We have resources, but need to know how to assign these to the jobs that need them. This note presents some of the most common resource management policies for cloud clusters.
Introduction to cluster management
How can we allocate the resources in a cluster in an efficient manner? How can we allocate resources fairly?
Two step allocations
There are two main kinds of allocation: first you need to allocate resources to a process, then allocate the process physically in the cluster. We have seen an example of a working infrastructure in Cluster Resource Management.
Private and public cluster management
Cluster management could be private or public.
- Private: means every app is managing their own sub-cluster: each app receives a private, static set of resources. Here it is easier to manage hardware for various needs.
- We have easy performance isolation
- Simple to manage: each application decides how to use their dedicated hardware.
- Often not optimal -> Low resource utilization.
- Today this is mostly used for user-facing scale-out workloads (like web servers, etc.)
- Public means there is a big cluster, like standard third party, most of the services we mentioned in Cloud Computing Services are ran in public clusters. - Performance isolation is difficult to achieve. - Resource utilization is higher: resources are shared among multiple applications. - Resource management is more complex: need to manage the resources of the entire cluster.
Desiderata for Cluster Management
- Fairness
- Users should be granted resources proportional to how much they are paying • Flexibility to express priorities
- Efficient resource usage
- Work conservation: Resources should not idle while there are users whose demand is not fully satisfied
- Performance isolation
- Guarantee that misbehaved collocated applications cannot affect me “too much”
- Experience says this is very hard to achieve, especially in public clusters, and with virtual CPUs. You need to have the whole machine to be able to get more performance isolation.
Classical resources are:
- CPU allocation
- Memory allocation
- Network allocation
- Memory bandwidth allocation and similars.
Theoretical properties for Schedulers
This section shortly lists some common properties for schedulers in theoretical analysis.
Envy-Freeness Schedulers An envy-freeness scheduler is a scheduler that does not allow users to envy each other. This means that no user prefers another user’s allocation over their own. DRF is an example of Envy-free scheduler.
Strategy-Proof Schedulers A strategy-proof scheduler is a scheduler that does not allow users to gain an advantage by lying about their demands. This property allows to avoid users trying to game the system by requesting more resources than they actually need. For example, DRF explained later is not strategy-proof. While Max-Min scheduling is.
Work Conserving Schedulers A work conserving scheduler is a scheduler that does not leave idle resources when there are users with unsatisfied demands. It is a very important property, because it allows to maximize the resource utilization.
Max-Min Scheduling
The method
The algorithm is quite easy:
- Allocate resources in order of increasing demand
- No user gets a resource share larger than its demand
- Users with unsatisfied demands get an equal share of the resource (remember you need to weight this! so if one user has double weight, it gets double of remaining shares)
The problem is when you have different kinds of resources to share. Another problem is that it is not always predictable to know how many tokens are you getting, this is mostly dependent by what others require. It is easy to extend this allocation method to a weighted version.
 #### Fairness Considerations
One can prove that this algorithm is fair:
- Each user gets at least $1 / n$ of the resource, that is their **fair share**. If you demand less, you will get less, getting more is not guaranteed, it depends on the other requests.
- Nobody gets more than what it demands
- When a user's request is not fully satisfied, the user gets an equal share of the remaining resources
- It is possible to extend with with priorities.
- It is **strategy proof**: users are not better off if they lie about their demands.
- For example a scheduler that assigns resources based on CPU utilization alone is not strategy-proof: applications could fake their usages to get more resources.
#### Fairness Considerations
One can prove that this algorithm is fair:
- Each user gets at least $1 / n$ of the resource, that is their **fair share**. If you demand less, you will get less, getting more is not guaranteed, it depends on the other requests.
- Nobody gets more than what it demands
- When a user's request is not fully satisfied, the user gets an equal share of the remaining resources
- It is possible to extend with with priorities.
- It is **strategy proof**: users are not better off if they lie about their demands.
- For example a scheduler that assigns resources based on CPU utilization alone is not strategy-proof: applications could fake their usages to get more resources.
This kind of scheduling is very good, but only if you have a single resource, if you have more disaggregated resource types, then it becomes a little more difficult.
Weighted fair scheduling
In the weighted fair scheduling, you assign a weight to each user, and then allocate resources proportionally to the weight. It is a little different from weighted max-min fairness. It’s a good thing to do exercises to understand this weighted version of the algorithm.
Dominant Resource Fairness
This resource assignment algorithm has been introduced in (Ghodsi et al.). It is not strategy proof: some programs can make seem their dominant resource is another so that they get higher shares.
The Idea
The idea is quite simple: consider the dominant resource usage by each user. Then allocate the containers in a manner that is constant with respect to max resource usage ratio / number of containers.
For example, if Alice is using 6% of the available CPU, and Bob 3% of the available RAM, then bob should have twice as the number of containers compared to Alice.
Worked out Example
Suppose you have 9 CPU and 18 GB.
- Alice wants to issue processes 1 CPU and 4 GB
- Bob demands to issue processes with 3CPU and 1GB.
You want to equalize the share of the dominant resources with same constraints.
 Solving these equations we have that $x = 3$ and $y = 2$. And we can do this for many many other kinds of tasks.
Solving these equations we have that $x = 3$ and $y = 2$. And we can do this for many many other kinds of tasks.
