1 Calcolo dei numeri finiti
Il calcolo è numerico perché si differenzia rispetto a un calcolo normale perché è finito.
1.1 Errore nei calcoli
1.1.1 Tipologie di errore (5)
- Errore di misura, dovuto alle imperfezioni dello strumento di misura dei dati del problema.
- Errore di troncamento, quando un procedimento infinito viene realizzato come procedimento finito. (esempio: calcolo del valore di una funzione tramite sviluppo in serie, perché dato che l’algoritmo deve essere finito, devo prima o poi interrompere il calcolo, ecco qui l’errore).
- Errore inerente, dovuto al fatto che i dati di un problema non sono in una forma buona diciamo
- Errore di rappresentazione (simil troncamento) non sempre appartengono all’insieme dei numeri rappresentabili e quindi vengono approssimati.
- Errore algoritmico, dovuto al propagarsi degli errori di arrotondamento sulle singole operazioni in un procedimento complesso.
1.1.2 Misura dell’accuratezza
Anche per l’accuratezza di una misura utilizziamo degli errori (questi tipi di errori li hai anche studiati in fisica durante il liceo).
- Errore assoluto di solito ha poco valore perché dipende dal contesto, molto più importante il relativo
- Errore relativo questo molto buono, ed è in pratica simile all’errore percentuale Questo errore mi riesce effettivamente a dare un concetto di precisione del calcolo.
- Errore percentuale in pratica è l’errore percentuale
1.2 Rappresentazione dei numeri
Gli argomenti presentati in questa sezione sono già stati trattati in modo anche pratico nel corso di Architettura degli elaboratori in Rappresentazione delle informazioni, qui andremo ad approfondire di più da un punto di vista matematico.
1.2.1 Numeri interi
Questa parte è totalmente omessa perché presente in Rappresentazione delle informazioni
La stessa parte, sempre presente lì, tratta dell’algoritmo di conversione dei numeri interi in binario e decimale
1.2.2 Numeri reali
-
Slide per la rappresentazioni.

La prima cifra deve essere diversa da 0 per garantire unicità al numero.
Esercizio: ricava la formula che rappresenta ogni numero reale in una base qualunque.
1.3 Sistema floating point
1.3.1 Rappresentazione matematica dell’insieme
-
Slide

l’insieme
descrive tutti i numeri nella retta reale che sono rappresentabili secondo il sistema floating point
Questo insieme è finito, non continuo.
1.3.2 Rappresentazione del numero nel calcolatore
Se il numero che vogliamo rappresentare è nell’insieme, allora è facile, prendiamo quel numero Altrimenti si utilizza un troncamento o arrotondamento della mantissa al numero di più adatto, vediamo come agiscono questi due metodi. Notiamo che questo caso succede quando .
Troncamento rappresento tutto il numero fino a e poi ignoro il resto. Un altro modo per vedere il troncamento è che arrotonda sempre al ribasso, mai dopo, prende il numero di più vicino e minore del numero che vogliamo convertire.
Arrotondamento simile al troncamento, ma arrotonda. Che si conosca non c’è un coso hardware che lo faccia (o comunque implementa questo algo:https://stackoverflow.com/questions/4572556/concise-way-to-implement-round-in-c)
1.3.3 Breve discussione sui parametri
, descrive la base di rappresentazione del nostro insieme , descrive il numero di cifre utilizzate per la rappresentazione, principalmente influiscono sulla precisione (densità dei numeri nell’intervallo, vedi sezione sequente). descrive il upper bound per la caratteristica (esponente alla base) uguale a ma è un lower bound.
Quindi descrivono il range di rappresetnazione per il nostro insieme di rappresentazione
1.3.4 Densità dei numeri
-
Slide

