3.1 Introduzione
3.1.1 Cosa sono
Le strutture di dati si interessano solamente di come memorizzare i dati, non necessariamente va a memorizzare un tipo di dato concreto.
Quindi + sul come - sul cosa.
3.1.2 Prototipo e implementazione
Avevamo introdotto la differenza fra algoritmo e programma all’inizio del corso, andiamo ora a definire la differenza fra prototipo e implementazione:
Prototipo:
va a fare una descrizione dei metodi che deve avere una determinata struttura di dati. Lo puoi intendere come una specie di interfaccia.
Implementazione:
È la creazione del programma in un determinato linguaggio di programmazione
3.1.3 Distinzioni generali fra strutture di dati
Le strutture di dati vengono distinte principalmente secondo 3 fattori
Linearità vs non-linearità (sequenzialità degli elementi es std::set, std::unordered_set
Staticità vs dinamicità (es array e vector)
Omogeneità vs eterogeneità ( che tratta dei tipi di dato che sono memorizzabili
3.2 Dizionario
3.2.1 Prototipo (proprietà caratterizzanti)
Questa è una struttura di dati astratta composta principalmente da due cose:
Un insieme di chiavi (uniche) associati a un valore (duplicabili). per questo motivo si può anche chiamare array associativo
Si nota che è una struttura di dati dinamica, riguardo invece linearità e non linearità dipende dall’implementazione.
3.2.2 Operazioni primitive
- Ricerca(Chiave) restituisce il valore della chiave
- Inserimento(Chiave, Valore) crea una chiave con quel valore
- Elimina(Chiave) elimina l’elemento con una determinata chiave
3.2.3 Esempio di implementazione su array ordinato
-
Slide

Le seguenti sono tutte implementazione ad alto livello senza codice
-
Implementazione di Search

-
Implementazione di Insert
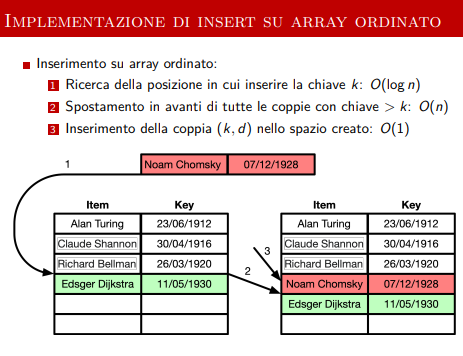
-
Implementazione di Delete
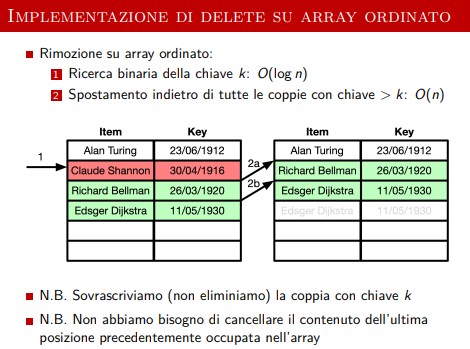
La cosa importante da osservare è la costo asintotico di questa implementazione, ossia l’aspetto che varia a seconda dell’implementazione.
-
Riassunto del costo computazionale di questa implementazione

3.2.4 Esempio di implementazione su lista concatenata
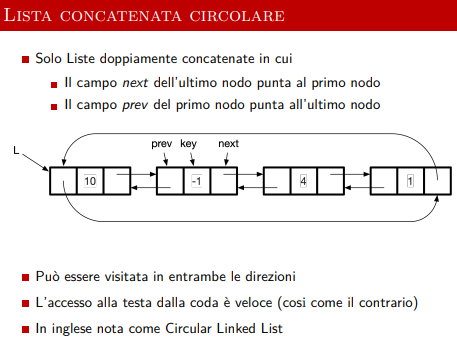
Qui si utilizza una lista concatenata *circolare ** ovvero l’ultimo elemento della lista punta al primo, e il precedente del primo punta all’ultimo elemento, solo per non avere un null.
-
Slide

-
Implementazione di insert/delete
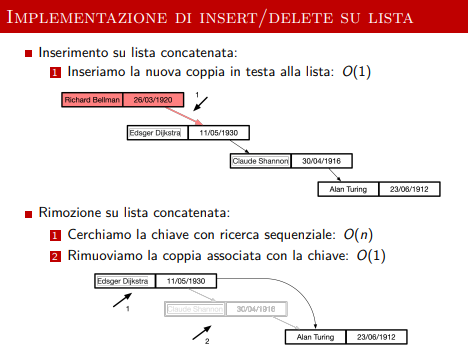
-
Implementazione di Search
Scorri la lista ordinata, lo hai già visto molto spesso 🙂
-
Riassunto costo computazionale lista concatenata