Online DRF

Algorithm pseudocode from the paper
Token Bucket
- Has a size (number of tokens in the bucket)
- The fill rate, how quickly it is filled up. Commonly used for controlling network and storage traffic. Basically the buckets are filled up at a constant rate, and spent when the transmission is needed. The downside is that if you don’t need to spend the tokens, then this values is capped
Resource Assignment
The algorithm is easy: filter for hard constraints and order for soft constraints, this is what Kubernetes does with node affinities, you can set hard and soft constraints. Users usually do not know what their application needs. Often users tend to ask more than they need, this is called over-provisioning.
- Filter: machines that satisfy hard constraints.
- Sort: machines that satisfy soft constraints, to get the best fit machine.
Problem of low resource usage
From the point of view of the provider this is not optimal since we will have a low resource utilization:
- Hard consumption and costs.
- Most of the users request more resources than they actually need. This problem has improved (Google Borg (2020 study) cluster manager has around 50% utilization by allocating to almost double CPU!).
Quasar Paper
This section will be wholly based on (Delimitrou & Kozyrakis 2014) (Using ML to make decisions was a new thing at the time).
Performance Goal assignments
We want to allocate resources based on performance goals, not predicted resource usages.
- For each new application, we need to recommend a resource allocation and assignment
- We need to base this reccomendation based on previous needs of similar applications.
- It does collaborative filtering to decide the resource allocation, and adjust it dynamically.
The idea is to use the data from previously run applications and newly run ones to get some data about QoS compliance and resource usage.
Understanding Performance and Resource Trade-offs
The idea is to combine information from past similar jobs from before and profiling information. We want to be able to answer questions like: how does the new job relate to past jobs? Doing some short profiling to understand the actual resource usage to some past processes.
- Small signal: refers to the short-term performance feedback obtained from running the process in a sandboxed environment to get information about resource usage and performance, and understand what kind of scaling or interference is needed.
- Large signal: refers to the past similar processes that the current run can be compared to. The paper also asserts they do some periodic checks to ensure that the performance is still good, and adjust the resource allocation if needed, both by adding less or more resources.
Collaborative Filtering Reccomendation
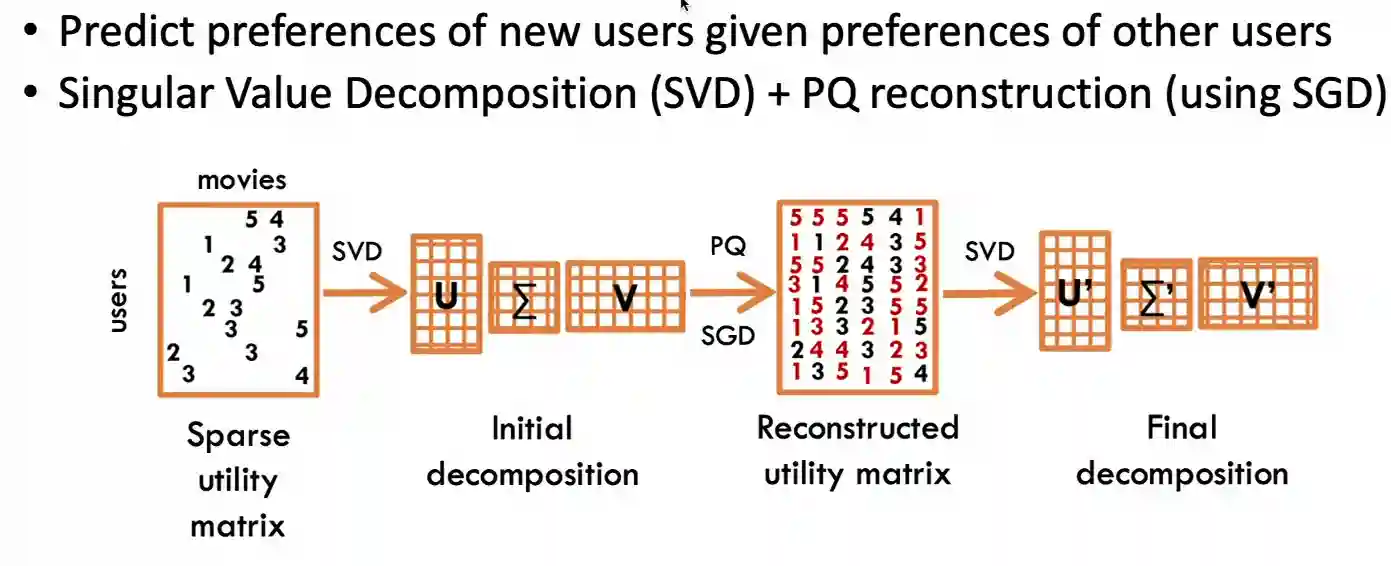
Here: the movies are the resources/platforms or interference types, and users are processes, we want to reconstruct best allocation (reconstruct missing data). After filling out important information, they use a simple greedy scheduler to actually assign the resources. The whole pipeline takes about 80ms (divided in three steps, profiling, classification and scheduling.)
Types of Data Features
The performance might be affected by the following features, Quasar takes also these variables into consideration:
- Scale-out (e.g. using 4 nodes vs 1 node)
- Scale-up (e.g. using 4 CPUs vs 1 CPU)
- Hardware heterogeneity (different CPU or memory hardware and configurations)
- Interference (e.g. running on a shared cluster, might give you different kinds of l1i, l1d, bandwidth types of interference).
References
[1] Ghodsi et al. “Dominant Resource Fairness: Fair Allocation of Multiple Resource Types”
[2] Delimitrou & Kozyrakis “Quasar: Resource-Efficient and QoS-aware Cluster Management” Association for Computing Machinery 2014