Espressioni, Comandi, Ricorsione
Espressioni
Con espressione intendiamo una entità sintattica, che una volta valutata ritornerà un valore, oppure non termina, in questo caso si dice che la espressione è INDEFINITA.
Questa è una definizione è leggermente ambigua dato che non abbiamo una definizione precisa di valutazoine, che è fortemente dipendente dalla macchina astratta in cui viene eseguito.
Notazioni (sintassi possibili) (3)
Notazione infissa
Questa è la notazione classica matematica, per cose tipo $a -b$, in cui l’operando sta nel mezzo degli operatori.
Abbiamo il vantaggio di famigliarità e semplicità della istruzione, ma perdiamo con ambiguità di precendenza degli operatori e associatività degli operatori, cioè non sempre sappiamo se una espressione ha precedenza con l’altra, per esempio una espressione del tipo x == y and y == 1d in un certo linguaggio and ha una precedenza, e quindi farebbe perdere di senso all’espressione.
Problemi di precedenza abbiamo per cose come $1 - 1 -1$, che a seconda se facciamo prima il primo - o il secondo meno possiamo avere dei risultati differenti.
Quindi se utilizziamo una notazione infissa, guadagniamo di semplicità e famigliarità, e perdiamo in complessità della valutazione, che per essere eseguita vorremmo creare un albero di valutazione, che spesso si deriva dall’albero di derivazione dopo il parser.
Notazione prefissa (polacca)
Sono scritture come questo: $+ \, a\,b$, in qui scriviamo prima il + e poi gli operandi.
È una cosa molto comoda perché non abbiamo la necessità di specificare precedenze né parentesi, ma basta sapere l’arietà del nostro operatore per poter valutare l’espressione.
Notazione postfissa (polacca inversa)
Questa è uguale alla precedente, ma al contrario, quindi abbiamo cose come $a\, b\,+$, è anche più semplice da valutare, ma in generale molto semplice.
Prefissa matematica e di cambridge
come f(a, b), oppure (f a b) per cambridge
Interpretazione dell’albero
Si potrebbe interpretare la notazione infissa, prefissa o postfissa come una visita dell’albero di valutazione.
- simmetrica = visita infissa
- prefissa = visita prefissa (anticipata) (provo a valutare l’operatore e poi vado giù)
- Postfissa = visita postfissa (valuta dopo aver eseguito sinistra e destra)
Semantica
Con la semantica andiamo ad indicare il processo di valutazione di una espressione. Abbiamo detto prima che per la notazione infissa è più complicata, infatti dovremmo andare a creare un albero di valutazione, creato dall’albero di derivazione (che quando compiliamo col parser è facile da creare dalle foglie).
Invece se proviamo a valutare con la notazione prefissa, questa è una cosa molto più semplice, perché basta una singola scansione che va con questo algoritmo:
- Se è un operatore inizializzo un counter e torno a leggere
- Se vedo un operando pusho in pila e decremento il counter.
- Se counter è 0 faccio l’operazione e metto in stack, se è diverso da 0 torno a leggere
Se è postfissa allora è ancora più semplice, se ho un operando pusho in pila, se ho un operatore prelevo quanto mi serve ed eseguo e pusho in pila il risultato.
Ordine di valutazione delle sottoespressioni (4)
Matematicamente parlando non sarebbe molto importante andare a considerare l’ordine di valutazione, però in questo caso diventa molto importante perché l’ordine stesso potrebbe incidere sul risultato dell’espressione, un esempio è quando una espressione implica un side effect.
-
Side effect (come potrebbe essere la chiamata di una funzione con side effect mentre valutiamo l’espressione!)
-
Possibilità di overfow per aritmetica finita eg.
(INT_MAX - 10 + 5)vs(INT_MAX + 5 - 10) -
Corto circuito e operatori non definiti.
- Per esempio una scrittura del tipo
(p ≠ NULL) && (p.next == 1)sarebbe un errore in pascal, perché fa una esecuzione eager, cioè valuta tutto prima di valutare qualcosa, mentre in C se è null torno subito, questo si dice corto circuito perché non vado a valutare tutto.
