random keys.
Categories of random number generators (3) (non fare)
Cercare su Sulla Stocasticità per descrizione sul tema.
-
True Random Number Generators tipically from random physical processes ma non riesco a farlo moltro in fretta
- Lancio di dati
- Rumore
- Movimento del mouse.
- Random keyboard types. (e distanza tempo fra di essi).
-
Pseudo-random Number Generators (vorremmo qualcosa di random, ma che possa produrre la stessa sequenza deterministic
- Most of these are not criptografically secure! (are usually predictable, so useless for cryptography).
- But they satisfy important statistical properties necessary for randomness (and tests)
-
Forma classica di computazione

-
Cryptographically Secure PRNGs (same as PRNGs, but with unpredictability).
-
Definition of unpredictability

- Cioè non riesco a predire in che modo la sequenza può continuare in tempo polinomiale, data una sequenza di bits di output.
-
Definizione PRNG
È una funzione $\left\{ 0, 1 \right\}^{s} \to \left\{ 0, 1 \right\}^{n}$ in cui $s \ll n$ computabile da funzioni deterministiche, con solo il seed che è l’input al randomness. In teoria gli algoritmi possono generare cose infinite, ma per quanto ci interessa, vogliamo restringerci solamente a un numero finito di bit in output (che è cosa nella pratica abbiamo) Una cosa è che l’algoritmo che li genera è deterministico, compattabile diciamo con Kolmogorov complexity, ma con buoni security guarantees e anche statistiche, vedi Sulla Stocasticità. È importante che quanto prodotto sembri essere random.
OPT tramite PRNG
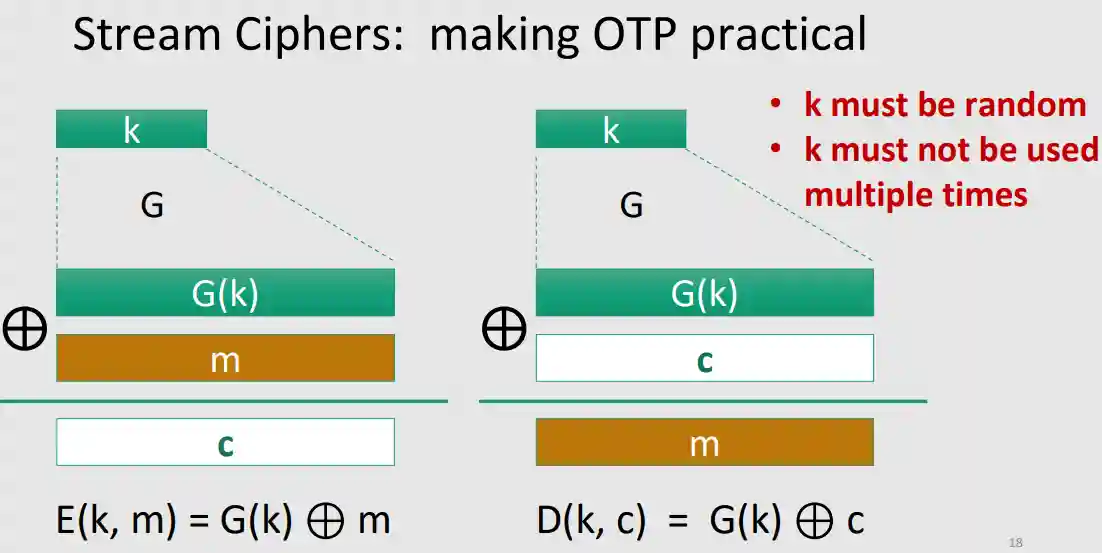
Possiamo usare #One Time Pad Cipher usando i PRNG! Così risolviamo il problema di comunicazione di cose troppo grosse.
Analisi sicurezza stream cipher con PRNG
Non abbiamo segretezza perfetta. Solamente che abbiamo la nota teorica in Classical Cyphers#Security of the Key che non possiamo avere sicurezza se la chiave reale è minore rispetto a quella reale.
Stiamo spostando la sicurezza dell’OTP sul seed che genera. Abbiamo bisogno di una nuova definizione di sicurezza.
Examples of PRNGs
Questi sono stati analizzati tempo fa da Knuth nell’art of computer programming.
