Memoria sistema Operativo
Guardare Memoria virtuale Per vedere come vengono rimpiazzate le pagine
In quest sezione andiamo a parlare di come fanno molti processi a venire eseguiti insieme, anche se lo spazio di memoria fisico è lo stesso. Andiamo quindi a parlare di spazio di indirizzi, risoluzione di questi indirizzi logici, segmentazione e paginazione. (e molto di più!)
MMU
Controlla se l’accesso di memoria è bono o meno. (traduzione fra indirizzo logico e fisico)
Cosa succederebbe se non fosse hardware?
- La performance sarebbe molto peggiore.
- Sicurezza, si dovrebbe implementare uno mode switch e andare al kernel mode per accedere (syscall per accedere ad indirizzi di memoria), quindi non si utilizza mai, perché sarebbe ancora più lento.
Memory manager
Its job is to keep track of which parts of memory are in use and which parts are not in use, to allocate memory to processes when they need it and deallocate it when they are done, and to manage swapping between main memory and disk when main memory is too small to hold all the processes. (pg. 373 Tanenbaum)
COSA FA il MMEMORY MANAGER?
- Tiene traccia della memoria libera
- Configura la MMU
Binding
In questo caso parliamo di associazione fra indirizzi logici e indirizzi fisici, in pratica ad altro livello, ma la stessa cosa. Nomi e Scope parliamo di binding fra variabili e nome della variabile.
Lì abbiamo deciso 4 modi in cui si può fare il binding! Sono molto simili rispetto a quelle, però ora stiamo parlando a un livello più basso.
Binding a Compilazione
Due istanze del programma non possono mai essere eseguiti CONTEMPORANEAMENTE, come per microcontrollori si può fare una cosa simile.
Chiamato codice assoluto. perché è mappato direttamente in una certa zona in fase di compilazione, non cambierà MAI.
-
Stessi indirizzi per ogni esecuzione del programma.
-
Slide binding compilazione
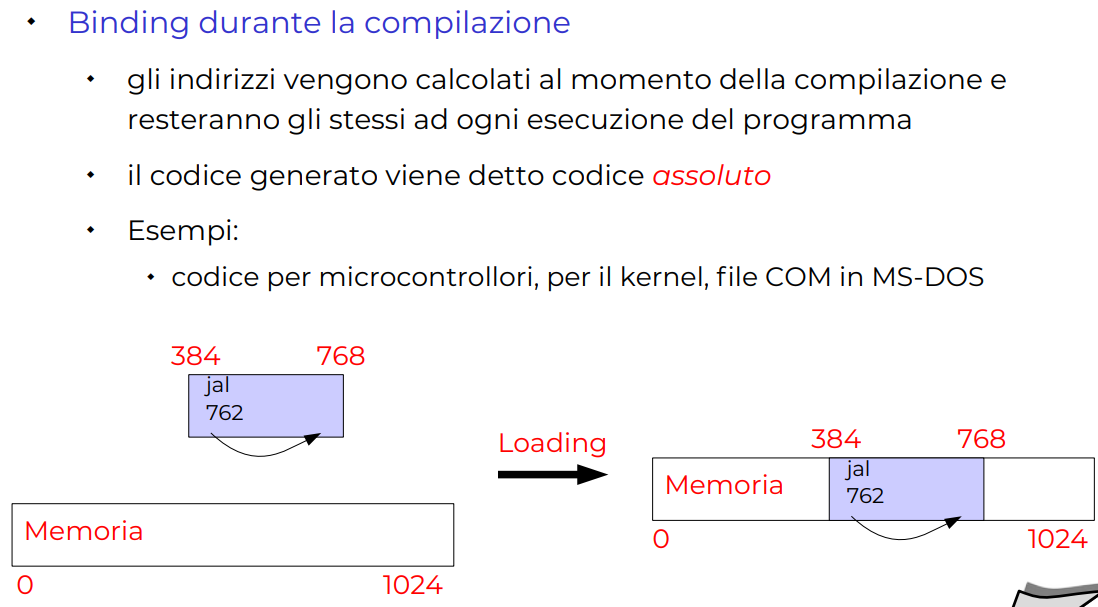
-
Slide vantaggi e svantaggi

Binding a Caricamento
Tutti gli indirizzi sono offsettati da un indirizzo 0. In questo senso quando carico una istanza del programma, basta offsettare tutti gli indirizzi a un certo punto.
