Introduzione alle Tabelle di Hash
5.1.1 Prototipo
Vogliamo implementare le operazioni del prototipo dizionario presentato in Strutture di dati elementari, e vogliamo fare solo queste 3 ma molto bene.
- Insert O(1)
- Delete O(1)
- Search in O(1)
La struttura dati di hash riesce a fare bene queste singole operazioni
Si vedrà che l’array modificato è il modo migliore per avere questo hash, solo generalizzando un modo per indicizzarlo che non saranno numeri (indici).
Noteremo che in media hanno operazioni costanti queste tabelle di hash (nel caso peggiore sempre lineare).
Esempi di utilizzi soliti
Nei compilatori di solito è molto utilizzato per mantenere in memoria il mapping con le variabili e simili
Tabelle ad indirizzamento diretto
Queste tabelle di hash sono altresì chiamate array, in quanto il numero di chiavi utilizzate è esattamente uguale al numero di chiavi presente nel nostro universo di chiavi.
Ma per uso pratico questo sarebbe improponibile, in quanto vorremmo avere come chiavi anche stringhe, ma il numero di chiavi esploderebbe in maniera esponenziale e un utilizzo di memoria esponenziale non è buona…
Tempo O(1)
Spazio O(n) con n il numero di chiavi nell’universo.
Tabelle di hash (idea)
Idea vorremmo in qualche modo trasformare un elemento nel nostro insieme di chiavi possibili in un elemento appartenente solamente al nostro spazio di chiavi utilizzate.
Cioè ridurre senza collisione (ovvero per input diversi, ottengo uno stesso output) una chiave nell’universo più esteso in un numero utilizzabile.
-
Slide

In questo modo riduco lo spazio utilizzato solamente a O(K) dove K sono le chiavi effettivamente utilizzate, deciso da caso a caso.
-
Riassunto della ricetta dell’hashing

Riassunto:
- Funzione di hash che mi riduca le chiavi dell’universo totale all’insieme delle chiavi utilizzate Queste devono essere veloci nel calcolo
- Minimizzare le collisioni
- Implementazione concreta come può essere un vettore di una certa dimensione, che contenga effettivamente il valore dell’hash in quella zona. (possibile anche ridimensionamento)
5.2 Le chiavi
Le chiavi sono uno strumento principale per comprendere le tabelle di hash. Sono il modo con cui troviamo il nostro valore e sarebbe bene cercare di definirlo in un modo più formale
5.2.1 Universo delle chiavi e insieme chiavi effettive
- Definiamo un insieme astratto di tutte le chiavi possibili
- Definiamo le chiavi effettive il sottoinsieme dell’universo delle chiavi, che contiene le chiavi effettivamente utilizzate in un momento
-
Esempio

Caratteristiche delle chiavi per le funzioni di hashing
- Le chiavi devono essere distribuite in maniera uniforme (questo è il caso migliore per evitare il più possibile delle collisioni)
- Le chiavi devono essere sempre positive o nulle
La prima assunzione è necessaria per l’analisi della nostra funzione di hash. Semplifica abbastanza direi.
La funzione di hash
Cerchiamo qui di definire alcune proprietà di una buona funzione di hash.
Distribuzione uniforme semplice
Se soddisfa questa proprietà, ho una buona probabilità che io stia distribuendo i valori presenti in modo uniforme nel nostro spazio delle chiavi utilizzate (questo però non implica l’assenza o minimizzazione di collisioni!)

È difficile dimostrare o calcolare la distribuzione di probabilità di una funzione di hash.
Però dall’altra parte sono sicuro se prendessi una chiave a caso in un intervallo di mia scelta allora ho finito, ho dimostrato che sono distribuite in modo uniforme.
5.3.2 Costo computazionale costante
Deve essere abbastanza semplice da avere un costo costante nel suo calcolo, altrimenti l’intera tabella avrebbe il costo di questa funzione, rallentando l’intera tabella.
Esempi di funzioni di hash (4)!!!
Rappresentazione della stringa in intero:

Questo metodo cresce insieme alla lunghezza della stringa, quindi di solito non è una buona cosa farla in questo modo.
Vantaggio: posso rappresentare qualunque cosa che si può rappresentare sul calcolatore
Svantaggio: lo spazio cresce in funzione alla grandezza dell’input.
Riduzione in modulo
Questa è in pratica una divisione.

