TODO: write the introduction to the note.
JSONiq purports as an easy query language that could run everywhere. It attempts to solve common problems in SQL i.e. the lack of support for nested data structures and also the lack of support for JSON data types. A nice thing about JSONiq is that it is functional, which makes its queries quite powerful and flexible. It is also declarative and set-based. These are some commonalities with SQL.
JSONiq on RumbleDB supports many many data types and many storage systems (classical S3, HDFS, local file systems) and lake houses (which works both as a data warehouse (editable) and a data lake).
Sintax of JSONiq
Atomic operations
Simple Arithmetic operations
JSONiq allows to have some simple arithmetic operations like 1 + 1 or 3 * 4 or 5 - 2 or 10 div 2 or 10 mod 3.
Objects
We can create objects using the following syntax:
{
"attr" : 1,
"attr2" : 2
}
Which is just the classical syntax for JSON objects.
Arrays
It’s easy to create arrays using this simple syntax:
{
"attr" : [1, 2, 3, 4]
}
We can also extract a certain item inside the array:
json-file("data.json")<a href="/notes/1">1</a>
Get’s the first item of the array (but here it starts to count from 1).
We can extract the content of the whole array using the [] syntax
json-file("data.json")[]
Composability
JSON-iq allows a quite dynamic composition of the above atomic operations we presented.
Dynamic JSON construction
We can dynamically compute the value in an array, something similar to:
{
"attr" : string-length("foobar")
"values" : [
for $i in 1 to 10
return long($i)
]
}
Precedence of operations
From most important to least:
Comma Data Flow (FLWOR, if-then-else, switch…) Logic Comparison String concatenation Range Arithmetic Path expressions Filter predicates, dynamic function calls Literals, constructors and variables Function calls, named function references, inline functions
Switch and if conditions
We can use the switch and if conditions to make the query more dynamic:
{
"attr" : switch(1)
case 1 return "one"
case 2 return "two"
case 3 return "three"
default return "other"
}
{
"attr" : if (1 = 1) then "true" else "false"
}
Try catch
We can use the try-catch block to handle exceptions:
{
"attr" : try {
1 div 0
} catch * {
"Division by zero"
}
}
Let expression
These are also called FLWOR (pronounced flower) expressions: for, let, where, order, group.
As in every other functional language, we can use the let expression to define a variable:
{
"attr" : let $x := 1 return $x + 1
}
But this variable is just the substitution of an expression, it is immutable.
Other expressions
JSONiq also supports other classical database query operations like, filtering (WHERE), ordering and grouping.
Example of JSONiq expressions from page 395 of ({fourny} 2024).
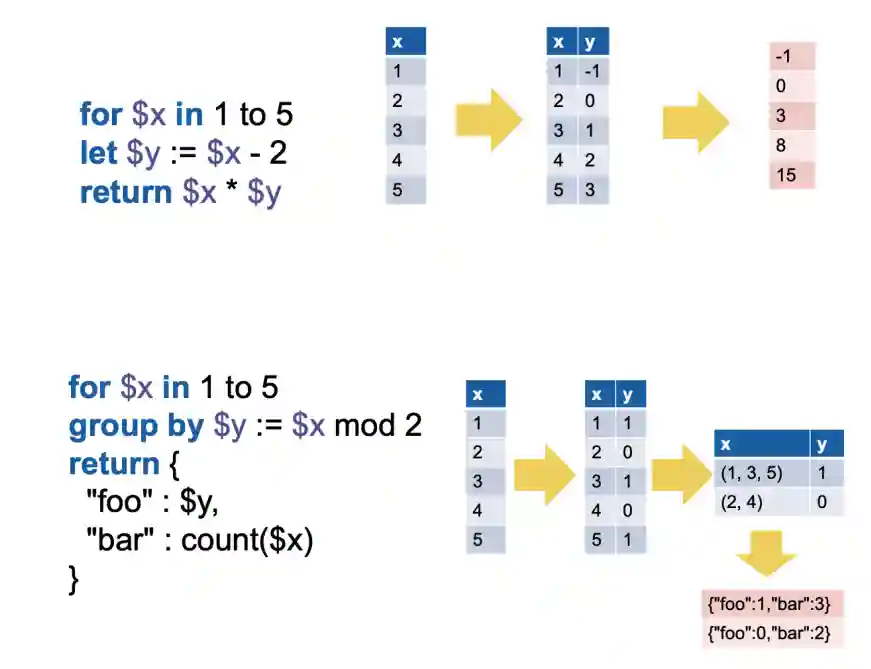
Trasversal
In origin techniques like XPATH were developed for XML trasversal. JSON has introduced a much simpler syntax, the one that is used also for JSONiq, which uses a dot syntax. It is possible to navigate into objets with dots, similar to object-oriented programming.