-
Slide binding a caricamento
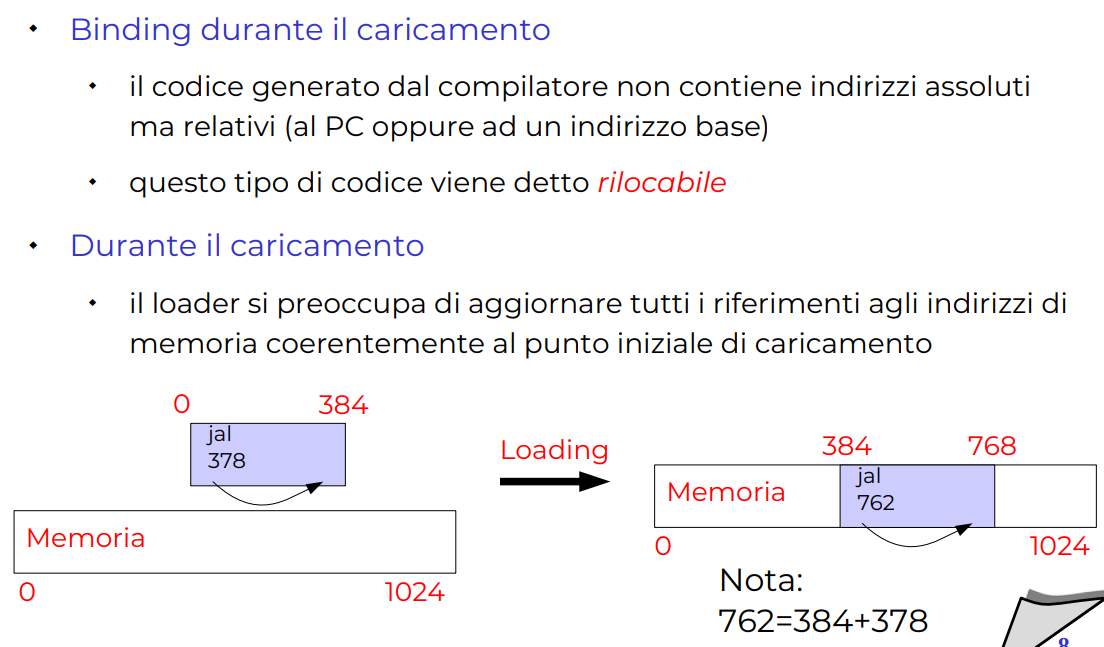
-
Slide vantaggi e svantaggi

Si pone più onere al loader che deve sapere dove caricarti la roba. Però anche qui niente hardware!
Binding a Esecuzione
Anche qui c’è l’offset, ma è più fine. L’eseguibile pensa di avere gli indirizzi offsettati da 0, poi a runtime la MMU traduce questo indirizzo logico all’indirizzo reale, che è offsettato a qualcosa.
-
Slide binding a esecuzione
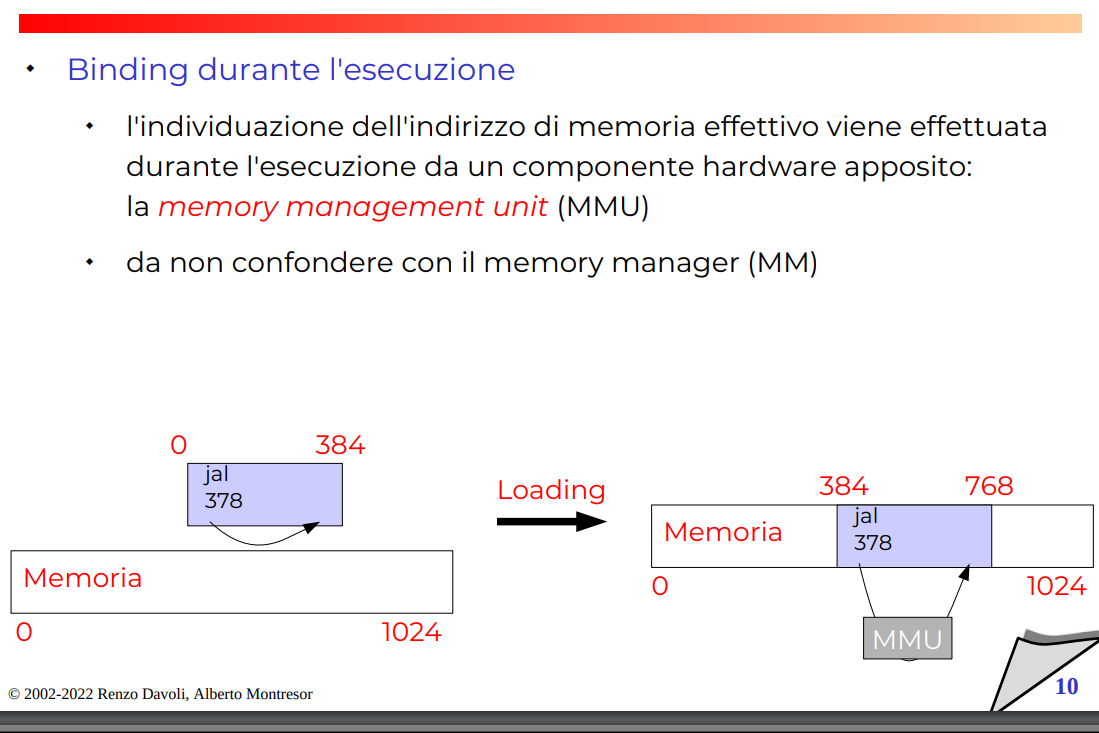
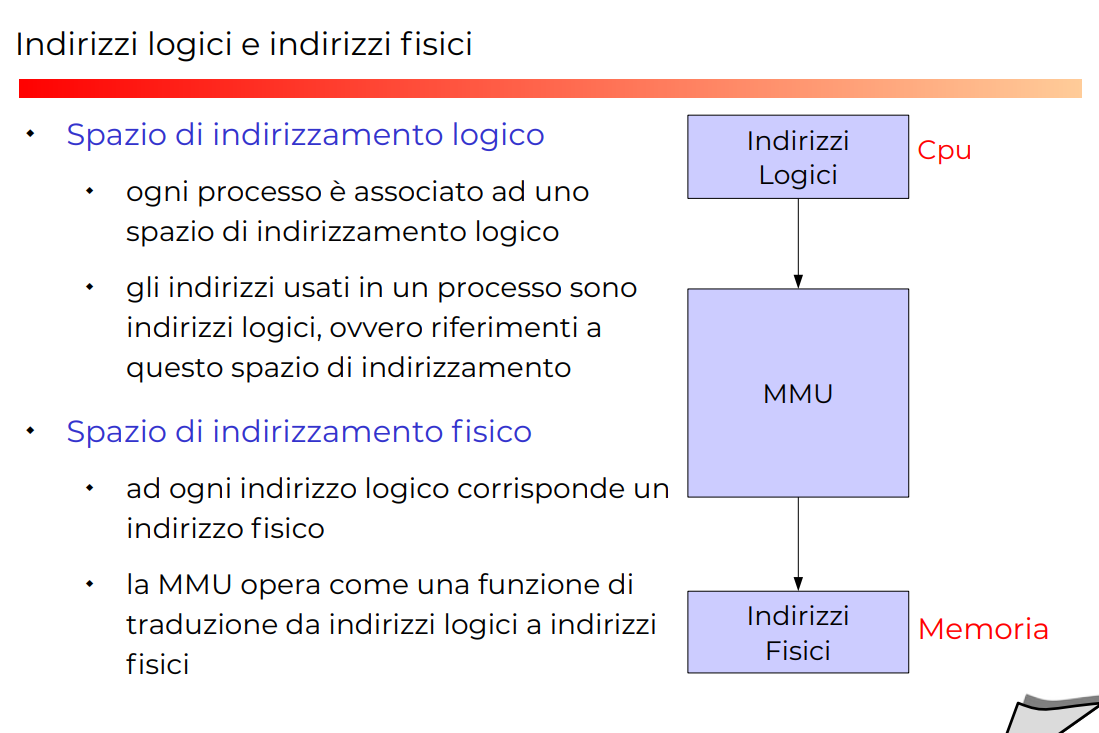