Linear Congruential Generator
abbiamo una sequenza $r_{0} = seed$ e $r_{i+1} = a \cdot r_{i} + b \mod p$ Sembra che questa cosa molto semplice abbiamo proprietà statistiche Sulla Stocasticità molto carine, ma molto facile da scoprire.
glibc random (non impo)
$r_{i} = (r_{i - 3} + r_{i - 31}) \mod 2^{32}$ in cui gli index sono dei singoli bit credo Poi viene ritornato $r_{i} /2$ per qualche motivo
Nota: questo non è sicuro però come generatore!
Security necessities for PRNGs
Non predictability
Possiamo definire che un PRNG è predictable se esiste $i \in N$ tale per cui avendo la sequenza $x_{0}, x_{1}, \dots, x_{i}$ esista un algoritmo computabile secondo La macchina di Turing e che sia anche efficiente tale per cui possa calcolare $x_{i+1}, \dots$. con una probabilità alta. Se vale questo, e possono trovare l’algoritmo che computa questo algoritmo, avrei tutto poi per decifrare il messaggio (known plain-text attack), anche se non conosco la chiave iniziale.
$$ \mathbb{P}_{k \leftarrow K} \left[ A(G(k)|x_{1},x_{2}, \dots, x_{i}) = G(k)|x_{i+1}\right] \geq \frac{1}{2} + \varepsilon $$$$ \forall i \text{ no "eff" adv. can predict bit } (i + 1) \text{ for "non-negligible" }\varepsilon $$Definition of negligibility
Usiamo negligible e simili per avere un rule of thumb per capire ogni quanto non viene mantenuta la proprietà.
- $\varepsilon \geq \frac{1}{2^{30}}$ significa che ogni 1GB di data ho un caso in cui succede.
- Se ho $\varepsilon \leq \frac{1}{2^{80}}$ non avverrà tipo mai. La cosa è che questo non è molto rigoroso. Nella teoria possiamo definirli come funzione di un parametro di sicurezza. $$ \varepsilon : \mathbb{Z}^{\geq 0} \to \mathbb{R}^{\geq 0} $$ $$ \text{ non neg: } \exists d: \varepsilon(\lambda) \geq \frac{1}{\lambda^{d}} $$ $$ \text{ negligible } \forall d, \lambda \geq \lambda_{d} : \varepsilon(\lambda) \leq \frac{1}{\lambda^{d}} $$ la cosa che ci interessa di negligible, è simile al limite, è qualcosa che cresce con $\lambda$ che va sempre giù
Statistical Tests e Advantage
Qui viene definito solo come un algoritmo che ritorna 0 o 1 dopo che gli diamo la stringa iniziale in input. Per dire se è random oppure non. Note migliori dovrebbero essere in Sulla Stocasticità.
Con questo test e la possibilità di definire una sequenza truly random $r$ possiamo definire il concetto di advantage che in breve è quanto bene riusciamo a distinguere la PRNG dal random vero.

A me sembra abbastanza inutile questa definizione. Però può essere utile per definire che il PRNG non è abbastanza simile al random. L’intuizione principale è che lo spazio $\left\{ 0, 1 \right\}^{n}$ è molto più ampio rispetto alle stringhe effettivamente generabili da $k$ sampling da $K$. Però vogliamo che statisticamente siano indistinguibili. La misura di advantage ci dice quanto sono distinguibili.
L’algoritmo $A$ è spesso chiamato oracolo.
Security with advantage
Secondo la prof. questa “advantage” è una misura di quanto il sistema è rompibile. Se è simile a 1 sono abbastanza sicuro, altrimenti è 0.
$$ Adv_{PRNG}[A, G] \leq \varepsilon $$dove $\varepsilon$ è molto molto piccolo, negligible si potrebbe dire. Sembra che questo problema si riduca a $P \not= NP$ per qualche motivo strano. Queste sono definizioni con oracolo perché assumiamo di avere un $r$ che è truly random.
Questa definizione comunque secondo (Stinson 2005) chapt 6.9 è molto difficile da raggiungere, perché troppo facile da rompere, perché tratta di leaks di informazione, ma solitamente di molto poco conto.
Conseguenza su P e NP
Se si riesce a dimostrare che esiste un $PRG$ sicuro sotto questa definizione si può dimostrare che $P \neq NP$ vedi Time and Space Complexity.
