The main difference between reinforcement learning and other machine learning, pattern inference methods is that reinforcement learning takes the concept of actions into its core: models developed in this field can be actively developed to have an effect in its environment, while other methods are mainly used to summarize interesting data or generating sort of reports.
Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize the cumulative reward. ~Wikipedia page.
Note: there is a big gap between theory and practise in this field.
Introduzione
Una delle idee migliori riguardanti questo campo del reinforcement learning è il focus sul processo decisionale del singolo agente, condizionato al reward che l’ambiente esterno gli dà (feedback). Il setting classico di questo genere di problemi è un caso speciale della caratterizzazione presente in l’intelligenza.
Abbiamo in questo caso un agente all’interno del suo ambiente. L’agente è in grado di interagire col suo ambiente attraverso alcune azioni ben definite, e l’ambiente restituisce un feedback ad ogni azione. L’agente si regola di conseguenza, nel tentativo di massimizzare il reward che riceve.
È da notare che questa impostazione è molto diversa rispetto al machine learning classico, seppur si può comunque collocare al suo interno. Classifcamente nei modelli di machine learning supervised si cerca di minimizzare un errore con alcuni dataset etichettati, mentre qui non abbiamo nessuna etichetta, mentre nel unsupervised proviamo a trovare alcuni pattern nei dati, mentre qui non cerchiamo nessun pattern. Si potrebbe dire che questo sia un terzo paradigma di machine learning.
NOTA: questi appunti riassumono concetti dai primi 4 capitoli del Sutton and Barto 2020
Un problema classico: n-bandit
Vedere N-Bandit Problem.
History: Deepmind
Deep-Q learning was able to solve many atari games and being better in human performance, that was a very big deal at the time.
Difference with other paradigms
- Only reward/penalty signal, which happens after actions (so its active in time, while other paradigms don’t have time)
- Feedback is delayed in time, could also be sparse
- We have actions that have an effect in future.
Setting classico (Model Policy Reward)
Quando andiamo a parlare di Reinforcement learning andiamo a considerare un setting classico di agente che interagisce con un ambiente attraverso delle azioni, e l’ambiente che risponde attraverso i reward. L’agente osserva quindi lo stato (se è full-observable vede lo stato esterno, altrimenti partially observable vede solamente parte delle informazioni dello stato dell’ambiente) e insieme al reward percepito prova a eseguire delle altre azioni.
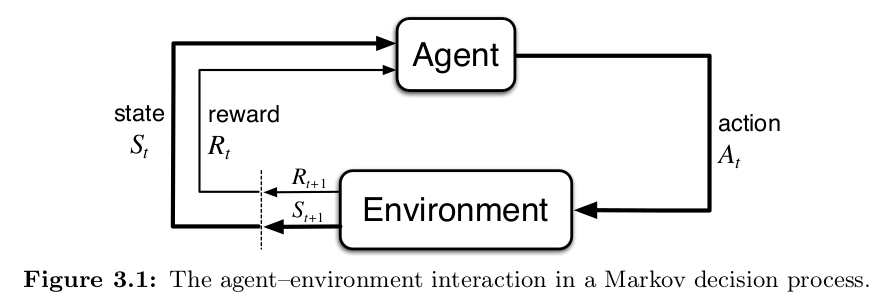
Sono particolarmente importanti quindi 3 parole chiave utili per descrivere una delle 3 frecce in immagine
Model
Il modello dell’ambiente lo indichiamo anche come dinamica o sistema di transizione dell’ambiente. nel modello sono definite tutte le distribuzioni di probabilità che portano uno stato a un altro: $P(s'|s)$, questo possiamo dire, ossia partendo da uno stato s, quanto è probabile finire in uno stato s’ ??
$$ \begin{align} P: S \times \mathcal{A} \to \Delta(S) \\ r: S \times \mathcal{A} \to [0, 1] \end{align} $$Dove $\Delta$ è una distribuzione su $S$.
Policy
La policy è un indicatore delle azioni del singolo agente, ci dice quanto è probabile che l’agente esegua una certa azione, dato che sia sopra un certo stato s, lo indichiamo solitamente con $\pi(a | s)$. Nel caso in cui è una policy deterministica, nel senso che a uno stato corrisponde uno e un solo azione, potremmo scrivere qualcosa del tipo $\pi (s) = a$ Quindi è una funzione $\pi: S \to \Delta(\mathcal{A})$.
Reward
Il reward descrive il feedback che l’ambiente ritorna al giocatore una volta che una azione è stata eseguita, spesso lo indichiamo in questi modi
$$ r(s, a) \\ r(s, a, s') \\ r(s) $$A seconda di quanto vogliamo esprimere (quindi il reward atteso dopo aver fatto una azione da unc erto stato, il reward atteso dopo aver fatto una azione da un certo stato ed essere arrivati a un certo stao e così via
The Value function
$$ v_{i}(S_{j}) = \mathbf{E} [r_{i} + r_{i + 1} + \dots | S_{j}] $$$$ v_{i}(S_{j}) = \mathbf{E} [r_{i} + v_{i+1}(S) | S_{j}] $$Con $S$ uno stato su cui puoi essere al passo successivo.