Registri MMU
Registro di locazione
In pratica abbiamo una tabella, molto simile a una tabella Network Address Translation di rete, ma con scopi molto diversi.
Allo stesso modo in cui un pacchetto entra, viene fatto match nella tabella ed esce in modo diverso, abbiamo una registro di rilocazione che fa lo stesso JOB.
-
Slide Registro di rilocazione
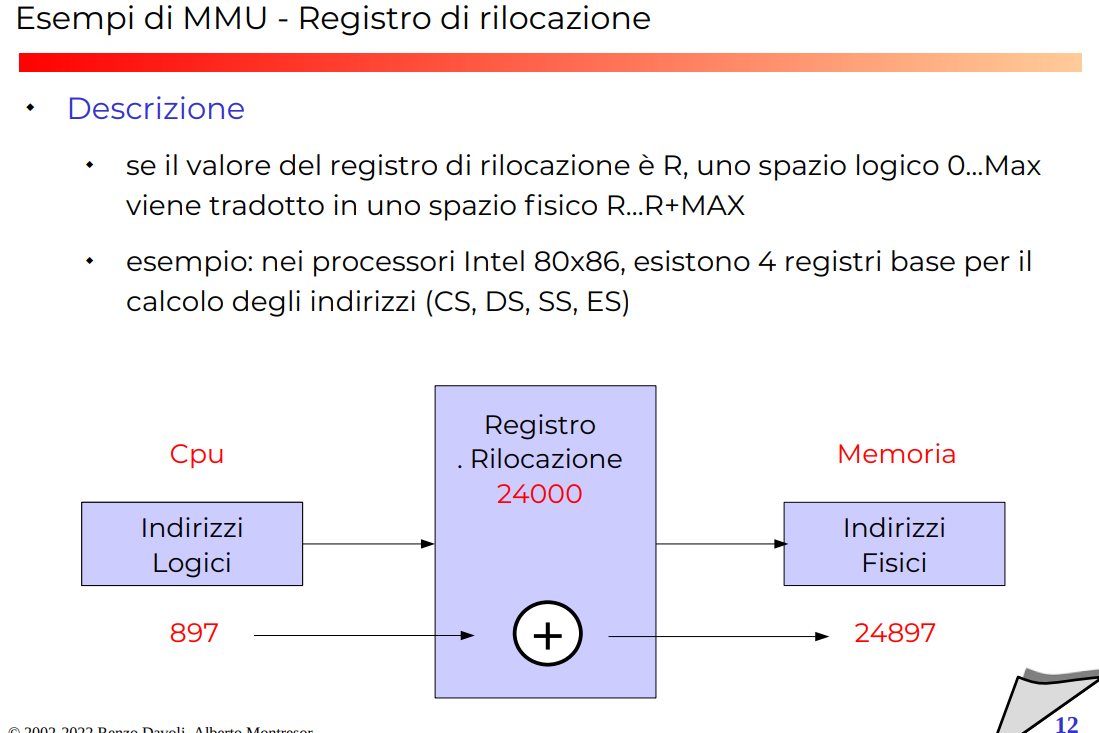
Solitamente
- Codice
- Dati
- Stack
- Extra (utilizzi speciali, tipo copia da stack a dato o simili, praticamente usi come ti pare).
