Bounds
Markov Bound
Questo bound è abbastanza banale se fatto da un punto di vista grafico, comunque afferma che
Il motivo è che (assumendo che sia una variabile aleatoria non negativa)
Il che finisce la dimostrazione.
Chebychev Bound
Questa è una conseguenza abbastanza diretta sul bound precedente: Afferma che
E in pratica dice che all'infinito viene tutto compattata sul valore atteso La dimostrazione è abbastanza semplice, si sostituisce su di Markov e a e poi si dovrebbe già avere il risultato
Chernoff Bound
Asserisce che
Moments of random variable
https://en.wikipedia.org/wiki/Moment-generating_function Per capire il significato di questo bound invece, è necessario prima capire cosa sia un moment generating function. È una funzione generale che crea i momenti di una variabile aleatoria. Un momento per una variabile aleatoria è descrivibile come n-esimo momento: La funzione generatrice dei momenti è describile come:
Il motivo per cui vale, è che con l'espansione di taylor, vedi Hopital, Taylor, Peano Possiamo estrarre in modo abbastanza semplice i momenti: Infatti:
Quindi per esempio se volessimo il primo momento, prendiamo la derivata rispetto a e settiamo , perché la cosa molto bella è che i coefficienti si cancellano tutti, e l'unico termine che rimane senza è il momento cercato, per questo motivo estraiamo easy i momenti.
Dimostrazione Chernoff's Bound
Anche questa è una conseguenza abbastanza immediata di Markov, viene affermato che
Guardandolo dall'altro in basso non ho idea del perché valga.
La dimostrazione avviene così
Dove è qualunque perché per quello la funzione resta crescente, e quindi la dimostrazione vale ancora. La cosa interessante di questo bound è che la probabilità che succeda scende in modo esponenziale.
Hoeffding's Inequality
Anche conosciuto come Chernoff or Okamoto Bound. L'enunciato è che se considero la somma delle classiche variabili aleatorie con stessa media varianza allora vale che, tale per cui con probabilità vale che . Ricorda che
Questo ci dice quanto velocemente la media converge nel valore atteso che ci aspettiamo per la legge dei grandi numeri.
Simpler form
Se supponiamo che siano tutte in allora possiamo scrivere la relazione in forma più elegante come
Ci permette di avere un bound su accuratezza in funzione del numero di samples che andiamo a prendere.
La dimostrazione di questo mi sembra abbastanza tecnica, c'è bisogno di guardare https://web.eecs.umich.edu/~cscott/past_courses/eecs598w14/notes/03_hoeffding.pdf Oppure https://cs229.stanford.edu/extra-notes/hoeffding.pdf.
Non ho bene capito l'utilità se non nel caso Bernoulliano in cui sembra si semplifichi abbastanza questo.
This inequality has been proven quite useful. See Provably Approximately Correct Learning, Tabular Reinforcement Learning.
Hoeffding's Lemma
Proof of Hoeffding's Inequality
TODO.
Law of Large numbers
Weak Law
La dimostrazione di questo è molto semplice, basta avere Chebicheff
Questa è l'intuizione di quanto presente nell WLLN
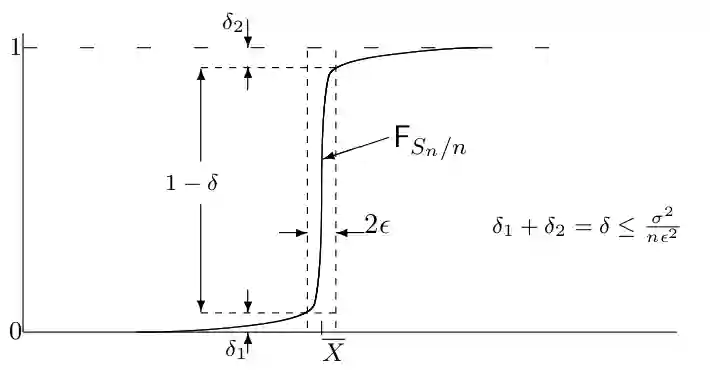
Abbiamo mean square convergence.
Abbiamo che vale:
E poi settando si può avere il risultato. Nella forma corretta. Vedere capitolo 1.5 in questo.
Si può scrivere:
In questo senso possiamo dire che la successione arriverà sempre alla media.
Ricordiamo che . Dove tutte le variabili sono IID con media e varianza .
Weak law without finite variance
Potremo scrivere
Teorema 1.5.3 nelle note. Questa è la convergenza in probabilità della serie di variabili aleatorie. Con strumenti più avanzati è possibile dimostrare anche la convergenza con probabilità 1 anche in casi di varianza infinita. Questa è l'unica differenza con la versione Strong della legge dei grandi numeri.
Convergence types
We need a lot of care when defining the notions of convergence for probability distributions because the same ideas that applied to the real numbers do not apply here anymore. For example, in calculus if we have a sequence such that for a certain it's clear that , by that definition. The same does not apply if we take a sequence of normally distributed random values , this does not converge to the distribution in the classical sense, because we can't directly compare them. For instance because both are continuous random variables, and the probability of it is always zero for the integral has zero length. This is why it's important to distinguish various types of convergence in probability.
Convergence in distribution
Una sequenza di variabili aleatorie converge in distribuzione se vale
Per ogni in cui è continua. Una sequenza di distribuzioni che converge a una distribuzione. Un esempio in cui questo vale è il central limit theorem in cui definiamo
Converge alla normale, 0, 1 gaussiana. Un altro esempio è la weak law of large numbers, in cui converge a .
Convergence in probability
Given the sequence of random variables , this converges in probability to if the following holds:
So we care about the value of the single probability. Vale anche qui l'esempio della WLLN.
Convergence in mean square
Una sequenza di converge in mean square a se vale
La nota è che Mean Square -> Convergence probability -> Convergence in distribution. This is usually useful just to prove the convergence in probability.
Convergence almost everywhere
(Il prof. lo chiama with probability 1 e secondo lui serve sapere measure theory per poter comprendere la definizione originale).
Definiamo una sequenza e il suo spazio campionatorio e sia una altra variabile aleatoria, allora la sequenza converge con probabilità 1 se vale
Ossia, per definizione di variabile aleatoria è un valore reale, queste sequenze di numeri reali a volte convergono, se convergono vogliamo che il valore sia esattamente . Quello che vogliamo dire con questo è che la probabilità degli elementi dello spazio campionatorio che creano sequenze che convergono è uguale a 1.
Central Limit Theorem
By Lindeberg-Lévy. It is possible to estimate the distribution of the average of the random variable.
The Bernoulli Case
The theorem
Ossia che la sequenza di variabili aleatorie
Convergerà alla gaussiana normale. È un motivo per cui è una distribuzione molto importante.
Si può anche scrivere con convergenza in distribuzione:
La cosa importante da ricordare è che per distribuzioni con varianza finita avremo una distribuzione normale con varianza zero e concentrata sulla media, mentre per distribuzioni con varianza infinita avremo una distribuzione anche lì con heavy-tail (che è il motivo per cui ha varianza infinita), il che significa che avremo una altra distribuzione con varianza infinita.