Predictable => insecurity
Suppose you have a predictable $PRG$, that is $\mathbb{P}_{k \sim K}\left[ A(G(k)\mid_{1,\dots,i}) = G(k) \mid_{i = 1} \right] \geq \frac{1}{2} + \varepsilon$ We can have a statistical test with non negligible security. Let’s define
$$ B(x) = \begin{cases} \text{ if } A(X \mid_{1,\dots,i}) = X_{i+1} \text{ output } 1 & \\ \text{ else output } 0 \end{cases} $$If $r \sim_{R} \left\{ 0, 1 \right\}^{n}$ this statistical test gives $\frac{1}{2}$ because we have supposed it is not predictable. If we have the predictable sequence, by definition we can predict with $\frac{1}{2} + \varepsilon$ so the advantage is greater than $\varepsilon$ so it is insecure given this definition.
We have now proved that secure -> unpredictability. We can also prove unpredictability -> security (this is Yao'82). So these are equivalent.
secure PRG -> semantically secure stream cipher
$$ Adv_{SS}\left[ A, Q \right] \leq 2 \cdot Adv_{PRG}\left[ B,G \right] $$Given $G$ a secure $PRG$ and $Q$ the stream cipher derived from $G$.
Semantic security
Why is semantic security important? see here. It relates to the notion “no information about the plaintext from the ciphertext”. It can be viewed as a relaxed version for Classical Cyphers#Security of the Key. The idea has subtle connotations. This restricts the perfect secrecy idea onto computationally plausible scenarios, where you assume that a computational entity can’t distinguish it.
Definizione semantic security
Da https://en.wikipedia.org/wiki/Semantic_security
a semantically secure cryptosystem is one where only negligible information about the plaintext can be feasibly extracted from the ciphertext.
Da un punto di vista teorico, questo è un rilassamento della nozione di Classical Cyphers#Security of the Key, in cui si richiede che siano uguali, in questo setting richiediamo che siano solo vicine le due probabilità. Solo che sembra che sia inutile la nozione per sé quindi introduciamo l’esperimento.
Nelle slides si fa un gioco di questo genere:
- Challenger e adversary
- L’avversario invia due messaggi in chiaro,
- Challenger invia i messaggi cifrati L’obiettivo dell’avversario è identificare quale ciphertext coincide a quale messaggio, se si può fare, non è sicuro secondo la definizione di semantic security di sopra, anche se non so nella pratica quanto sia vero. Questo è vero quando #Security with advantage è negligible, quindi non si può fare.
Per il prof. è leggermente diverso rispetto a questo:
Probabilità di associare il ciphertext al corrispettivo plaintext.
Questo si può riassumere in questo:

Ossia non è in grado di distinguere la funzione fatta con chiave da una funzione a caso nell’insieme delle funzioni. E quindi per l’avversario entrambi i plain-text sembrano essere uguali e non ha advantage.
Semantic security for many-time key
Abbiamo ora che la chiave è usata più di una volta, quindi abbiamo molte coppie, magari anche qualche plain-text, vogliamo chiederci in teoria se è possibile usare la stessa chiave e avere ancora lo stesso livello di sicurezza. Questo pattern è molto comune, IPsec, criptare dischi… Infatti può scegliere quale plain-text avere a suo piacimento, si chiama chosen plain-text.
Ossia può scegliere quanti messaggi vuole per un certo esperimento

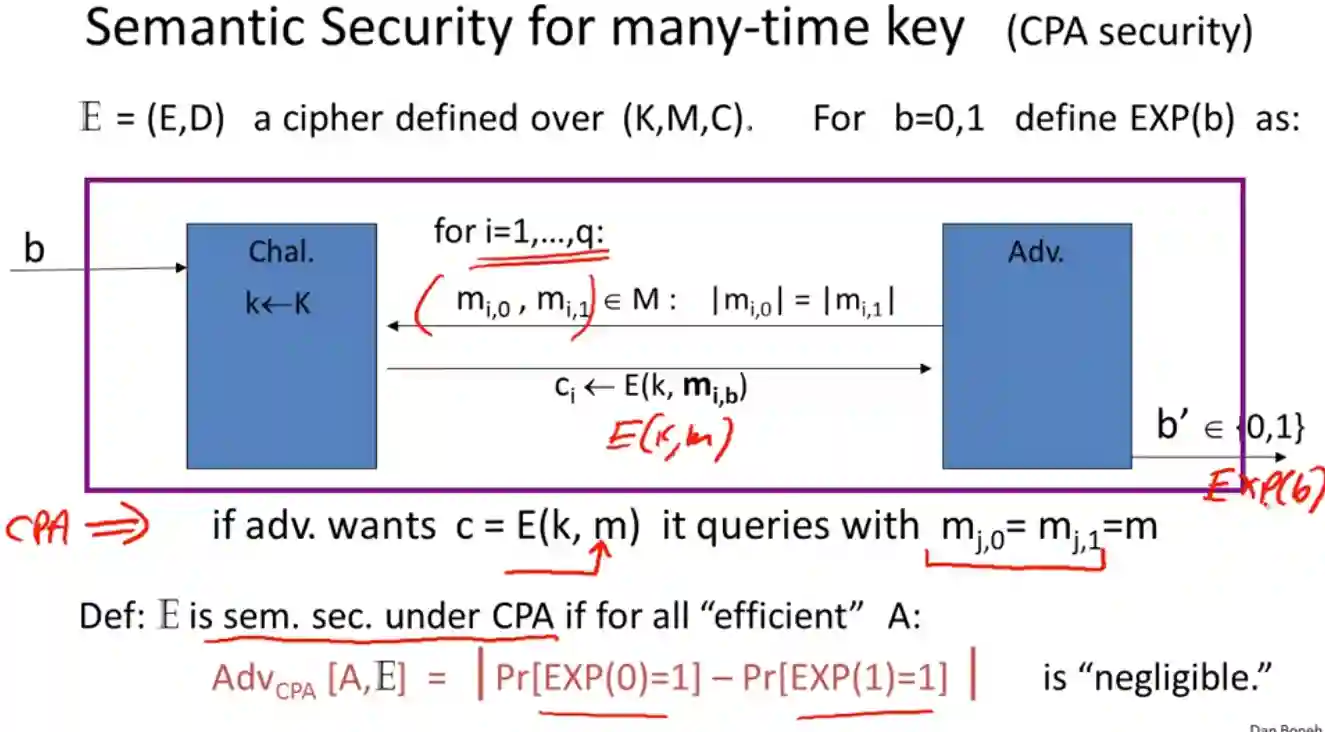 The challenger chooses a $b$ to compute, then adversary can send messages and receive ciphertexts how many times as he likes.
The challenger chooses a $b$ to compute, then adversary can send messages and receive ciphertexts how many times as he likes.
Security of same ciphertext under CPA
If the cipher outputs the same message when encrypting the same plain-text, it can be proven that it has not CPA security. This urges the creation of ciphertexts that need to create different ciphertexts with the same plaintext!
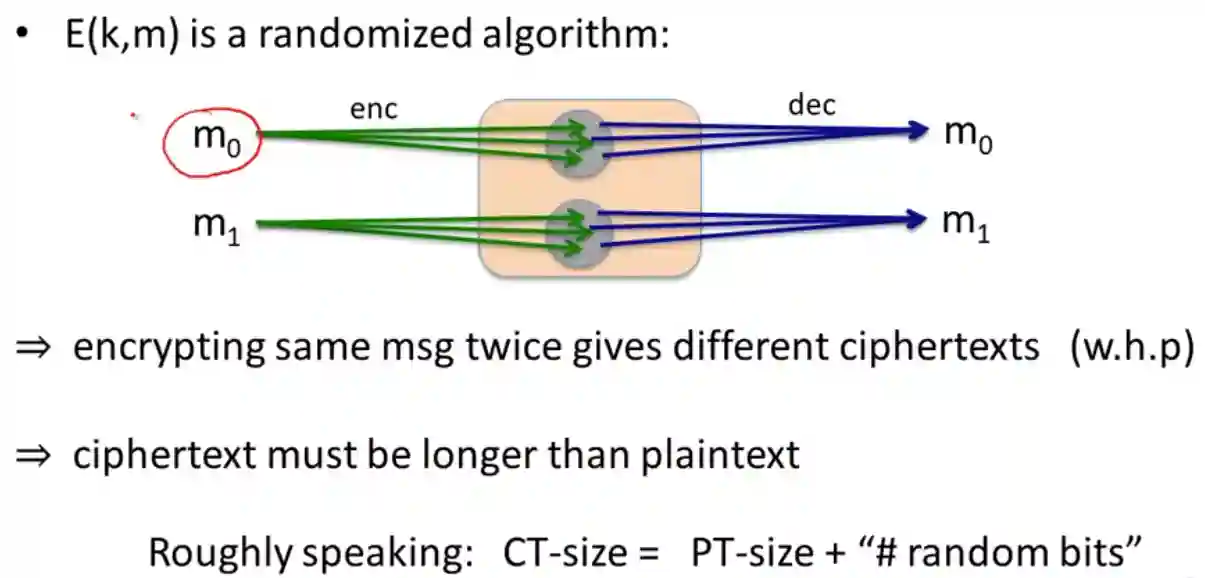 ##### Nonce based-security
L'idea è la stessa di cui abbiamo parlato in Sicurezza delle reti per un protocollo di autenticazione.
