6.1 Codifiche
Si utilizzano codifiche, che sono delle convenzioni, qualcosa che un gruppo di umani ha deciso fosse utile darci un significato.
6.1.1 Codifica posizionale
Dove $d_i$ è il valore in posizione $i$ e $b$ è la base
$$ \sum_{i=0}^k d_ib $$6.1.2 Ottale, esadecimale e binario
Queste sono le codifiche principali per i computer in quanto sono comodi da visualizzare. Inoltre Ottale e esadecimale in particolare sono riassunti dei binari, cioè sono dei sottoinsiemi che possiedono ancora tutte le caratteristiche e quindi sono comodi

6.1.3 Conversione di base
Se la conversione è fra ottali, esadecimali o binari allora è molto semplice perché basta prendere un gruppo di bit e caricare un numero a seconda di quanto valga, la conversione dovrebbe essere abbastanza semplice.
Anche la conversione da questi in base 10 non è difficile, basta utilizzare la formula in codifica posizionale
Tecnica delle conversioni successive BIN→ DEC
Questa è una tecnica leggermente diversa ma fatta per parti piccoline, parti dal numero più significativo e da lì moltiplichi ogni volta per 2 e aggiungi 1 se c’è.
DEC → BIN
Si continua a dividere per due e si tiene il resto come risultato del numero binario.
Questo corrisponde al contrario delle conversioni successive
6.2 Numeri negativi
6.2.1 Modulo e segno
Un primo modo di codificare è solamente prendere la cifra più significativa come se fosse un uno e contare in modo uguale, ma questa codifica non è molto utile poi per la somma, bisogna inventare un nuovo metodo.
6.2.2 Complemento a 1
Il complemento a 1 è praticamente la negazione del valore di 1. La cosa che non funziona è che la somma non funziona perfettamente, esiste un zero positivo e un zero negativo, mentre invece per il complemento a 2 funziona grazie al modulo.
Questa codifica riesce a fare, dati $k \text{ bit }, [-2^{k - 1} + 1, 2^{k-1} - 1]$ Per esempio -127 e 127
Somma
La somma del complemento a 1 deve tenere conto del riporto se esiste (probabilmente causato dall’esistenza di uno 0 negativo), invece il complemento a due no.
6.2.3 Complemento a 2
Il complemento a 2 è fattibile a con questa formula:
dati $b_{k},b_{k-1}...b_0$ con ogni $b$ i valori in rappresentazione binaria del numero, il numero nella forma decimale corrispondente è
$$ x = \sum_{i=0}^{k-1}b_{i}2^k - b_k 2^k $$In pratica è il complemento a 1 sommato 1, si può vedere mettendo tutti i numeri su un cerchio e notare che il complemento a 2 ha la parte negativa spostata di uno, in particolare si può dire che il complemento a 2 utilizza il modulo.
$k \text{ bit }, [-2^{k - 1}, 2^{k-1} - 1]$, per esempio -128 fino a 127
6.2.4 Codifica in eccesso
Ad alcuni non piace che lo 0 si trovi proprio a 00000000, quindi lo metto a 10000000, così a 0000000 ho il numero più piccolo rappresentabile. In pratica sto sommando due alla k-1 rispetto alla rappresentazione normale di complemento a due.
Scelte, non so perché lo facciano però.
6.3 Floating point
6.3.1 La codifica
Bisogna definire una mantissa(frazione) e caratteristica(esponente) e segno sono gli elementi più importanti per la definizione di un floating point:
In particolare rappresentiamo N come $f \times 10 ^{e}$ con f frazione e e esponente.
La mantissa è definita tramite esponenti negativi.
6.3.2 Overflow e underflow
Questa codifica ha degli errori nella rappresentazione di numeri troppo grandi o troppo piccoli
6.3.3 ISEE 754
Questo è lo standard industriale per codificare floating points numbers.
È costituito da un totale di 32 bit per BINARY32, ma esiste anche il BINARY64 che utilizza un ragionamento molto simile per i floating points:
- 1 bit per segno
- 8 per l’esponente
- 23 per la mantissa
6.3.4 Tecnica codifica
Per trovare la codifica di un floating point, si moltiplica per due il numero che si deve codificare, e ogni volta che l’unità è un uno si mette un uno, altrimenti uno zero, questo perché la moltiplicazione equivale a uno shift a sinistra.
6.4 Caratteri
Creo una funzione binaria per ogni carattere esistente, storicamente si utilizzavano 8 bit per fare questa codifica, di cui i primi 32 erano caratteri speciali per la stampa tipografica, altri erano utilizzati per maiuscole e minuscole e caratteri speciali
6.4.1 ASCII
American Standard Code of information exchange, è la codifica storica per i caratteri, questa codifica però non bastava perché bisognava aggiungere codifiche per caratteri non alfabetici oppure agli emoji
6.4.2 Unicode
è l’espansione con 16 bit al posto di 8 ma sono finiti molto presto e quindi c’è bisogno di qualche altra forma che possa essere molto più sicur
6.4.3 UTF-8
Questa è il nome della codifica moderna che permette di avere molti altri caratteri invece che solamente i caratteri dell’alfabeto inglese. (esempio gli accenti italiani sono codificati con UTF-8)
Dinamico in quanto può prendre da 1 a 4 byte in modo dinamico.
