Top-down
Algoritmo di parsing
-
Slide

Questo si potrebbe considerare come algoritmo classico di parsing con non determinismo. (vado avanti, ed esploro tutto, senza look ahead).
-
Esempio di esecuzione

Commenti efficienza di sopra
È molto inefficiente, in particolare si potrebbe trovare una compessità esponenziale del tipo
$O(b^{|w|})$, con b il massimo numero di produzioni. (la produzione maggiore la espando sempre!)
-
Slide

Si può rendere molto più efficiente con un valore di lookahead.
First e Follow
Utilizzeremo il simbolo $ per segnalare la fine di una stringa, così può godere della prefix property, che è una cosa fondamentale per le DPDA, vedi Linguaggi Deterministici e DPDA.
First intro
-
Slide

In pratica è un insieme che contiene i primi caratteri possibili per tutti! (ad ochio attento si può notare quanto sia importante per il lookahead, andiamo in pratica a considerare le produzioni che abbiano il simbolo di lookahead).
-
Esempio di uso e in-uso di first

Calcolo del first
Interessante in questa parte l’utilizzo dell’insieme dei simboli annullabili che abbiamo descritto in Semplificazione grammatiche., sembra sia legata molto al first
-
Slide

L’intuizione di maggior rilievo per questo algoritmo è che in quel modo si sta facendo un or , unione fra tutti i simboli che sono annullabili.
Questo algoritmo si può estendere in modo quasi banale ai non terminali che non sono annullabili (perché basta prendere il primo carattere
-
Slide che descrive per simboli non annullabili

-
Esempi del calcolo del first

Follow intro
-
Slide

Quindi un terminale appartiene a follow terminale se può comparire dopo
Una cosa particolare di questa definizione è il terminale $.
A volte ci può interessare sapere cosa viene dopo un non terminale annullabile così possiamo decidere di annullarlo e tenere il prossimo.
-
Mini esempio

Calcolo del follow
-
Slide algo

Da notare che per calcolare questa funzione abbiamo bisogno del first!
-
Esempio 1

-
Esempio 2

Grammatiche LL(1)
Tabella di parsing intro LL(1)
-
Definizione

Ho una tabella che mappa (NT, T) → produzione.
In pratica una tabella di parsing ci dà una idea del modo in cui comportarci per ogni singolo input e ogni terminale, è quindi fondamentale per capire in che modo espandersi…
Ossia se ho un NT sulla stack e vedo con lookahead 1 un terminale, allora provo a capire con quale produzione posso espandere.
Algoritmo per riempimento tabella
-
Algoritmo calcolo della tabella

Se il first di qualcosa che voglio mettere è noto, allora è easy…
Altrimenti la metto per l’intera riga.
Th sui LL(1) (chiede molto)
-
Definizione di grammatica LL(1)

-
Enunciato e dimo

La dimostrazione di questo è molti dalla costruzione della tabella di parsing. (in particolare l’unici modi che ci importano per dimostrare se un linguaggio è LL(1) è questo oppure la costruzione della tabella d parsing).
-
Esempio grammatica in forma sopra

-
Esempio 2

Parser LL(1) !
-
Slide Algo pseudocodice

L’idea è principalmente di utilizzare la tabella di parsing per capire quale produzione utilizzare quando ho un non terminale!
- Quanto ho terminali li poppo dalla pila (se non posso poppare ritorno errore)
- Quando ho non-terminali vado a guardare nella tabella, se non ho niente fallisco
- Alla fine se ho svuotato la pila e letto tutto sono molto felice.
-
Esempio di parsing 1
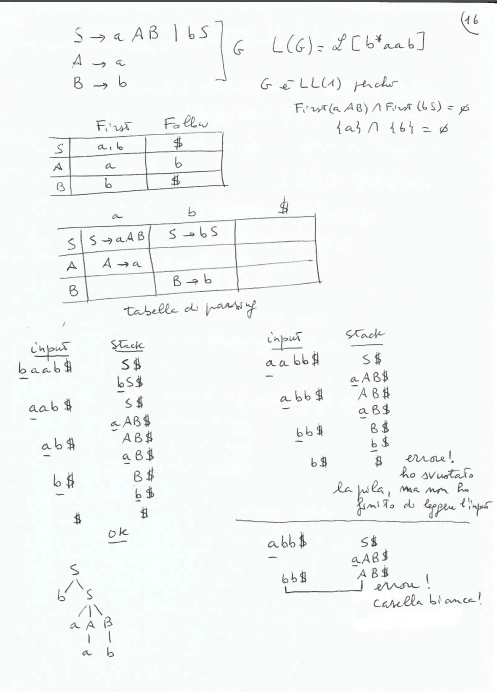
-
Esempio 2