Un esempio carino di questo è in Block Ciphers#Cipher Block Chaining (CBC)) per cercare di randomizzare l'IV.
##### Nonce based-security
L'idea è la stessa di cui abbiamo parlato in Sicurezza delle reti per un protocollo di autenticazione.
Un esempio carino di questo è in Block Ciphers#Cipher Block Chaining (CBC)) per cercare di randomizzare l'IV.
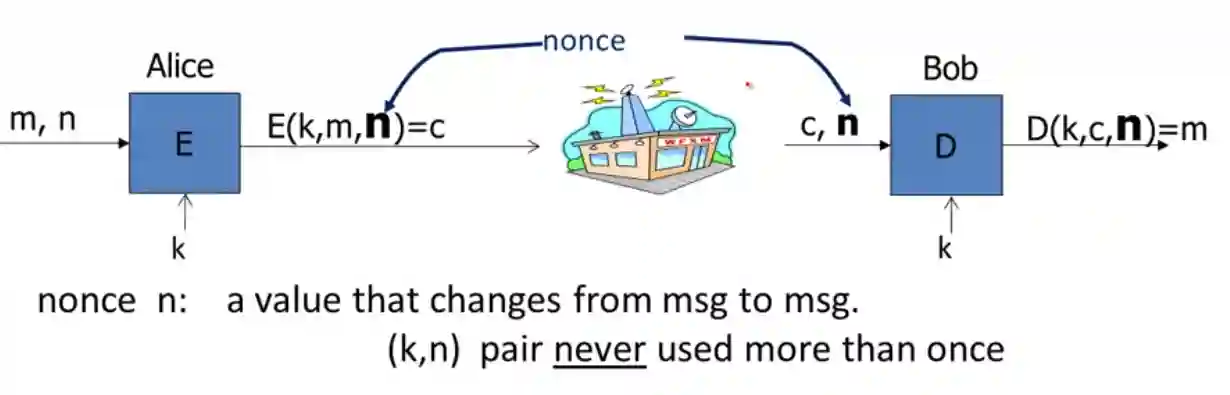
Semantic security for Chosen Ciphertext
This definition is used for public encryption schemes. Two phases.
- Adversary can ask for decriptions of any ciphertext.
- Then classically sends two messages, and receives a ciphertext
- Then can again send ciphertext again, except for the ciphertext he received
- Then outputs $0$ or $1$.
-
Practical stream ciphers
In questo caso andiamo ad utilizzare un PRNGs, non più truly random, per le ragioni di efficienza di comunicazione…
la chiave sono i valori delle cose affini nel LCG.. (forse anche il seed? boh)
RC4 cipher
Non so bene come è stato creato questo algoritmo, probabilmente provato cose a caso??? Questo è stato inventato da Ron Rivest, lo stesso che ha inventato l’algoritmo di RSA del 1987.
Inizializzazione
Usiamo il seed $s$ per inizializzare una permutazione dei primi 256 numeri
S[i] <- arange(0, 257)
s = len S
j <- 0
for i <- 0 to 255 do:
k <- S[i mod s]
j <- (j + S[i] + k) mod 256
swap(s[i], s[j])
Con questo algoritmo in pseudocodice
Generazione (non fatta)
 #### Attacchi
Non segue la definizione di Classical Cyphers#Security of the Key, c'è del bias in quanto generato che si può sfruttare in modo abbastanza semplice, per esempio si può attaccare WEP che usava questo algoritmo in questo modo.
### Content Scrambling System (non fatto)
Ma Dan Boneh parla di #Linear Feedback Shift Registers in questa sezione.
#### Attacchi
Non segue la definizione di Classical Cyphers#Security of the Key, c'è del bias in quanto generato che si può sfruttare in modo abbastanza semplice, per esempio si può attaccare WEP che usava questo algoritmo in questo modo.
