Il processo e la gestione dell’esecuzione è uno dei compiti principali dei sistemi operativi. Lo vuole fare in maniera efficace ed efficiente, come descritto in Note sull’architettura.
-
Slide schema generale tabelle
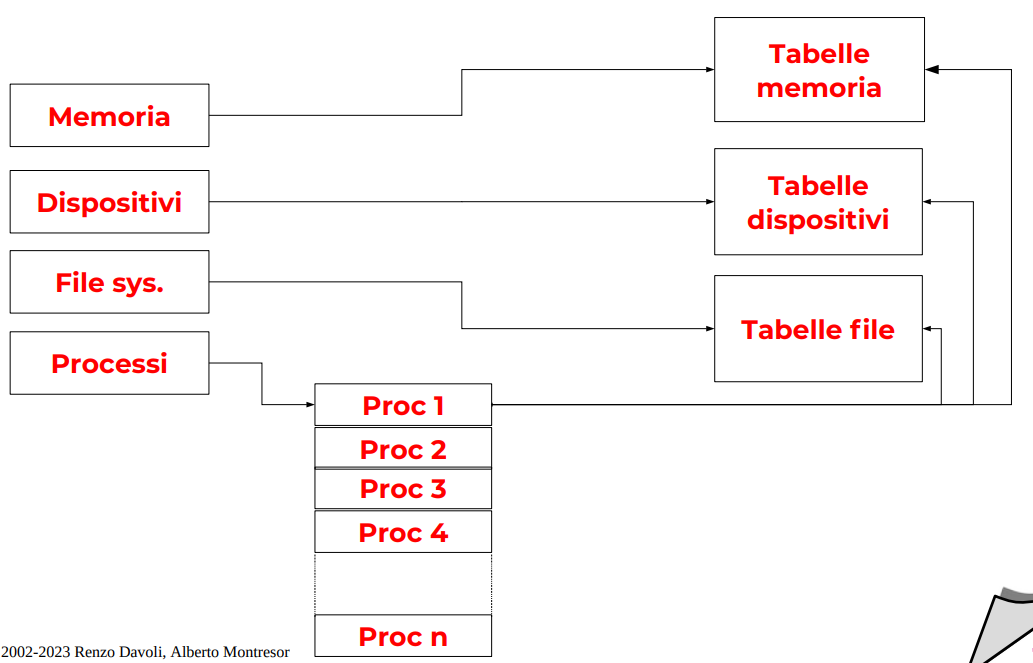
Processi
Il process control block è la struttura di dati principali da comprendere.
Ha una tabella dei file aperti, che sono dei file descriptor (all’interno della propria struttura di dati), riferiti a una tabella dell’interno sistema credo, e questi puntano a un VNode che permette di localizzarlo nella memoria secondaria.
Descrittori di processi (4)
È anche un aspetto dei descrittori dei processi.
-
Slide descrittori

-
Ho bisogno del codice segment code
-
Uno stack su cui lavorare, quindi memorizzare le cose temporanee
-
segment data per i dati necessari
-
Il PCB per gli attributi necessari per disattivare attivare, o comunque descrive tutto il processo.
Il PCB (3)
Qui si parlano di attributi mantenuti nel PCB, sono di fondamentale importanza per il context switch, descritto in Scheduler
- informazioni di identificazione di processo
- informazioni di stato del processo
- informazioni di controllo del processo
Sono queste le informazioni principali mantenute.
Identificazione del processo
- indice nella tabella dei processi (problema di reincarnazione, se ho un nuovo processo al posto di uno che è stato chiuso, allora non potrei riattivare un processo col vecchio pid), così magari tutte le reference vecchie restano, con l’indice non riesco a farlo, potrebbe essere stato sostituito!
- numero progressivo che sarebbe il PID, che viene mappato al relativo descrittore, possiamo dire che il PID è un identificatore logico! Che poi viene risolto al descrittore vero.
Altre identificazioi come utente, gruppo, pid del padre, in modo che possa controllare l’accesso e le limitazioni del processo.
Informazioni di stato del processo
Ho la necessità di avvicendare i processi, quindi ho bisogno di qualcosa per fermare e riattivare i processi, questa sezione di informazione è utile per questa parte.
