Introduction to tokenization
Tokenization is the process of converting normal strings into small little pieces that could be fed into one of our models. It usually comes from a tradition in programming languages, as we can see in Automi e Regexp where we define a specific token to have a known pattern, usually recognized by regular expressions.
There have been historically been many approaches to tokenization, let's see a few:
Un approccio semplice (e non funzionante)
Uno dei primi approcci che potrebbe venire in mente per questo problema di divisione delle parole è avere delle componenti fisse (ad esempio lettere di alfabeto, o lettere) e utilizzare queste per fare tokenization.
Cioè stiamo mappando parti delle parole in modo greedy, prima arriva meglio è. Si potrebbe rappresentare in questo modo:
Da questo ipynb
Subword tokenization
A volte conviene dividere una stessa parola in token che siano più piccoli della parola, perché questi potrebbero essere utilizzati in modo ricorrente in suffissi o prefissi (questo ha senso), però abbiamo bisogno di algoritmi che facciano questa tokenizzazione.
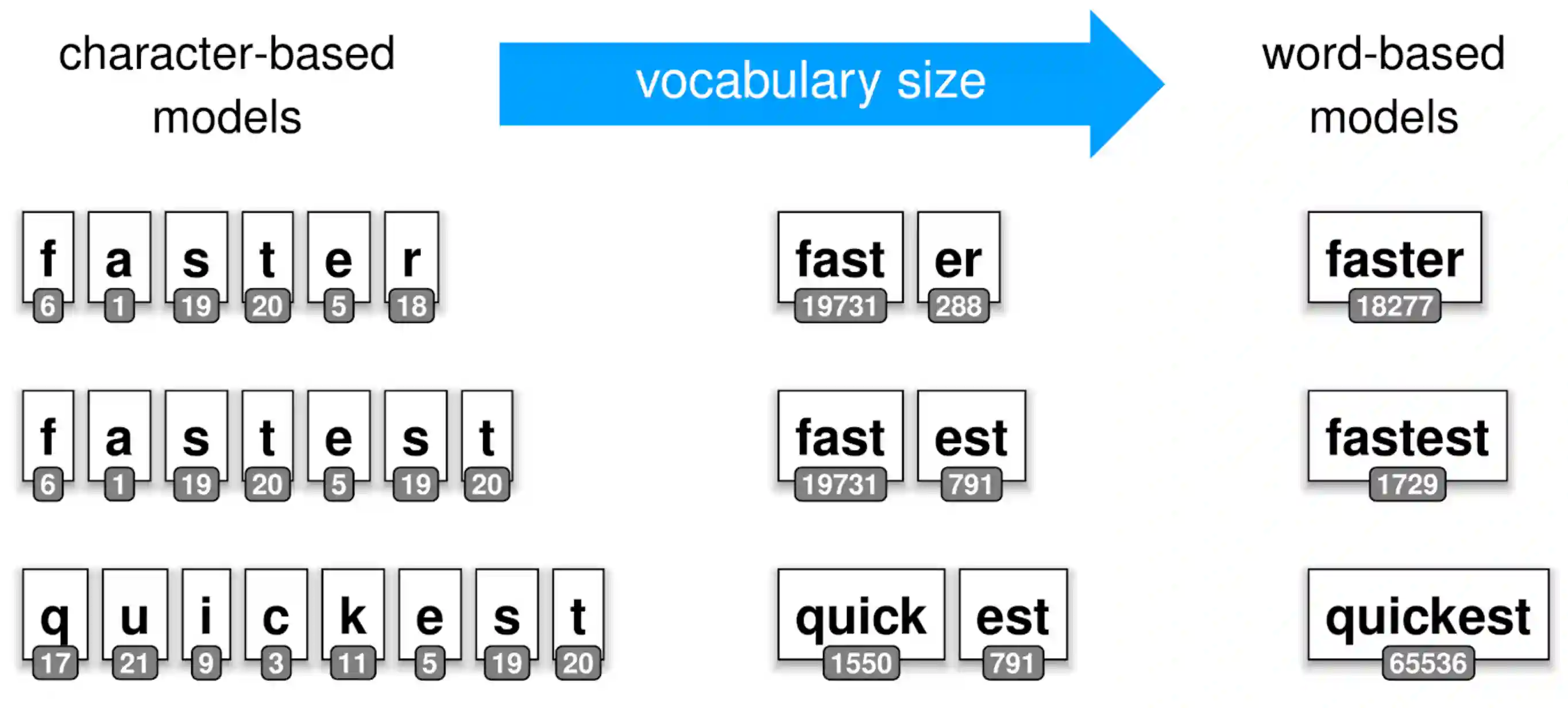
Byte Pair Encoding
Viene tratta per benino in ambito NLU (Sennrich et al. 2016)
Algoritmo in breve
With this approach we use al algorithm similar to this:
Start with each character as a different symbol (create a set)
begin iterate
The most frequent pair of symbols is merged into a single symbol.
end iteration on n done iterations, or when the set is considered small enough
So this is just a small and easy algorithm that we can use to create tokenizations over a single text corpus.
Studio versione in paper
(Credo da (Sennrich et al. 2016)) Un esempio breve in python tratto dal papero stesso:
import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w </w>' : 5, 'l o w e r </w>' : 2,
'n e w e s t </w>':6, 'w i d e s t </w>':3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)
NOTE: defaultdict è solamente un dict normale che ha un default value, in questo caso 0 se non esiste la chiave, e get che ritorna None se non c'è, invece di dare errore.
Versione di GPT
In GPT è stato introdotto l'idea di creare gruppi di cattura che escludessero suffissi diversi, per esempio 's, punteggiature et cetera. Puoi vedere meglio in sezione 2.2 qui (Radford et al. 2019). Esempio del regex pattern Grammatiche Regolari per GPT2 del paper citato:
gp2pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?! \S) |\s+""")
Durante l'allenamento dei GPT sono stati presenti anche tokens speciali come <|endoftext|> tokens speciali per indicare fine documento. Credo sia stata una cosa per facilitare il training effettivo.
https://tiktokenizer.vercel.app/ se vuoi vedere.
References
[1] Sennrich et al. “Neural Machine Translation of Rare Words with Subword Units” arXiv preprint arXiv:1508.07909 2016
[2] Radford et al. “Language Models Are Unsupervised Multitask Learners” 2019