### Content Scrambling System (non fatto)
Ma Dan Boneh parla di #Linear Feedback Shift Registers in questa sezione.
eStream Cypher
Si ha solitamente un nonce in questo caso, lo stesso che abbiamo usato in Sicurezza delle reti. Quindi un valore randomico utilizzato una singola volta
Salsa 20
È un algoritmo moderno di stream cipher, solitamente implementato in hardware per velocità. Prende una chiave 256 bit e un nonce di 64. Utilizza questo per fare un mix di 20 rounds e poi produrre ili bit stream utilizzato per encodare il plaintext iniziale. Questo è ancora sicuro, attacchi esistenti non riescono a romperlo totalmente pagina wiki Veloce che fa Mezzo giga al secondo di cifrazione.
Linear Feedback Shift Registers
This is a way to create a stream of bits to xor with the message. This stream is generated with a key. One of the advantages is that it’s low power in hardware.
Shift registers
You have to remember flip flops by Circuiti Sequenziali in architecture.
- Coso per storare un singolo bit sincronizzato dal clock del computer.
La cosa interessante quando si collegano input e output fra flipflops diversi, è che ad ogni ciclo di clock, si ha una specie di onda che shifta tutti i bit! Quando l’output è rixorato in certi modi e rimesso all’inizio, ecco che riusciamo ad avere il feedback lineare!
-
Esempio di mini Linear feedback Shift register
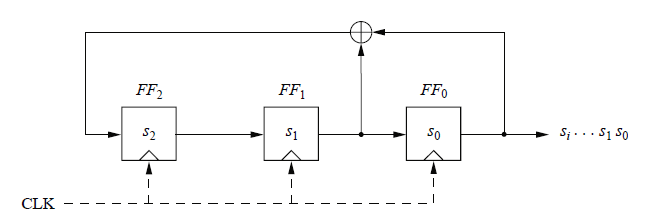
-
Esempio di LFSR generalizzato
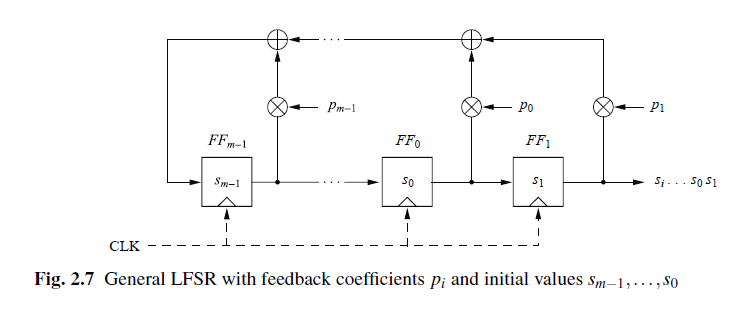
Matematical Description
Con p, per dire se è 0 o 1 (o aperto o chiuso). E poi in pratica è l’operazione di +, o xor.

We want to have a LSFR which has a very long period
Possiamo anche descrivere un LSFR con dei polinomi. In particolare è importante sapere
- il numero dei registri
- Le porte che sono aperte e quelle che sono chiuse.
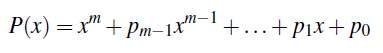
Però non so ancora perché questa rappresentazione del LSFR è utile, boh, lasciamo star.
Theorem on the period of LSFR

L’idea della dimostrazione è tipo che gli stati interni della LSFR è al massimo $2^m - 1$, quindi al massimo il periodo è quello. (non posso avere 0 perché sennò avrei periodo di 1, che non serve a niente).
Ma non tutti hanno periodo massimo! Forse centrano qualcosa i polinomi ciclotomici, però sta fuori dalla mia capacità matematica lol.
-
Esempi di LSFR massimi e non

Known Plaintext Attacks
Il nemico conosce
- Tutto il ciphertext
- il grado dell’LSFR (se non lo sa fa bruteforce, e quindi è come se lo sapesse)
- Conosce i primi 2m bits del plaintext, quindi sa i primi 2m bits generati.
Dal plaintext conosciuto, vorremme ricavare tutti i bits successivi di questo stream cipher. (basta ricavare i valori dei p, ora vediamo un metodo per ricavarli).
Dato che possiede 2m bits conosciuti e conosce m, deve risolvere un sistema di m incognite e m equazioni, e questo si fa, quindi così riesce a ricavare LSFR da queste!
References
[1] Stinson “Cryptography: Theory and Practice, Third Edition” CRC Press 2005