- Per esempio una scrittura del tipo
-
Efficienza, l’ordine di valutazione può anche cambiare l’efficienza dell’esecuzione, ad esempio inizializzando un accesso in memoria, e poi andare a fare altre operazioni che non avevano bisogno di accesso. Perché nell’esempio di sotto è probabile che aa non sia ancora disponibile, quindi conveniva fare cd prima di andare sull’altro, che deve attendere.
- Esempio
a= vettore[i]; b = a*a + c*d
In questa sede quindi è importante fare differenza fra
Comandi
Definizione di comandi
Per comando intendiamo una entità sintattica che quando valutata non necessariamente ritorna un valore, inoltre potrebbe fare un effetto collaterale. (NOTA: anche le espressioni possono avere effetto collaterale)
Da questa definizione non sembra ci sia una differenza chiara con l’espressione. però concettualmente dovremmo tenerci in mente che un comando è qualcosa di utile per cambiare lo stato del programma, ossia alla fine del comando ho uno stato differente, quindi ho avuto un side effect, mentre una espressione è qualcosa che idealmente non dovrebbe avere side-effect, ma alla fine ritorna sempre un valore.
Un esempio di side-effect del comando può essere la stampa a schermo, che avrò cambiato la zona memory mapped come descritto in Note sull’architettura.
Stato computazione = valore di tutte le variabili nel programma in un certo momento (oppure memoria, boh), va a modificare questo l´effetto collaterale.
Variabili (2)
È importante tenere a mente che le variabili sono diverse rispetto a quelle definite in matematica, lì sono incognite che possono assumere valori in un certo insieme che non sono modificabili.
Invece in informatica per le variabili abbiamo due modi principale di interpretazione, una reference model e l’altra come variabili modificabili
Il primo modo intende la variabile come una reference a una zona di memoria in cui veramente è presente il dato che ho, quindi come se fosse un puntatore (senza possibilità di modifica) (solitamente messo nella heap). Quindi la variabile denota il riferimento, alla variabile, non il contenitore al valore.
Il secondo modo intende le variabili proprio per il valore che possiedono, quindi come contenitore o locazione di memoria che contiene qualcosa che può cambiare nel tempo. Sembra molto simile, ma nel secondo modo vado a riferirmi al valore, che è proprio in quella zona, mentre nel primo caso è un puntatore ad una altra zona.
Altri modelli
-
Slide altri modelli di variabile

Nei linguaggi funzionali, come le variabili matematiche, che una volta assegnata non è più modificabile un valore. O modificabili in un certo senso nei linguaggi logici.
Assegnamento
Solitamente l’assegnamento ha una forma exp1 assignmentOp exp2a ed è importante andare a distinguere l-value e r-value.
l-value è l’indirizzo di memoria (quindi denota una locazione) in cui si dovrà andare a scrivere la r-value, che solitamente può essere la locazione se utilizzo la reference model (e quindi in pratica sposto il pointer in questo modello), o proprio una copia del valore se utilizzo l’altra interpretazione, quella delle variabili modificabili, in questo caso indica (un valore che può essere contenuto)
Solitamente questa istruzione produce un side effect (quindi si può notare che il side effect sia un necessario), dato che il valore della variabile è stato modificato, e solitamente non ritiorna nessun valore (tranne in C che ritorna sempre una variabile, perché credo che l’assegnamento è visto come se fosse una espressione).
IMPLICAZIONI IMPORTANTI PER SIDE EFFECT.
È importante tenere a mente la possibilità di side effect, perché se provo a fare una cosa come a[f(x)] = a[f(x)] + 1 Questo potrebbe dare risultati differenti a seconda del fatto che io abbia side effect o meno. Sarebbe meglio fare cose come j = f(x); a[j] = a[j] + 1
Gli operatori come += e quelli della stessa famiglia sono utili a ovviare a questo side effect dovuto all’esempio di prima, ecco una loro utilità 😀, non è solo un modo compatto lel.
Controllo della sequenza
Ambiente e memoria (3) (ni)
-
Slide ambiente e memoria

Solitamente una associazione del tipo f: nome -> Valore Non è sufficiente perché non posso esprimere che un assegnamento per reference cambi i valori per entrambi (secondo questo modello dovrebbe cambiarlo solo per il singolo nome!).
Solitamente andiamo a definire 3 modelli di valore:
- Valori denotabili da variabili
- Valori memorizzabili in locazioni di memoria
- Valori esprimibili come risultati di espressione.