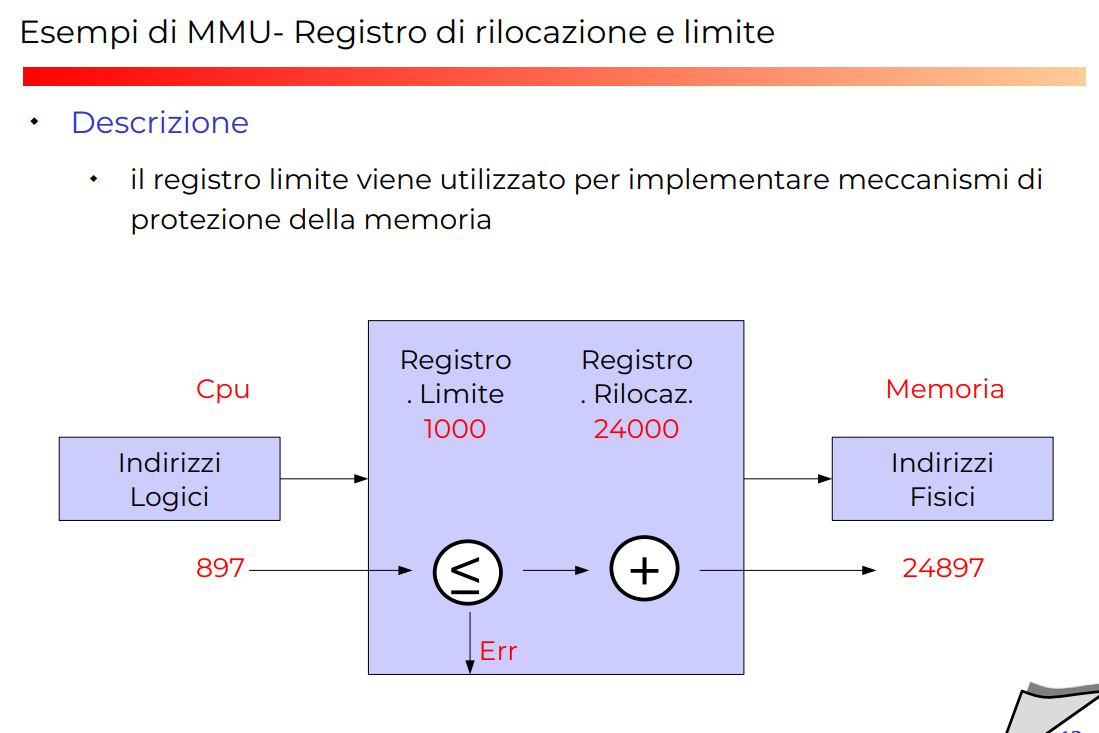
Registro di limite
Questo nuovo registro permette di fare controlli sulla sicurezza. Praticamente fa check su indirizzi, se l’indirizzo soddisfa regola e.g. maggiore di 1000 allora manda avanti, altrimenti in errore
-
Slide registro di limite
Loading dinamico
Routine vengono caricate solo quando le chiamo, le abbiamo già fatte in archietttura quando abbiamo parlato di traslazione di indirizzi dinamici 9.4.4 Indirizzamento dinamico. Generava una trap, e poi veniva trovato l’indirizzo corretto.
LINKING STATICO E DINAMICO
Nota Loading ≠ Linking!, però posso fare loading dinamico con linking dinamico. 😀 Statico invece è quando l’eseguibile ha tutte le funzioni che gli servono (copiate e incollate dentro l’eseguibile, senza dipendenze esterne, molto più pesante, ma è isolato, diciamo).
-
Slide vantaggi svantaggi

-
MINIDEMO LOADING
Prova a compilare un file e poi compilare con
#include <stdio.h> int main() { puts("eee"); }gcc -o out prova.c, normalmente linka dinamicamente, che puoi vedere connm,se runni con la flag
-statice fai la stessa cosa, allora vedi che il sinbolo è definito.
Allocazione pagine
Definizioni
ALLOCARE: Significa assegnare spazio di memoria fisica al programma.
STATICA DINAMICA,: se resta per l’intera vita del programma o meno.
CONTIGUA O NON CONTIGUA: se la memoria mappata è tutta a un filo senza buchi o meno.


Partizioni fisse
Questa è una tecnica molto simile alla gestione della heap in blocchi fissi Gestione della memoria. In pratica ho delle partizioni fisse.