Esiste anche UTF-16 ma non è ancora diffuso come UTF-8
6.5 Errori
6.5.1 Necessità di errori
- Raggi cosmici, (mandare segnali a sonde spaziali è molto facile avere interferenze e gli errori sono comuni)
- Errori di memorizzazione di trasmissione
- Vibrazioni e radiazioni dell’ambiente circostante, quindi vogliamo trasmettere in modo che non ci siano errori di trasmissione.
A volte non c’è necessità di controllare errori: esempio il protocollo UDP
Oppure se voglio fare una transazione il codice di errore allora è molto più importanti
6.5.2 Parola codice
Sto aggiungendo a m bit r bit di controllo e prendo n = m + r come la parola codice che contiene
- Informazioni di controllo correttezza (si prende che ci sia una probabilità molto piccola di errori).
- Informazioni da trasmettere
6.5.3 Costo controllo delle informazioni
C’è una differenza fra la correzione di un errore e il rilevamento, la correzione è molto più dispendiosa. C’è un modo per correggere in modo semplice? Con poco costo?
6.5.4 Distanza di Hamming
Praticamente è il numero di 1 dopo che si ha uno xor fra tutti.
Per rappresentare di mettono n numeri in un cubo n dimensionale, e si valuta la distanza fra i due.
6.5.5 Minima distanza per trovare un errore
The minimum Hamming distance is used to define some essential notions in coding theory, such as error detecting and error correcting codes. In particular, a code C is said to be k error detecting if, and only if, the minimum Hamming distance between any two of its code-words is at least k+1.
Come mai per trovare un errore su d bytes servono d + 1 bits? come mai per corregger di più?
6.5.6 Minima distanza per correggere un errore
A code C is said to be k-errors correcting if, for every word w in the underlying Hamming space H, there exists at most one codeword c (from C) such that the Hamming distance between w and c is at most k. In other words, a code is k-errors correcting if, and only if, the minimum Hamming distance between any two of its codewords is at least $2k + 1$. This is more easily understood geometrically as any closed balls of radius k centered on distinct codewords being disjoint. These balls are also called Hamming spheres in this context.
Assunto massimo un bit sbagliato abbiamo che il codice correttore deve soddisfare
$2^m(1 + n) \leq 2 ^n$
Il bit di parità utilizza tanti bit.
Una parola può essere solo una sbagliata e poi m modi di sbagliarla ancora
6.5.7 Studio del bit parità
In pratica è lo Xor fra tutti i bit della parola, quindi molto utile per scoprire errori di un singolo bit. Utile per rilevare gli errori.
6.5.8 Codice di hamming
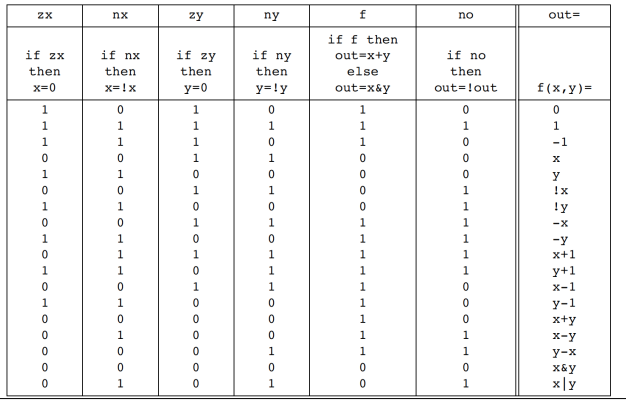
Sull’ALU
Ci sono alcune operazioni interessanti per come l’ALU calcola ciò che calcola
Dimostrazione trucco per sottrazione
!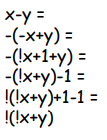
E poi nel caso + 1, basta sommare - 1, che si conosce
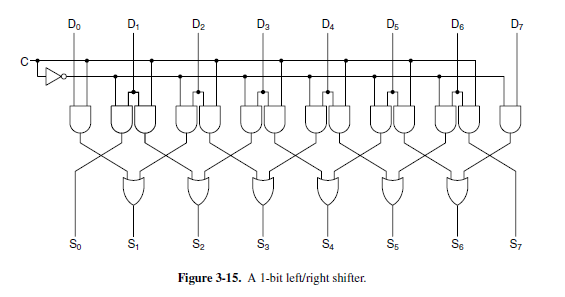
Shifters