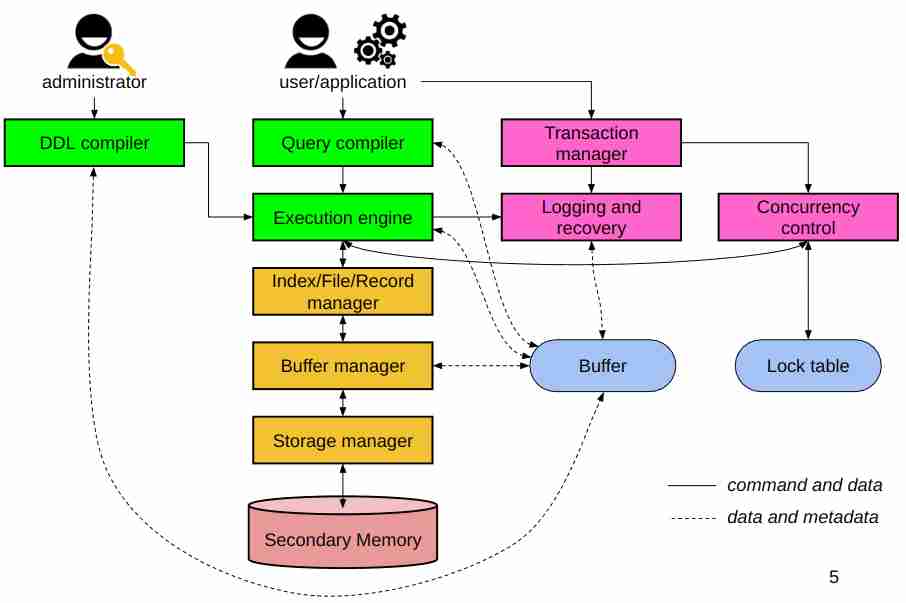
Struttura del DBMS
Introduzione ai DBMS
Schema riassuntivo
 #### Operazioni classiche
Ci stiamo chiedendo, come facciamo a descrivere i processi che portano alla comprensione della query e della retrieval degli elementi utili?
Questo deve fare il DBMS, ossia capace di
- Aggiornare tuple
- Trovare tuple
- Gestire gli accessi
- Gestire accessi concorrenti?
### Query processor
#### Query compiler (3)
- Parsing (crea l'albero di derivazione per la nostra query)
- Pre-processing (fa check semantici sulla query)
- Optimization, si occupa lui di migliorare L'ottimizzazione
#### Execution engine
Esegue l'effettiva computazione per la query, ed è il punto d'incontro col resto (indexes, e logging per dire)
#### Operazioni classiche
Ci stiamo chiedendo, come facciamo a descrivere i processi che portano alla comprensione della query e della retrieval degli elementi utili?
Questo deve fare il DBMS, ossia capace di
- Aggiornare tuple
- Trovare tuple
- Gestire gli accessi
- Gestire accessi concorrenti?
### Query processor
#### Query compiler (3)
- Parsing (crea l'albero di derivazione per la nostra query)
- Pre-processing (fa check semantici sulla query)
- Optimization, si occupa lui di migliorare L'ottimizzazione
#### Execution engine
Esegue l'effettiva computazione per la query, ed è il punto d'incontro col resto (indexes, e logging per dire)
- Esegue il piano di esecuzione che probabilmente un livello superiore ha calcolato
- Interagisce con tutti gli altri componenti del db (ad esempio Log per transazioni e durabilità, buffer e scheduler delle operazioni prolly).
Anche se non so nei dettagli in che modo esegue questo (alla fine roba assembly? che livello di astrazione ha?)
The resource manager
Compiti del resource manager (2)
La cosa principale che fa questo è:
- Sapere dove siano le informazioni di interessa
- Sapere come leggerli e restituirli in fretta
In questo senso gestisce le risorse, perché gestisce le informazioni, in questo caso risorsa principale del nostro db.
Index file record manager
È la parte del database che conosce le strutture delle tables e sa accedere ai dati, ossia contiene le strutture di dati utili per l’accesso a queste tables.
Però non so in che modo è implementato un index, dovresti guardare in Index, B-trees and hashes.
Buffer Manager
Si occupa di memorizzare in modo temporaneo le informazioni necessarie per fare le join e altre operazioni (anche una cache diciamo). ram riservata. Qui sarà presente un nodo più forte e normale tipo! Può essere molto utile per tenere gli indici, per tabelle più frequentemente accedute! Solitamente 100MB di ram qui!, circa 25k nodi di b-tree anche!