-
Slide partizioni fisse

Solitamente sono utili per sistemi Embedded, in cui non vuoi perdere tempo a fare conversioni, e vuoi questa cosa statica.
Poi c’è di nuovo il pippone della frammentazione interna ed esterta presente in Gestione della memoria, e in Livello OS. Si parla anche di soluzioni a questo, come la compattazione, ne abbiamo già parlato, quindi qui sto zitto.
Sulla compattazione
Quando voglio fare compattazione, devo interrompere certi programmi, copiare tutto il programma ad indirizzo diverso, cambio indirizzo di allocazione e poi lo posso far ripartire (quindi da stato running a ready dopo queste operazioni), però lentissimo!.
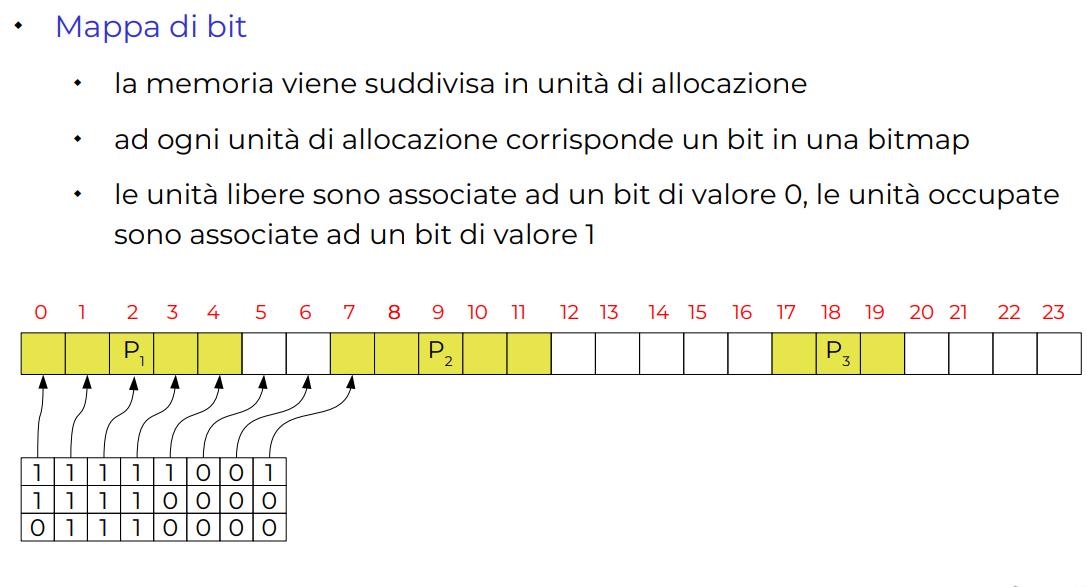
Bitmap
In pratica tutta la memoria viene divisa in qualche chunks di memoria, per esempio se ho in totale 1024 byte di memoria, potrei dividerla in blocchi da 32 byte, allora mi tengo una bitmap di 1024 /32 = 32, così so che mi dovrò tenere una bitmap di 32 bits, un bit mi indica 1 se ho usato quel blocco, 0 altrimenti.
Per allocare in questa struttura di dati basta andare a cercare una serie di blocchi contigui liberi.
-
Slide bitmap
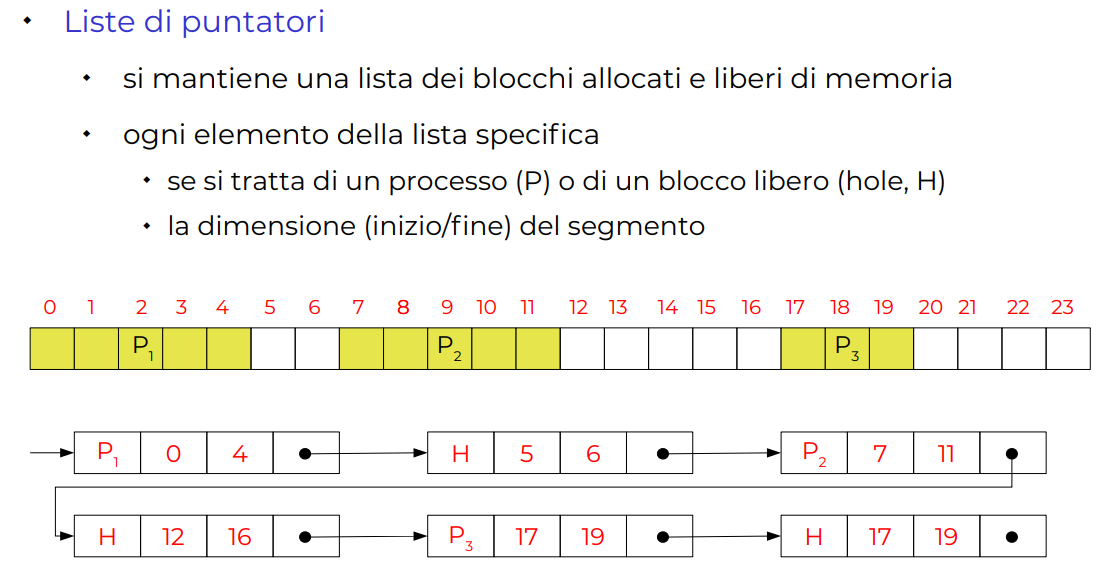
Linked list
Tutti i blocchi sono tenuti in una lista linkata, che ha un booleano per indicare se è occupato o meno, e poi la lunghezza. L’allocazione è uno scorrimento di questa lista linkata.