-
esempio 3

Th. ling regolare → generabile da LL(1)
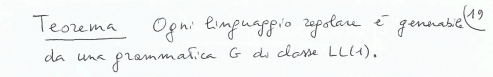
Dalla lezione 14 (credo)
Con i teoremi espressi in Grammatiche Regolari, posso trasformare l’espressione regolare in DFA e poi il dfa minimo in grammatica regolare da questo posso creare la grammatica LL1, vogliamo ora dire che possiamo sempre farlo (nel toggle c’è il piccolo algoritmino utilizzato per creare la grammatica).
-
Dimo

Mini lemma:
Ogni grammatica regolare con solo produzioni $V \implies aW$ e produzioni epsilon è una grammatica LL(1)
Il motivo è che i first di ogni produzione di un non terminale sono diversi fra di loro, perché sono tutti parte dell’alfabeto e sono unici. E i follow sono sempre stringa terminale, quindi per il teorema di caratterizzazione dei linguaggi LL(1), questo è un linguaggio LL(k).
Si può verificare che questo è il tipo di grammatica che si estrae da un automa minimo, quindi il teorema è soddisfatto.
Grammatiche LL(k)
Generalizzazione first follow e tabella
-
Slide

Intuizione
Ora il first ha la concezione dei **primi k **, lettere che possono essere anche minori di k, nel caso in cui io abbia già una stringa terminale. Ma non posso avere minore di K se non è terminale!!!!
Allo stesso modo follow k sono i primi k caratteri che possono seguire il nostro non terminale.
La tabella è generata esattamente nello stesso modo**,* solo che bisogna fare un pò di attenzione alle colonne, che ora possono essere di dimensione molto maggiore rispetto alla dimensione dell’alfabeto (potenze di esse, almeno potenzialmente, poi nella pratica io mi metto a storare quello che mi serve.
-
Esempio di utilizzo di first e follow generali

Teoremi (4) su LL(k)
-
Slide

Questi teoremi ci danno una forte relazione fra
- grammatica ambigua → non è LL(k) con questa anche la sua contronominale
- ricorsiva sinistra → non LL(k)
- essere LL(k) → essere un linguaggio libero deterministico → Non ambigua
- esiste L deterministico tale che non ci sia G di class LL(k) (quindi i linguaggi LL(k) non bastano per avere tutti i linguaggi deterministici!
Gerarchia classi di linguaggi LL(k)
-
Slide

Quello che si può osservare è che ogni classe di linguaggio con k maggiore include quella con k minore. Il motivo intuitivo che non è presente nella slide è tipo: se posso riconoscerlo guardando una lettera più avanti, lo posso ancora fare guardandone 2 o più…
Si può notare che non tutti i linguaggi liberi deterministici sono riconosciuti da linguaggi LL(k), si può osservare l’esempio di sotto.
Libero det not implies LL(k)
-
esempio Incompletezza dei linguagg LL(1)

In questo caso è solamente enunciato che non si può modellare la grammatica così trovata per renderla di classe LL(k).
Però intuitivamente si può capire che avrei bisogni di un k infinito per poter scegliere fra le due produzioni, riesco sempre a trovare un k che non funzioni…
-
Esercizio a caso