È importante che questi valori sono presenti i valori dell’ultimo salvataggio perché salvo solo quando devo switchare, se sto runnando non ha senso che utilizzi queste cose.
- Contenuto dei registri, normali e speciali (questi vengono persi quando facciamo switch), si potrebbe chiamare come se fosse una istantanea dei registri.
- La memoria in RAM è meglio mantenerla, quindi non andiamo a ricordarlo.
informazioni di controllo del processo
Una lista enorme di cose per il controllo, cioè in questa parte c’è tanta roba!
- Scheduling (forse più importante come priorità, tempo di esecuzione etc).
- Gestione memoria, MMU.
- Risorse utilizzate (quindi accounting delle risorse)
- Comunicazione con altri processi.
-
Slides


Stati dei processi (3)
Possiamo generalizzare lo stato del processo come se avesse principalmente 3 stati:
- Running, il programma sta runnando senza problemi
- Waiting, il processo non può essere eseguito perché sta aspettando qualcosa, es. un I/O
- Ready, il processo non è eseguito, ma può essere continuato quando la CPU ha tempo per dedicare ancora tempo a questo.
-
Slide stati processi
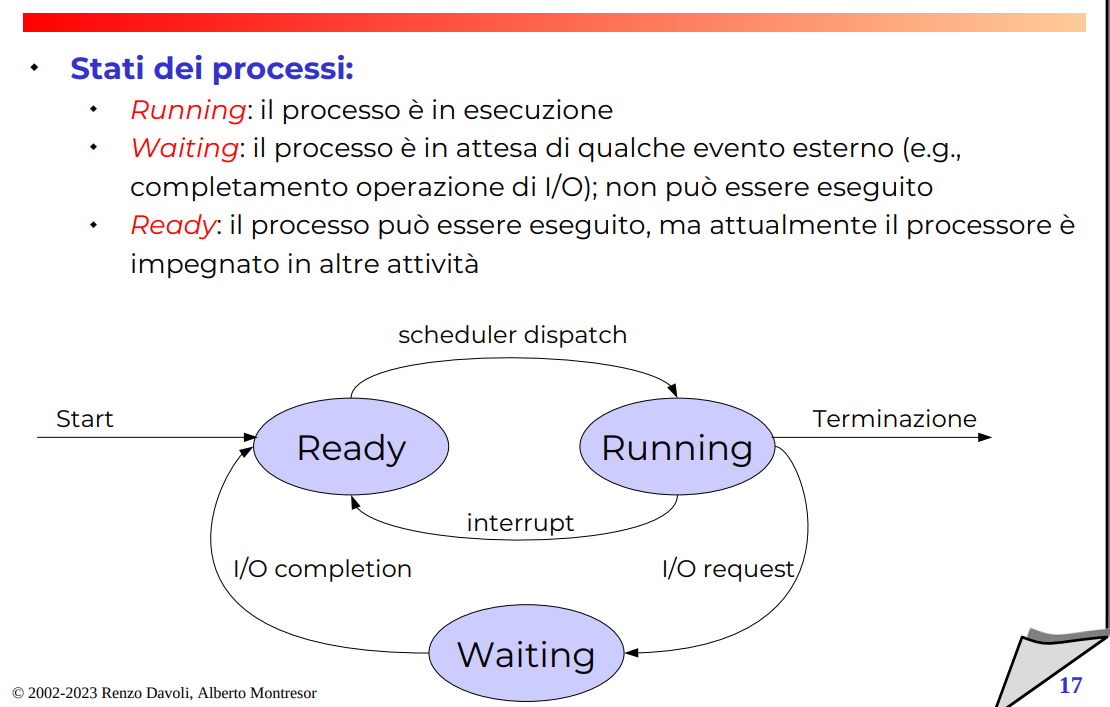
La cosa carina che sembra essere descrivibile dallo schemini simili agli automi Grammatiche Regolari.
Solitamente per gestire tutto l’insieme dei processi ready, lo si mette in una coda ready, ma esistono anche altre code come disk queue, terminal queue.