-
Slide linked list
Quando vengono deallocati, si può utilizzare la compattazione parziale di cui abbiamo parlato in Gestione della memoria.
-
Slide compattazione parziale
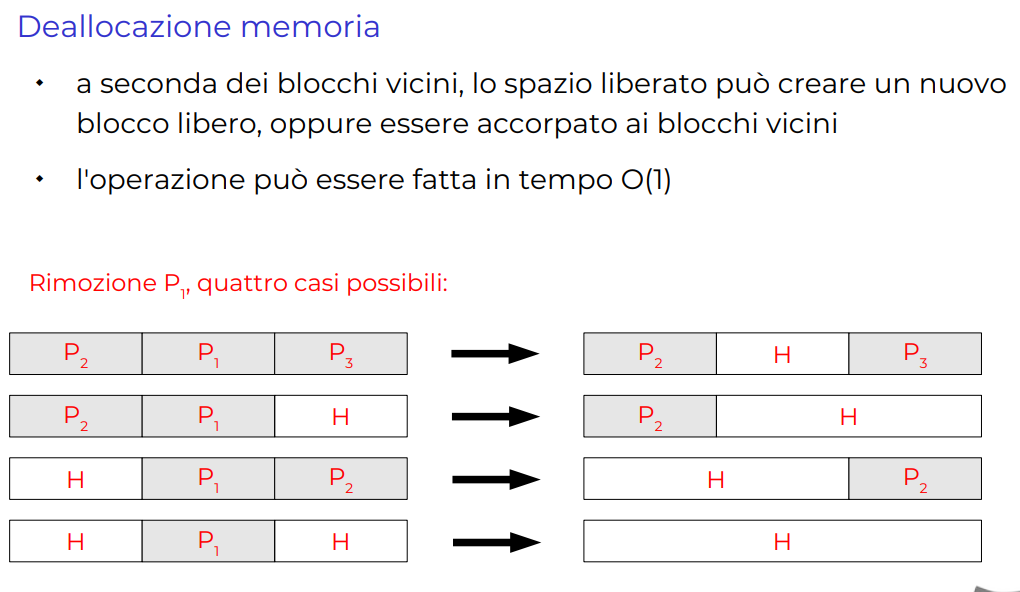
Ci sono altri generi di algoritmi, come next fit, oppure worst fit, però alla fine hanno performance molto peggiori rispetto a first o best fit. In generale questi problemi fanno ancora frammentazione, quindi non è che siano buone buone buone come cose.
Paginazione
Le tecniche di paginazione nascono per essere una alternativa molto più efficiente rispetto ai metodi di fitting precedenti, per questo motivo ora andiamo a descriverlo:
Andare a guardare Algoritmi di paging per capire in che modo vengono gestite le pagine.
Descrizione idee generale
La memoria del programma è divisa in pagine, e poi questo è messo nella memoria fisica dette frame, e sarà gestita dalla MMU. La frammentazione interna esiste ma è molto minimo, la frammentazione esterna non esiste proprio ora.

Implementazione della paginazione
Questa è esattamente la parte che abbiamo spiegato in Livello OS, in pratica, l’indirizzo logico viene diviso in indirizzo di paginazione e indirizzo di memoria dentro la pagina stessa Per esempio se ho 4096 bit per una singola pagina (standard attuale), ho che nell’intero indirizzo della pagina è data dai primi 20 bit, l’inddirizzo all’interno della pagina dai next 12.