{
"attr" : json-file("data.json").attr
}
On a similar note, there is also an operator called array un-boxing that returns a sequence of items from an array:
{
"attr" : json-file("data.json").attr[]
}
Simple Filtering
We can filter the data using the where keyword:
{
"attr" : json-file("data.json").attr[$$ > 10]
}
Where the $ syntax represents the current member being tested.
Types
Variable types
In JSONiq we have a syntax to define the arity of a certain variable:
*for any number+for one or more?for zero or one- If there is no suffix, it means exactly one.
Type Casting
We can cast types using the cast as syntax:
(3.14, "foo") instance of integer*,
false
([1], [ 2, 3 ]) instance of array+
true
We can cast explicitly and throws error if it is not possible:
"3.14" cast as integer
Or we can check if it’s possible to cast it
"3.14" castable as integer
Which returns a boolean.
We also have treat which just checks if the type is correct else throws error, without changing the underlying type:
"3.14" treat as integer
One quite advanced feature is typeswitch
typeswitch (1)
case integer return "integer"
case string return "string"
default return "other"
Types in functions
Functions can be typed or not typed, in the same way as python can have type annotations or not:
declare function foo($x as integer) as integer {
$x + 1
}
But also the following will work:
declare function foo($x) {
$x + 1
}
Type Validation
We can also define schemas and validate the type of a certain variable using the validate keyword:
declare type histogram as object {
"name" : string,
"values" : array
}
validate {
"name" : "histogram",
"values" : [1, 2, 3]
} as histogram
Architecture of the Engine
RumbleDB is an implementation of the JSONiq language.
The creation of syntax tree
We use technology that has been first developed for compilers:
- We create the abstract syntax tree
- This gets converted to an expression tree (using the Visitor Pattern, studied in Design patterns).
- This tree gets optimized (inferring types for example is a useful optimization thing, e.g. if I know that it’s a boolean that gets returned, I can optimize a lot for the space).
- The Expression tree is converted to an Iterator Tree, which has every information to run the code. This is what is called query plan.

Simple example of optimization
Materialization
When a sequence of items is materialized, it means that an actual List (or Array, or Vector), native to the language of implementation (in this case Java) is stored in local memory, filled with the items.
This is possible only if the elements are small enough to fit into memory (RAM). Another drawback is that it is usually sequential (not parallelized).
Streaming
This is usually used when the data is too big to fit into memory -> We produce and consume elements in chunks or one by one. The main advantage we have with streaming is efficient memory usage, we don’t need to allocate too much memory. A common pattern is the Volcano Iterator:
- We open the file.
- Call
hasNextto check if there are things to consume, if yes it it retrieved and consumed. - Continue to consume until nothing is left.
We still have the sequentiality. But another reason is that it is not compatible to some operations, like grouping. One advantage is that it usually doesn’t crash, unlike parallel execution which is more probable (more difficult to orchestrate a cluster with so many elements).
Group by, Orderby clauses need to be materialized and not streamed, as we cannot know if the group is complete or not, we can just process one and forget all the ones before.
Parallel execution
We use the ideas in Massive Parallel Processing, use RDDs to parallelize the execution all over the cluster. In some cases it is not convenient to parallelize: it has a fixed cost to instantiate the execution! And usually takes more machines :). So it pushes down to Spark to do some parallel processing with java or sparksql code, which is hidden from the user. (this is called user defined function as this is what gets executed). If the data is homogeneus, it can use dataframes implicitly, as they are more efficient to process and store.
We can improve over these kinds of solutions.

References
[1] {fourny} “The Big Data Textbook” Self Published 2024