All’interno del nostro linguaggio imperativo imperativo abbiamo bisogno delle prime due, mentre in un linugaggio funzionale solamente il primo che associa valori a variabili.
Infatti per utilizzare l-value vogliamo andare a modificare il valore associato alla variabile. mentre per accedere al r-value dobbiamo andare a prendere il contenitore, quindi dovremmo prima accedere alla locazione, e poi dalla locazione andare a riprenderci il valore.
Poi il fatto che la l-value cambi anche il valore in memoria è una altra cosa credo… Non lo ho capito dovrei chiederlo. Questa parte non ha molto senso, e non è importante posso saltare però tenere a mente che esistono quelle 3 cose.
Comandi sequenziali
Sono comandi come
;Ossia il singolo comando sequenzialibegin ... endChe sono i comandi a blocchi anche indicati con{}in CgotoChe è ora in disuso ma in passato era molto importante.
Il goto ha avuto una fortissima discussione negli anni 1970 con Dijkstra. Si basava sull’idea di assembly e labels che permettevano di fare salti a piacere.
- Il goto ha la stessa espressività di un programma senza di esso (th di Böhn Jacopini)
- Il goto rende il codice difficilmente leggibile, quindi non permette la facile manutenzione. (si pensi a un goto per uscire da un loop 100 righe dopo, non è più strutturata la lettura diciamo).
- Come posso interpretare il fatto di goto che salta all’interno di un blocco? Come gestire RdA??
- Sarebbe buono utilizzarlo come break e continue, ma ci sono già quei comandi…
- Produce spaghetti code (che crea proprio un grafo a forma di spaghetti se seguiamo il flusso di controllo del programma)
- Viola il concetto della programmazione strutturata, di cui tratteremo in software engineering l’anno prossimo.
-
Slides programmazione strutturata

Condizionali (2)
if Bexp then Cl e1se C2 Semmai potremmo dire che ci siano qualche ambiguità quando ho qualche if annidato senza delimitatori. Per la valutazione di questi if è importante tenere a mente che esiste il short-circuit per rendere più efficiente la cosa.
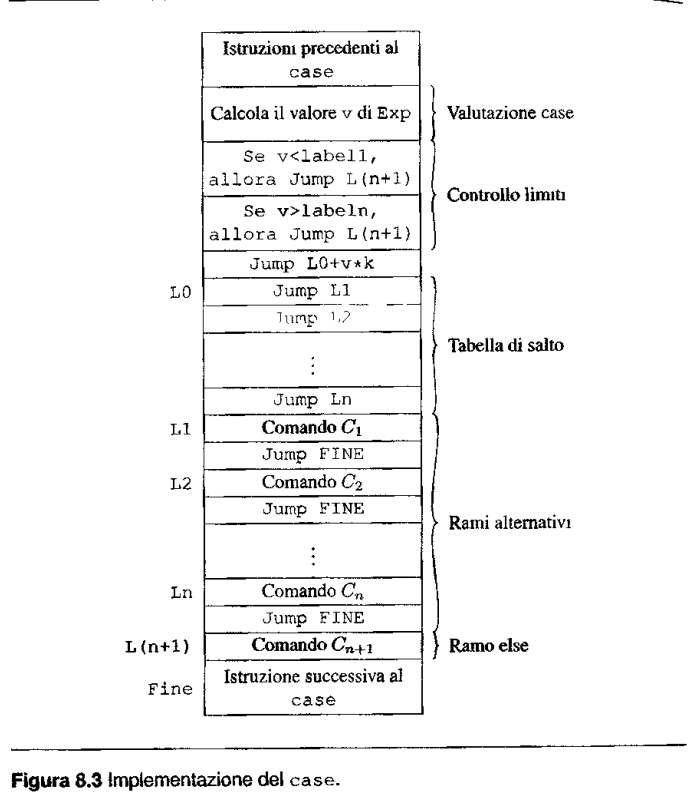
Case la cosa bella è che ho un jumping table, quindi rende tutte le operazioni di controllo e salto leggermente più efficienti.
- Velocità per la jumping table (faccio solo 2 salti, invece in if-then else è lineare nel numero di if annidati).
- Chiarezza del costrutto.