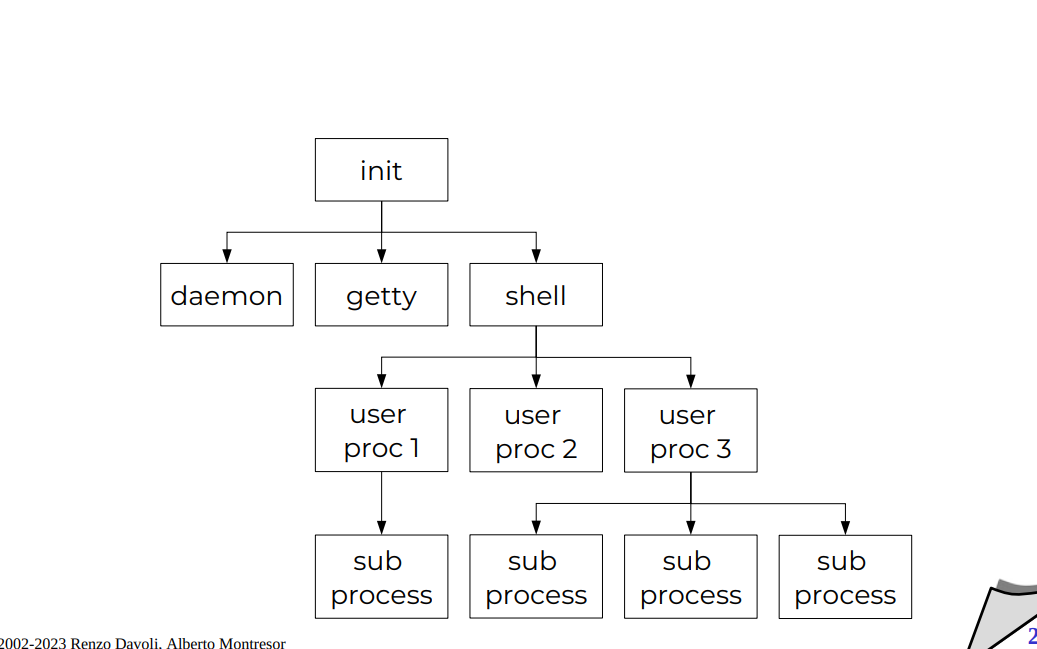
Gerarchie di processi
È molto facile fare cose a sua immagine e somiglianza, ci sono molti campi in cui basta fare una copia, e ho la maggior parte delle informazioni che mi interessano.
Specifico solo quello che cambio. Questo rende molto facile creare nuovi processi, basta cambiare ciò che è diverso!
-
Sistema gerarchico UNIX
Bound sui processi (2)
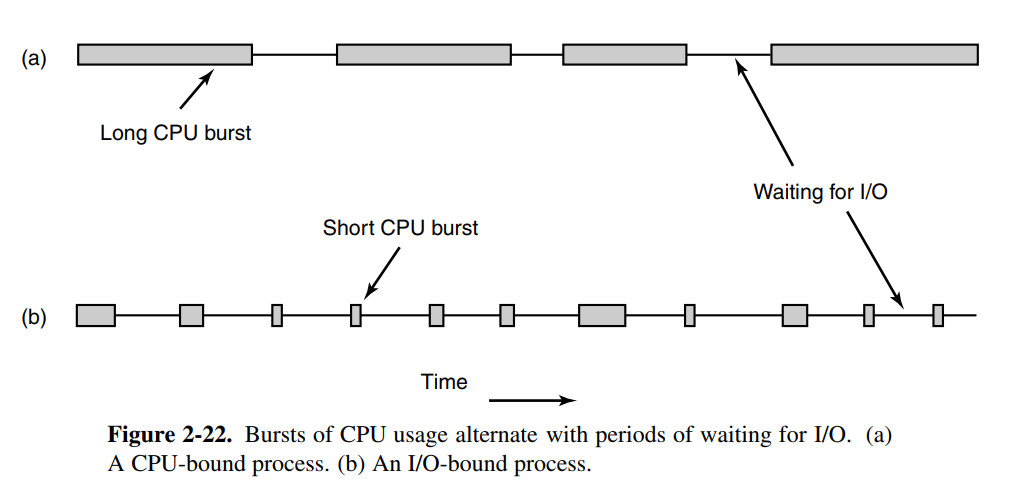
Si può dire che un processo sia CPU bound, I/O bound, queste sono le cose che interessano poi allo Scheduler per decidere cosa fare.
il primo, CPU, quando fa calcoli che sono molto lunghi.