-
Esempio di utilizzo della paginazione
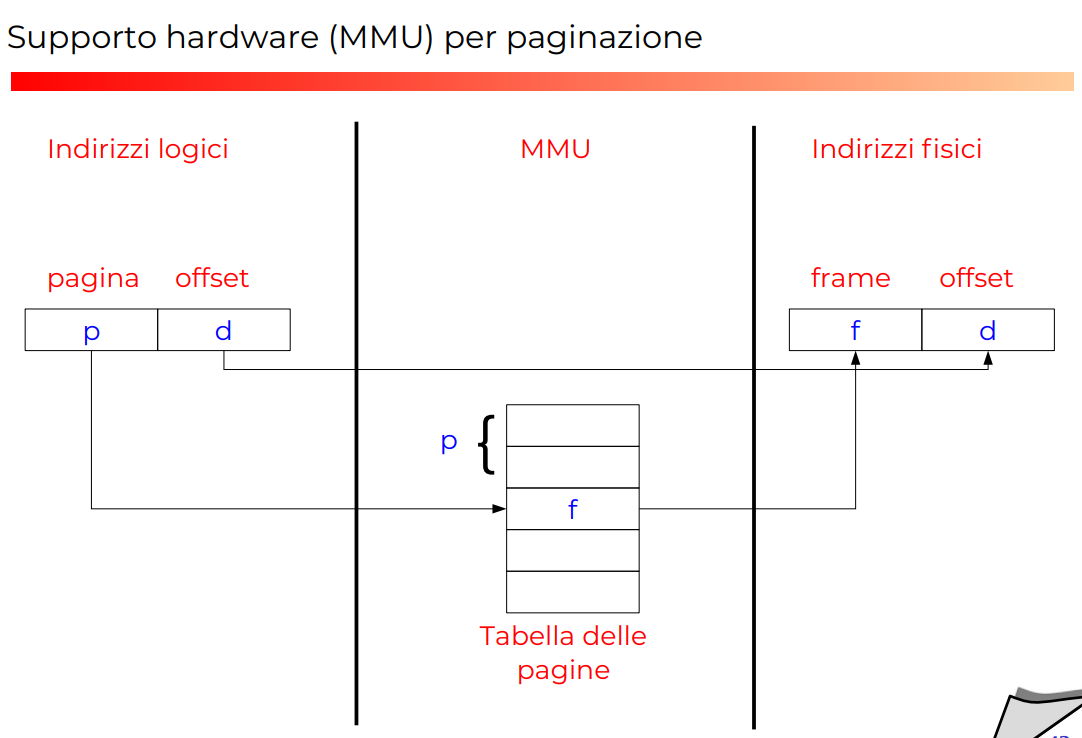
Desidn della paginazione
- Blocchi potenza di due così è facile dividere gli indirizzi senza altre conversioni
- Non troppo grosso, così fa meno frammentazione
- Non troppo piccolo, così non ho troppe pagine.
Storare la tabella delle pagine (2)
Dobbiamo trovare un modo per storare la tabella delle pagine, per esempio con un giga di memoria sarebbero circa un milione di pagine, storare in una tabella stile registri (come NAT di reti) è troppo costoso come metodo. Mettere in memoria, dovresti fare due accessi una nella page table, e una in memoria (e quindi molto lento!).
Quindi vogliamo fare qualcosa di mezzo:
- La page table sta in memoria
- In MMU sta una cache della page table per risoluzione di indirizzi recenti, guarda Memoria, questa si chiama Translation Lookaside Buffer (TLB), utilizzata la tecnica dei registri associativi, quelli che abbiamo utilizzato nell’implementazione dei Router in Data Plane, praticamente ti fanno il confronto in modo immediato, ma sono costosissimi da avere.
Translation Lookaside Buffer
-
Slide TLB

-
Esempio tabella di pagine nuovo
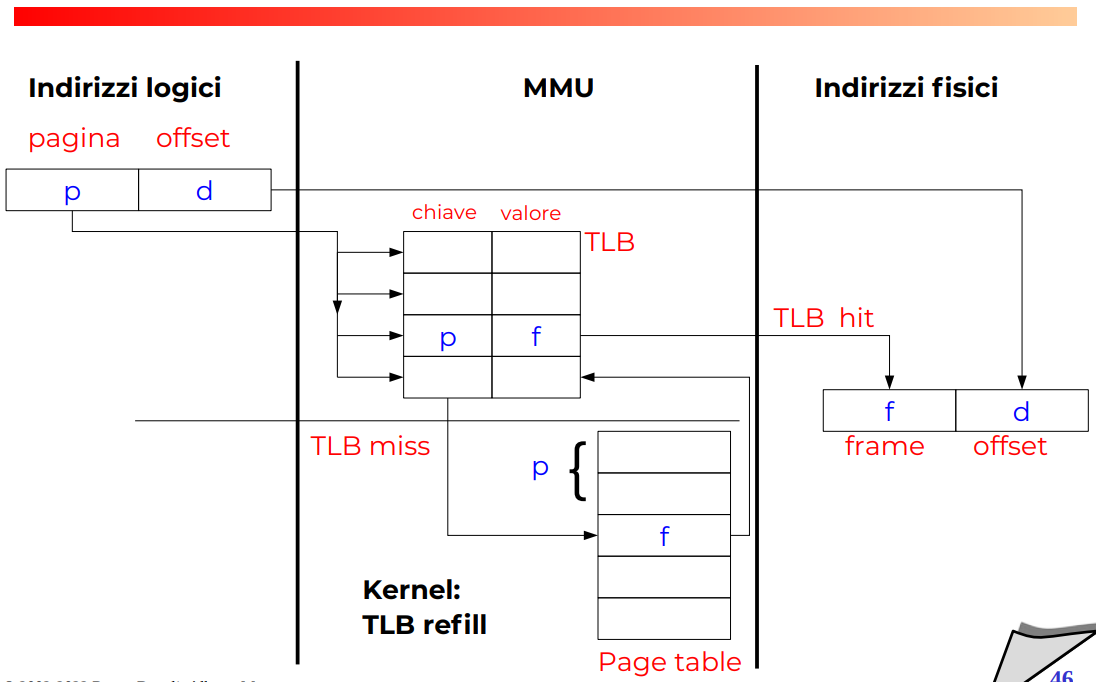
Quando il TLB missa, crea una trap, e iil sistema operativo rimette nella TLB quello che manca. Solitamente se sono grandi 10 celle è già sufficiente, perché principio di località è molto imporntante
Paging di x86
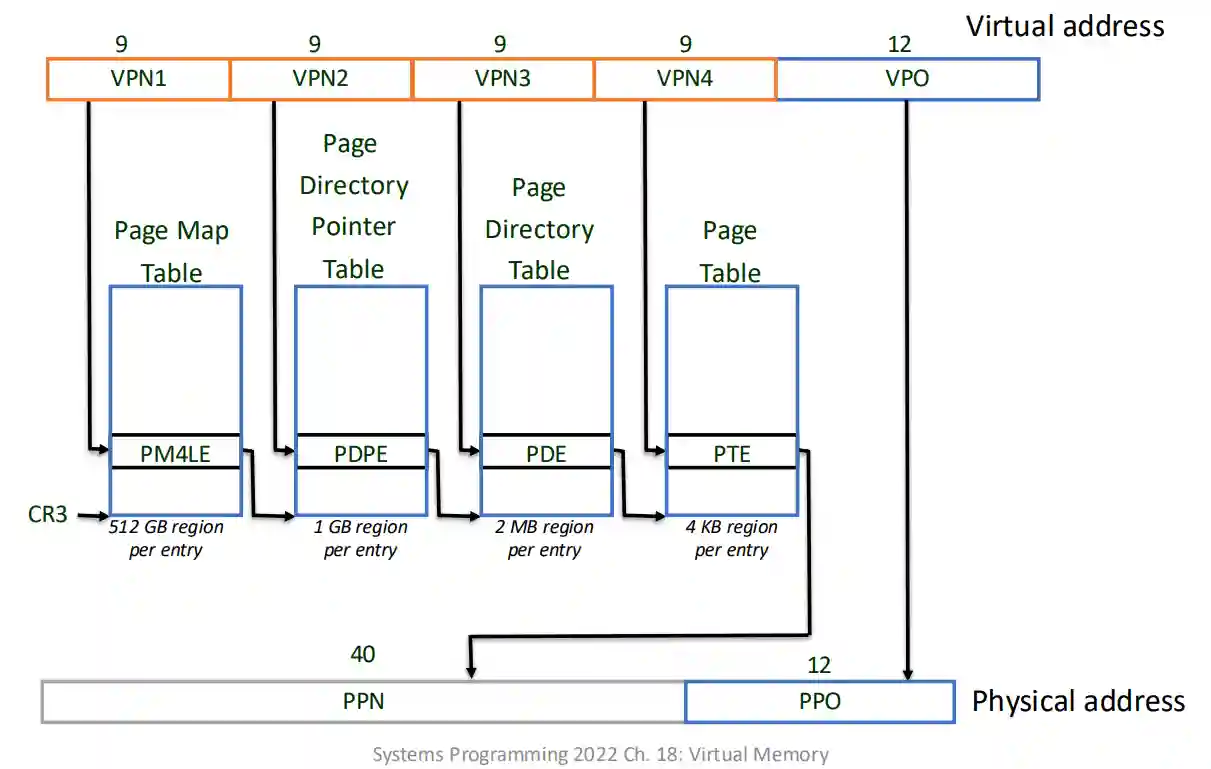
- 4 livelli di indirizzamento per salvare spazio di memoria. Questo solitamente è molto lento da percorrere, quindi si spera che il TLB sia in grado di risolvere la maggior parte delle richieste.