Storage Manager
Probabilmente utilizza hash Index, B-trees and hashes per capire quale esatto blocco gli è stato richiesto.
Si occupa di tenere traccia dei blocchi precisi con informazioni nel disco principale (è la parte del sistema che si occupa di restituire il blocco di interesse una volta richiesto la chiave).
Other parts
Transaction Manager
Permette di fare le transazioni.
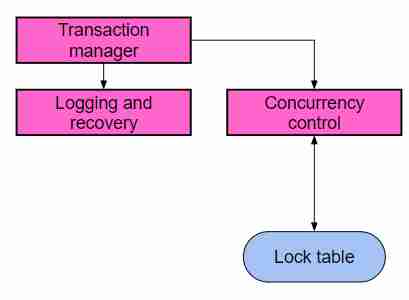
Logging
Come per i filesystem basati su logging, questo è un metodo utile per tenere traccia dei cambiamenti effettivamente fatti o meno. vedere Filesystem. Aiuta a creare l’atomicità e la consistenza necessari per ACID.
Cosa fa: Scrive log in RAM, nel buffer manager, e ci sono protocolli per far sì che questi vengano correttamente salvati sul disco. Nel caso di problemi, comunica col recovery manager in modo che il database torni indietro in stato consistente.
Concurrency control
Questa parte si occupa della isolation in ACID, cerca di fare sì che tutte le operazioni siano eseguite come se fossero isolate uno dall’altra, in questo caso si parla di serializzabilità dell’operazione.
Questa è la parte che ha il controllo sui locks come i Semafori o Monitor per la gestione della concorrenza.
Schedule
Una sequenza di azioni (read, write, commit, abort) da un** insieme di transazioni**
In questo contesto le transazioni sono una cosa primitiva per dire. (esecuzione cronologica).
Serializzazione
Questo schedule si può classificare in completo se prende in esame le operazioni di ogni singola transazione. Seriale se viene eseguita una azione alla volta per ogni transazione (anche se potrei farne di più assieme). Significa che faccio prima tutte le operazioni di una singola transazione, poi della prossima e così via.
Uno schedule è serializzabile, se l’effetto finale è come di uno schedule completo seriale.
Tipologie di anomalie di concorrenza (4)
 Una cosa carina è che questi processi possono essere intesi come errori di Theory of mind secondo me. Si hanno errori quando una serie fa qualcosa, ma l'altro pensa che lo stato sia di un altro genere.
Una cosa carina è che questi processi possono essere intesi come errori di Theory of mind secondo me. Si hanno errori quando una serie fa qualcosa, ma l'altro pensa che lo stato sia di un altro genere.
Più in generale questo problema si può riassumere in phantom anomaly, perché un oggetto viene cambiato nel momento in cui una altra transazione pensa resti la stessa.
Transaction isolation levels
Concurrency control methods (3)
- La prima è la più restrittiva, però ha forti garanzie su serializzabilità basate su locks, praticamente il concetto principale è che una singola risorsa può essere usata da una transazione alla volta (non è totalmente corretto, le read possono essere condivise, ma il concetto resta quello lì), quindi se è concorrente su risorse diverse, non ho problemi
- Optimistic concurrency control in pratica faccio tutto come se non ci fosse niente, e poi faccio.
- Timestamping concurrency control, ad ogni transazione è associata un timestamp e si utilizza questo per decidere chi va prima. Se l’ordine viene violato basta rollback della transazione che lo ha violato.
Join methods
Nested loop join
È l’algoritmo $O(n^{2})$ idiota classico per la comparisons
Single loop join
Viene utilizzato un hash o un tree esterno di una relazione per comparare in fretta e vedere se c’è l’esistenza.
In pratica si chiama single loop perché ciclo solamente sulla struttura esterna
Hash based join
Usiamo double hash!? Non ho capito come. Prendiamo una relazione, quella relazione la salviamo tutta dentro la hash table (con i rispettivi buckets, che siano linked list o rb-trees). Poi prendiamo l’altra relazione, passiamo dalla stessa hash, questa avrà anche lui un bucket, poi su questo bucket ci faccio ricerca lineare per trovare le cose che mi interessano (quindi match su cose piccole). È molto simile a single loop, solo che in questo caso la struttura è necessariamente un hash per dire.
Sort Merge Join
L’algoritmo lineare di sort merge, utile quando si ha un doppio ordinamento per andare a confrontare per benino i due cosi. (this should be the fastest !?!?! solo per dati generali però, but needs ordering).