Il secondo I/O, quando fa richieste IO che prendono molto tempo.
In generale i processi si possono descrivere come in alternanza continua fra CPU use e richieste IO.
-
Slide descrizione bounds processi
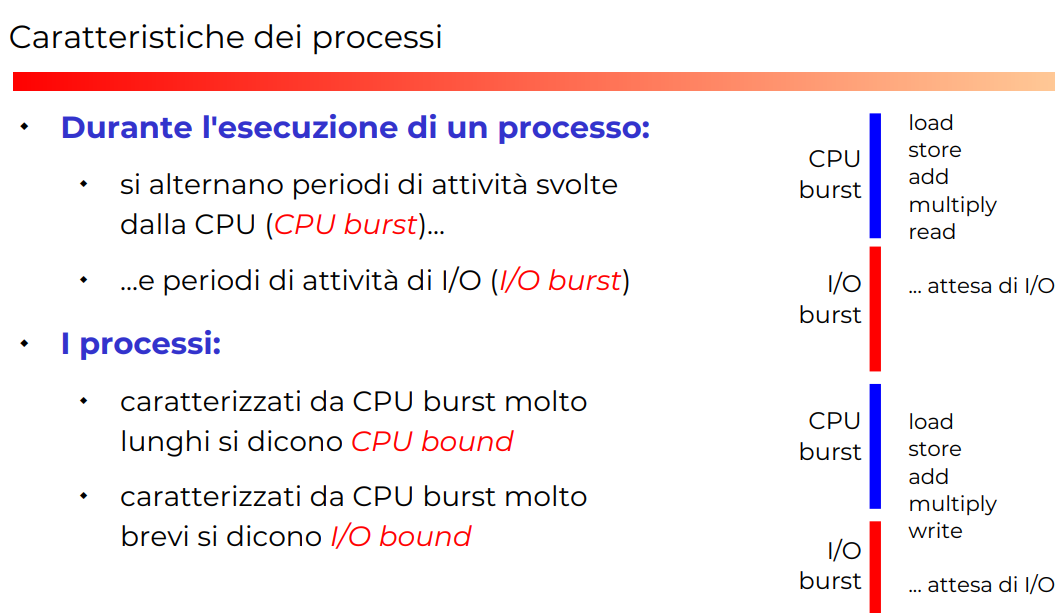
-
Esempio di CPU e IO bound
Threads
Il processo è il titolare delle risorse di elaborazione ma può eseguire solamente una cosa alla volta. Con i thread possiamo dividere il processo in più linee esecutive che condividono delle risorse.
Questa è una cosa molto comoda, per esempio quando ho un browser ho bisogno di un altro thread per scaricare in modo contemporaneo più file. Sono più linee di controllo. ma più vantaggioso rispetto a fare processi separati, perché mi permette la più facile condivisione di risorse. (dovrei mettermi a mandare messaggi anche per cose banali, quindi anche leggero overhead, per copiare molte informazioni Message Passing).
Vantaggi sui processi
- Condivisione di memoria facile
- Molto più facile fare context switch di thread che di processi. (può essere un ordine di grandezza più veloce)
- Facilità di scrittura del codice, rispetto a message passing e più processi.
I lati negativi sono:
- Molti descrittori
- Molti context switch
Quindi utilizzo leggermente più risorse con i thread.
Informazioni dei thread (2)
ha informazioni parziali rispetto al processo, con cui condividono un sacco di cose, come dati, I/O, e il codice del programma.
- Stack separato.
- Program counter proprio, dato che voglio una storia esecutiva indipendente. (e quindi anche propria copia dei registri).
In questo modo sposto il livello di running e waiting al singolo thread.
Kernel e user thread
Questo la saltato boh
Però ora sono tutte livello kernel e user non viene più utilizzato.
La differenza sta nel fatto se il kernel sia a conoscenza o meno dell’esistenza dei threads (se è a consocenza per esempio ci può fare scheduling, mentre altrimenti no, però se ne è a conoscenza deve tutto essere gestito dal kernel, questo in qualche modo rende molto più pesante la gestione).
Relation threads
Anche questi sono stati saltati