Nella slide sono mostrati anche vantaggi e svantaggi di questo metodo. (principalmente perché se il modulo è preso brutto, ignora gran parte delle informazioni, quindi ottengo un hash che non mi rappresenta totalmente questo numero)
Costante m descrive la funzione di hash in modo molto importante! (anche l’uniformità)
Metodo della moltiplicazione
Vogliamo introdurre maggiore scombinamento dell’input, questo si può fare moltiplicando il valore di hash per qualcosa.
-
Esempio in slide

Costante C descrive l’uniformità di distribuzione
Metodo codifica algebrica

Riguardo al calcolo di questa codifica esiste il metodo di horner che permette la computazione di questo hash in maniera lineare rispetto all’input.
Regola di Horner

Soluzione delle collisioni
-
Slide

Vogliamo trovare un sistema per risolvere le collisioni, che sono molto più frequenti del solito per
Concatenazione
Una volta presente una collisione lo si inserisce nella lista concatenata presente in quella locazione. Questa lista in posizione precisa la chiamo lista di trabocco.
-
Analisi del concatenamento (ottimo e pessimo)

-
Analisi nel caso medio

Una volta definito questo fattore di carico riesco a dimostrare il costo per la ricerca con successo e senza successo, e si ha che entrambi hanno costo
$\Theta(1 + \alpha)$
Indirizzamento aperto
L’inserimento viene messo nel prossimo slot aperto.
-
Slide
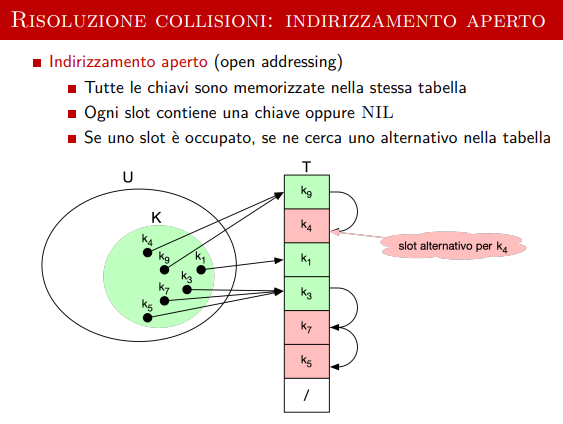
L’idea principale è quella dell’ispezione.
La funzione di hash è estesa con un altra funzione di ispezione che visita gli indici di una tabella permutata in modo sempre che sia visitata ogni cella una singola volta.
-
Pseudocodice per insert, search e delete


L’idea principale è mettere nella cella in cui si elimina un valore deleted per marcare la cancellazione, così search continua a cercare dopo invece di fermarsi, subito (come se avessi perso la testa in un linked list).
Analisi:
Peggiore: devo percorre l’intero array per inserire, eliminare o cercare, quindi O(n)
Medio: dipende dall’ispezione, quindi andiamo ora ad analizzare l’ispezione.
-
Assunzioni

-
Teoremi su ricerca ad indirizzamento aperto

Strategie di ispezione per l’hashing aperto (3)
Ispezione lineare
è in una forma
$h(k,i) = (h'(k) + i) \mod n$
Continua a guardare la cella successiva se quella precedente è occupata.
-
Problema del clustering primario (vicino)
Praticamente è abbastanza probabile che ci siano un sacco di sequenze vicine essere occupate (mentre altre sono basse). È un fenomeno che non si vuole avere!
Toglie l’uniformità di occupazione! cosa che non va bene.

-
Esempio di clustering
Come si vede, le celle di hash 3 sono inframezzate molto! creando quella lunghissima linea di cellette occupate.
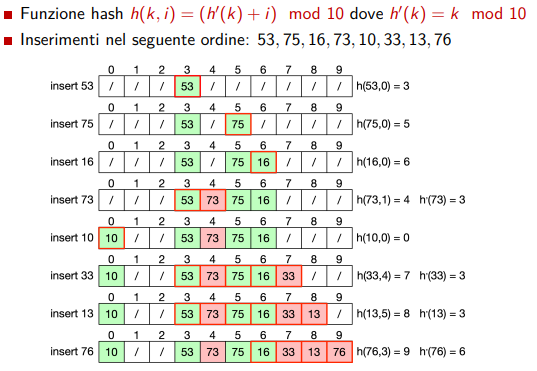
-
-
Analisi del costo medio (differente negli altri due casi esposti qui)

Ispezione quadratica
$h(k, i) = h'(k) + c_1i + c_2i^2 \mod n$
Anche questo metodo di ispezione crea un clustering, che però è secondario, ossia creano collezioni di celle lontano rispetto alla cella trovata.
-
Clustering secondario

Comunque questo tipo di clustering è migliore rispetto al clustering primario
Doppio hashing
$h(k, i) = h_1(k) + ih_2(k) \mod n$
-
Slide

-
Esempio