Confronto fra le due implementazioni
-
Slide

In conclusione abbiamo delle velocità diverse, per le operazioni che definiscono il dizionario. La scelta dell’implementazione migliore dipende dalle necessità dell’algoritmo, cosa che si decide caso per caso.
Una osservazione è che lista è dinamica, mentre array ordinato è statico.
3.3 Liste concatenate
3.3.1 Prototipo semplice
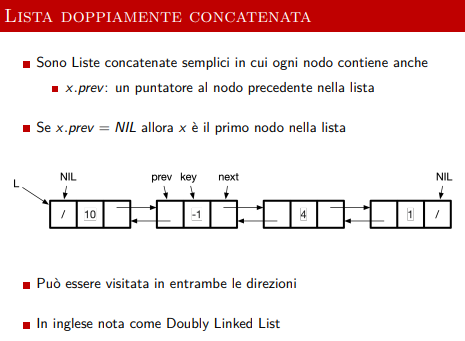
Una lista concatenata bidirezionale semplice è simile a quanto studiato in programmazione, gli estremi sono terminati da dei null.
-
Esempio di lista concatenata unidirezionale semplice
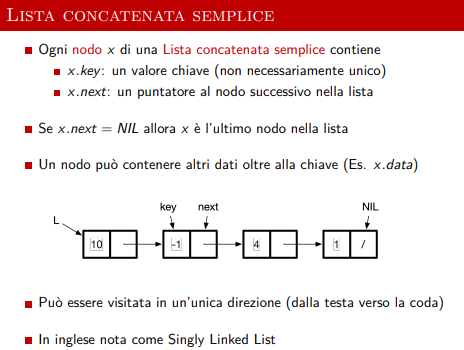
-
Esempio di lista concatenata bidirezionale semplice
Circolare
3.3.2 Prototipo circolare
In particolare qui utilizziamo una lista concatenata bidirezionale circolare.
Ogni nodo contiene il valore, una chiave, e due puntatori al precedente e successivo.
-
Esempio di lista concatenata circolare
3.3.3 Operazioni elementari
Sono tre le operazioni principali per una lista concatenata
-
Search

-
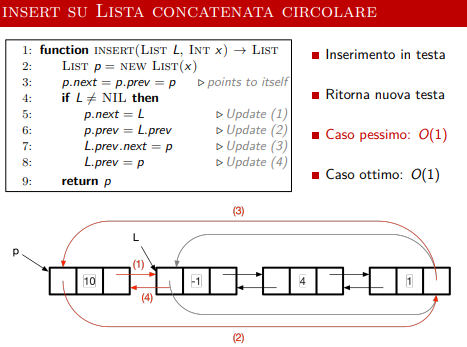
Insert
-
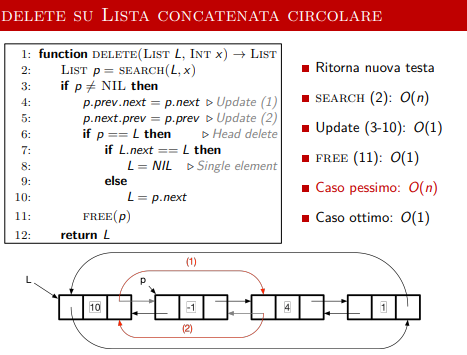
Delete
3.4 Pile
3.4.1 Prototipo
Vogliamo avere qualcosa che stori le cose come se fossero una pila di elementi. Quindi vogliamo solamente delle operazioni molto semplici. diciamo che è una struttura di dati di tipo LIFO.
Questa semplice struttura di stack è molto comoda: ha delle applicazioni non da poco:
- record delle chiamate
- operazioni per un editor di testo per scrivere e no.
- Parentesi per sintax-parsing
Operazioni elementari
Vogliamo queste cose che siano entrambe molto veloci (costante
PUSH(element)
POP()
3.4.2 Confronto due implementazioni
Possiamo utilizzare una lista o array (senza considerare l’array doubling)
-
Slide

Risposta domanda: perché l’unica cosa che serve è push e pop, non servono altre operazioni da necessitare della doppia concatenazione
Implementazione statica
-
Slide
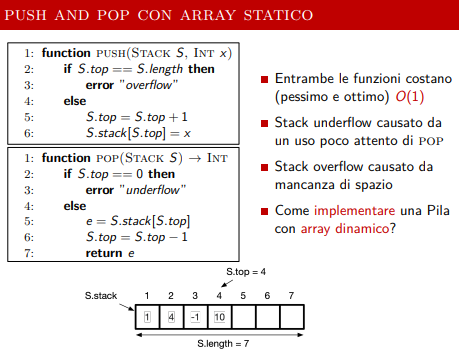
Questa è la classica implementazione. utilizzando l’array statico. ma ha il problema che devo allocare uno spazio in memoria che sia sempre quello. Utilizziamo ora una tecnica che utilizza doubling e halving, per avere un array dinamico
Implementazione dinamica
La cosa buona di questo elemento è che il costo ammortizzato è costante.
-
Slide

Analisi del costo ammortizzato
-
Analisi del push ammortizzato

Nel libro è anche presente una tecnica utilizzando doubling-halving che utilizza l’accantonamento, che si potrebbe dire essere più intuitivo.
-
Analisi del pop ammortizzato (accantonamenti)
Non viene fatto nelle slide, ma è presente sul libro, che incollo qui

3.5 Code
3.5.1 Prototipo
La struttura è molto simile a quella della stack, ma qui l’unica differenza è che invece di togliere il primo che ho messo, tolgo l’ultimo. Come se fosse una coda ad un bar.First in first out
- Scheduling operazioni
- BFS
Operazioni elementari
Enqueue(element)
Dequeue()
3.5.2 Confronto implementazioni (array circolari o liste semplici)
-
Slide di confronto ad alto livello

Implementazione con la array circolare
Questa implementazione non è presente nel codice java sorgente.
-
Slide

3.6 Alberi
Di più inAlberi BST e AVL
Cose importanti per l’albero sono:
- Nodi
- Archi
- (singolo percorso fra un nodo e un altro, questa è la differenza principale con i grafi)
Poi possiamo identificare anche un ordine sui figli, radicato. **se ho unnodo come radice.
3.6.1 Prototipo
Come un albero binario di ricerca…
3.6.2 Operazioni elementari
Lo scorrimento di un albero nei 3 modi: pre-ordine, in-ordine, post-ordine utilizzando gli algoritmi come DFS e BFS