All components are functions:
- Policies: $\pi: S \rightarrow A$ (or to probabilities over A)
- Value functions: $v: S \rightarrow R$
- Models: $m: S \rightarrow S$ and/or $r: S \rightarrow R$
- State update: $u: S \times O \rightarrow S$
Categorie di agenti
Policy - Value categorization
Value Based
ha solamente value based, la sua policy è basata sul suo valore (in modo greedy va a cercare quale sia lo stato con valore maggiore) Esempi sono Monte Carlo, SARSA, Q-learning, DQN.
Policy based
Il contrario, non ha value function, ma solamente la policy, tenta direttamente Policy Gradient, NPG, TRPO, PPO.
Actor Critic
Ha entrambi, ha sia policy (l’attore) e il critico che cerca di aiutare. Questi sono anche chiamati model based.
Models
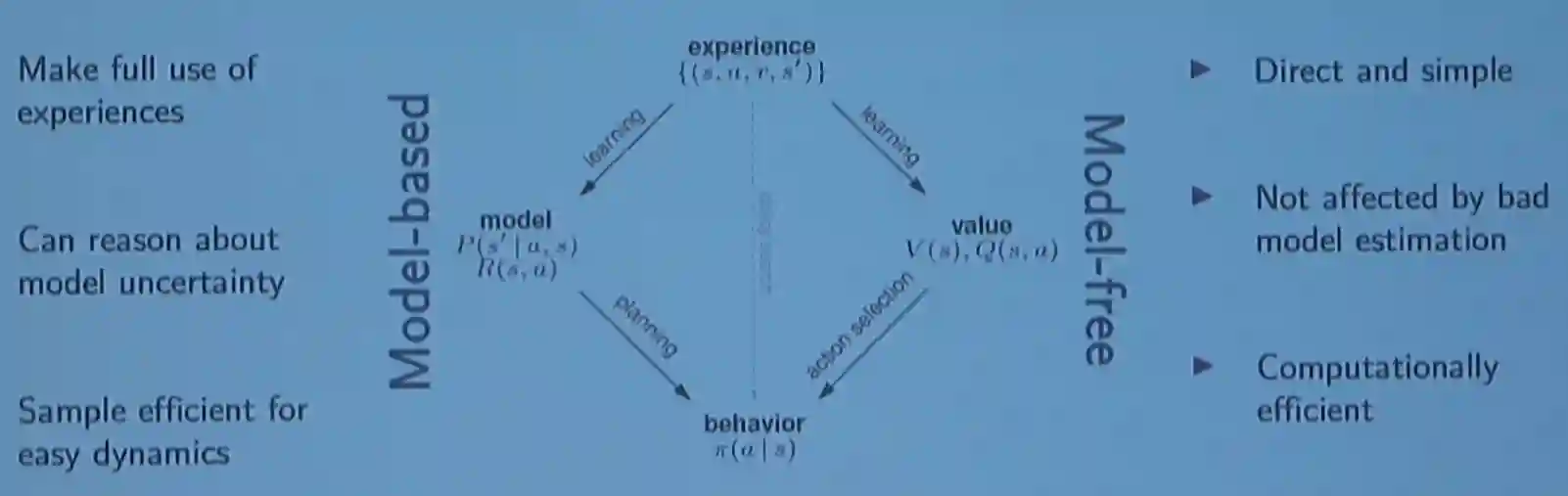
Model free
Se hanno policy o value, ma non hanno nessun modello sull’ambiente in cui sono presenti Solitamente sono molto semplici, e permettono di imparare direttamente la policy migliore possibili per questo ambiente. Secondo il professor Buhmann non ha senso parlare di model free perché qualunque modello implicitamente ne ha uno.
Model based
Hanno il modello dell’ambiente, e non necessariamente hanno policy o value function. Questi potremmo anche chiamarli (Ha & Schmidhuber 2018). Solitamente questi permettono di utilizzare l’esperienza meglio (+ sample efficient).
Other definitions
Prediction and control
Prediction è la capacità di sapere come sarà il futuro Control è la capacità di ottimizzare la propria value function. Solitamente sono molto legati fra di loro.
Episodic and Non-episodic
Episodic -> We have a collection of episodes, each of which gave us new trajectories about it. We can reset the environment as we like Non-episodic -> We learn this online, each one yields a single trajectory, we can’t reset.
Online vs Offline RL
Per i modelli online possiamo andare direttamente ad agire sull’ambiente per ottenere dei dati. Si parla di exploitation exploration tradeoff. Solo che bisogna stare attenti perché ci può essere un rischio per certe azioni. Per esempio una macchina potrebbe schiantarsi quando esplora, perché lo sta facendo nel mondo reale. Per i modelli offline abbiamo già collezionato un sacco di dati, e possiamo usare questo per cercare di creare un modello ed imparare. Sono anche chiamati batched RL.
On-policy vs Off-policy RL
Con on-policy è sempre un RL online, in cui andiamo ad imparare utilizzando la policy attuale. Con off-policy stiamo usando una policy diversa per andare ad imparare la nostra policy finale. Magari abbiamo un buffer in questo caso che utilizziamo per memorizzare in modo temporaneo le nostre informazioni.
Model based and Model free
Model-based -> We want to create a world model, and try to estimate the state transitions and the rewards Model-free -> We just try to learn enough to act well: we just estimate the value of a single state.
Markov chains
Dovrebbe essere approfondito meglio in Markov Chains
References
[1] Ha & Schmidhuber “World Models” 2018