Si può notare che col metodo di rappresentazione esposto sopra si possono individuare informazioni sulla dispersione dei numeri nella retta.
In ogni intervallo di lunghezza ho numeri, distanziati in maniera uguale una dall’altra (solo in questo intervallo), appena salgo di intervallo, l’intervallo cresce. Questo è anch eun motivo dell’underflow, in cui quando sono troppo vicino allo zero, l’intervallo è troppo piccolo. (credo, è da rivedere questa cosa).
Il motivo di questi numeri è perché ho numero di modi per scegliere il primo numero (che deve essere diverso da nullo) e il restanti cifre della mantissa come li voglio
1.3.5 Standard IEEE
-
Slide descrizione dei floating points per lo standard IEEE
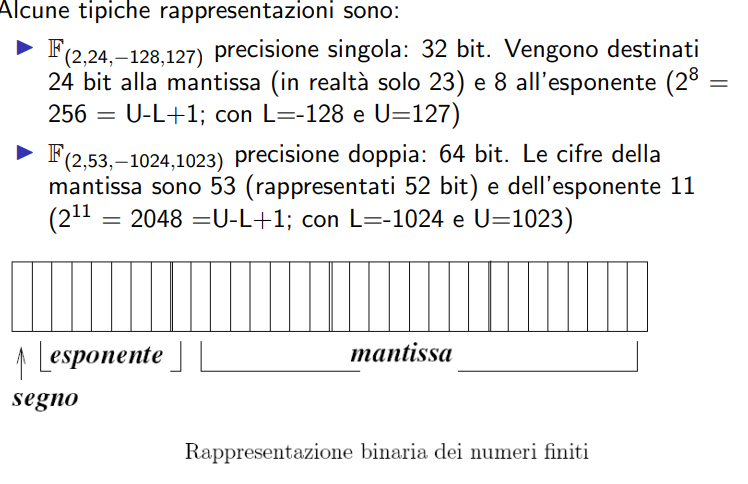
In più sono riservati alcuni numeri per . e NaN (esempio quando faccio 0 * inf ho un NaN)
Nota questi valori non sono codificabili nella forma che è presente in slide, però lei li vuole così quindi impara a memoria per l'esame saddo.
1.3.6 Errore di rappresentazione ed errore di macchina

Con double , con float
-
Definizione simile di epsilon, ma nell’altro verso

TODO: chiedere se le due definizioni sono equivalenti pg 50 pdf introduzione al calcolo numerico
eps è il più piccolo numero macchina positivo tale che , in pratica è il più piccolo numero che è arrotondato al più piccolo numero rappresentabile da .
Per il calcolo dell’eps per il valore dell’errore macchina ti puoi rifare a questo post machine epsilon value for IEEE double precision standard alternative proof using relative error
La prof ha sbagliato in questa parte, ha copiato il valore di epsilon per l’arrotondamento con normalizzazione che parte da 1, quindi il valore corretto di epsilon dovrebbe essere . Anche la pagina di wiki spiega bene questa parte di dimostrazione dell’errore macchina
1.4 Aritmetica floating point
1.4.1 Definizione di funzione
è una funzione , ma può succedere che una operazione che prende due operandi da F e F non sia ancora in F, e quindi c'è bisogno di arrotondarlo ad F, causando un errore di
Il valore è sempre minore perché epsilon è il maggior errore possibile per singola operazione
Propagazione dell’errore
Il processo di propagazioen dell’errore è molto difficile da tenere in considerazione, quindi ci limitiamo a considerare alcuni casi tipici di errori inerenti nell’operazione di somma e sottrazione:
NOTA: per questa parte è definito come il più grande numero tale che , che è quasi equivalente all'altro.
- Somma di due numeri con esponente molto differente, perché finisce che il computer non ha abbastanza bit in mantissa per rappresentare il risultato, e quindi deve andarea troncare. Questo incide principalemente su bit di poco significanza. , così abbiamo perso
- Differenza fra numeri molto simili, questo incide su bit di grande signfiicanza: Esempio: ( abbiamo perso , ma questo è un errore relativo direi più grosso, credo.
Importanti sono l’esempio presente nelle slides epr il calcolo del numero di nepero