Segmentazione
Introduzione idee segmentazione
Anche questo ne abbiamo già parlato in architettura Livello OS. Comunque divido il programma logicamente in diverse sezioni
- Concettualmente diversi (quindi regole di accesso diverse)
- Le singole aree contengono codice omogeneo (e.g. Testo → area codice).
- Esempio di aree di segmentazione
 Allora se dividiamo in questo modo individiamo l’indirizzo logico come
Allora se dividiamo in questo modo individiamo l’indirizzo logico come
(nome-segmento, offset del segmento) → indirizzo fisico.Ma come fare a ricondurre questo con le pagine? Come metterlo dentro la MMU? Vedremo l’utilizzo di una tecnica ibrida che unisce segmentazione con paginazione.
Confronto con paginazione (!)
-
Slide differenze segmentazione e paginazione

Allocare segmenti in memoria è totalmente simile all’allocazione di zone di memoria contigue in memoria quindi devo tornare ad utilizzare algoritmi per memoria continua, per questo motivo ho forti problemi di frammentazione, quindi torno ad avere problemi come in precedenza!
Implementazione segmentazione
Per i motivi di sopra, utilizzo la paginazione per andare con segmentazione, divido i segmenti in pagine!
Questo implica aumento della frammentazione interna. dato che per ogni segmento posso perdere pezzi nella pagina allocata (però alla fine è molto ininfluente, al massimo 4k di ram per pagina)
-
Implementazione slide

Eccesso del segmento → segmentation fault ecco da dove deriva il nome 😀