-
Slide case

-
Esempio di Jumping table
Iterativi (2)
I comandi iterativi sono necessari per la turing completezza del linguaggio
Iterazione indeterminata
Sono comandi come while o repeat ... until oppure il do while. Ed è indeterminata perché prima dell’esecuzione non so esattamente quante iterazioni andrò a fare. dal punto della macchina fisica è molto facile implementarlo, dato che basta un salto con un check, più facile da implementare di un for.
Con, if, ass, while ho già un linguaggio turning completo! Esattamente come è descritto in Fondamenti teorica.
Iterazione determinata
Queste sono tutte le iterazioni in cui conosciamo a priori il numero di iterazioni da compiere (a runtime, prima di cominciare l’esecuzione del comando), per esempio for e foreach . Di solito credo che nell’implementazione si può calcolare il numero di iterazioni
Si può osservare che la iterazione determinata sia meno espressiva dell’iterazione indeterminata, però da un punto di vista pragmatico è molto utile perché mi compatta tutta la struttura che esisteva per l’iterazione indeterminata.
Meno espressiva perché non posso computare programmi come
$$ f(x) = \begin{cases} x \text{ se è pari} \\ \uparrow \text{ altrimenti }\end{cases} $$Se ho iterazione determinata non riesco a divergere.
for {exp1; expz; exp3) comando è la sintassi di C, ma nota che qui non è determinata! perché posso modificare il valore dell’indice e anche del controllo, quindi in pratica è equivalente all’iterazione determinata (posso renderlo indeterminato modificando l’indice all’interno).
NOTE DI IMPLEMENTAZIONE
È importante capire che in questo caso esiste il vincolo di semantica statica, che il fine e il valore del passo non dovrebbero essere modificati (cosa che non vale in C, per questo non è il for settato bene).
Come fare ad implementare il passo? Se è negativo? Proco a costruire il concetto di iteration counter definito come segue:
$$ ic = \lfloor \dfrac{fine - inizio + passo}{passo}\rfloor $$+passo perché il fine è incluso nella iterazione, per questo aggiungo 1.
Ricorsione
Definizioni induttive
Una cosa cosa molto interessante è che se possediamo una funzione da $g: \N \times A \to A$, e abbiamo una funzione $f: \N \to A$, e un qualunque valore $a \in A$, allora posto
$$ f(0) = a \\ f(n + 1) = g(n, f(n)) $$f è univocamente determinata per tutti i valori del dominio. Basta che g sia una funzione totale.
Credo che questa definizione della funzione f, sfrutti la struttura dei numeri naturali (la stessa struttura su cui si basa il principio di induzione). Studieremo queste definizioni in maggior dettaglio in informatica teorica.
In modo simile una funzione ricorsiva è simile a questa, è definita in termini di funzioni precedenti già definite. Nonostante ciò ci possono essere dei casi in cui è calcolabile, ma si discosta un pò dalle definizioni matematiche.
-
Casi in cui ciò si discosta

Si può dimostrare, cosa che non facciamo in questa sede che ricorsione è equivalente alla iterazione. Nonostante ciò in alcune implementazioni, in particolare l’implementazione standard della ricorsione, questo porti a forti inefficienze. Analizzeremo solamente la tail recursion come ottimizzazione possibile.
Tail recursion
Una chiamata di g in f di si dice “chiamata in coda” (o tail call) se f restituisce il valore restituito da g senza ulteriore computazione.
Quando faccio una chiamata ricorsiva alla fine, prima di ritornare dalla funzione, allora posso ottimizzare tutto il discorso che abbiamo fatto sugli RdA in Nomi e Scope, perché non avrei bisogno di allocare un nuovo RdA, mi basta lo spazio attuale!
È una cosa molto particolare perché con questo riesco a implementare la ricorsione con memoria statica! Un singolo RdA.
Tail recursion si ha quando l’ultima istruzione di ritorno non possiede computazioni aggiuntive, avendo questa proprietà, la chiamata della funzione può essere posta in modo che sovrascriva tutti i parametri, le variabili locali, con l’indirizzo di ritorno e il valore di ritorno le stesse della funzione chaiamante.
In pratica invece di far crescere continuamente la stack, posso fare in modo di utilizzare lo stesso record scrivendoci i nuovi parametri, un risparmio di memoria non da niente!