There is a big difference between the empirical score and the expected score; in the beginning, we had said something about this in Introduction to Advanced Machine Learning. We will develop more methods to better comprehend this fundamental principles.
How can we estimate the expected risk of a particular estimator or algorithm? We can use the cross-validation method. This method is used to estimate the expected risk of a model, and it is a fundamental method in machine learning.
Validation methods
Cross-Validation
Cross validation is one of the oldest and most popular methods to validate our model parameters.
The following slide summarizes the main idea of the cross-validation method.
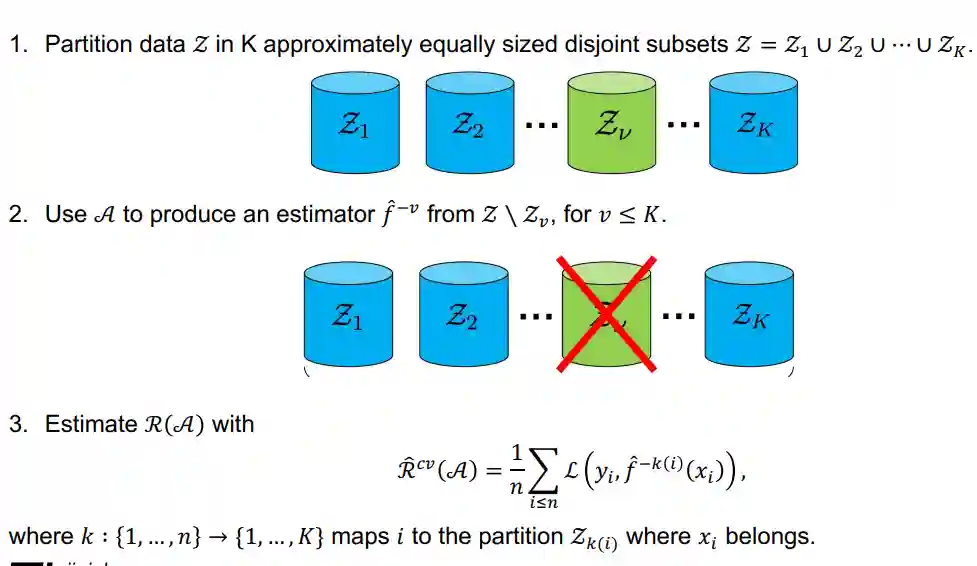
With this method we divide our dataset into buckets and use of those buckets to train and the rest to validate. If where is the size of the dataset this is usually called leave-one-out cross-validation. As with this method one needs to have training, this method is usually considered to be computationally expensive for the algorithms that need a lot of time to train.
Bootstrap
The bootstrap method is a resampling method that can be used to estimate the distribution of a statistic. The idea is to resample from the dataset with replacement and then calculate the statistic of interest. (Has the advantage of using the whole dataset instead of part of it, as Cross validation does) This process is repeated many times to estimate the distribution of the statistic. The bootstrap method is useful when the distribution of the statistic is unknown or when the sample size is small.
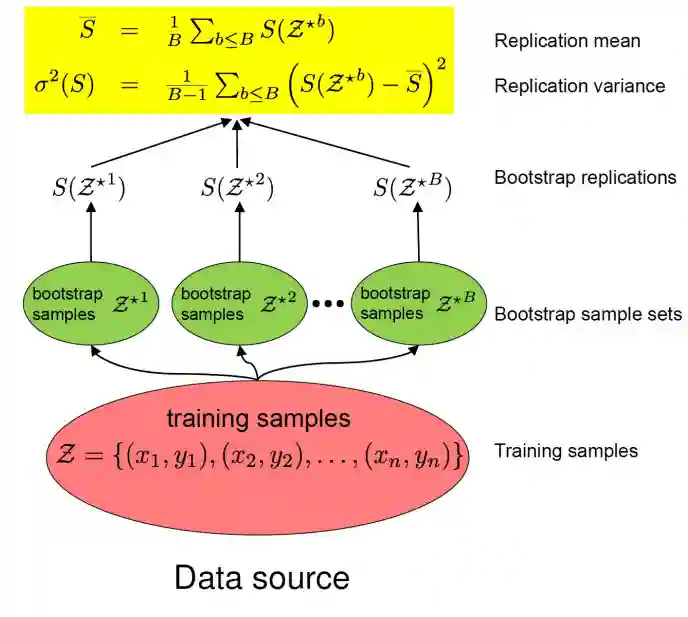
TODO: probability of one sample appearing in the bootsrap samples.
Each sample in bootstrap has a probability of appearing of . Taking this into account, we would need to rethink the computation of the risk splitting it into two cases: Risk = probability that sample is in the task risk in this case + probability of not being in the sample risk in this case. This can be rewritten as:
We can write then as:
And
Hypothesis Testing
Hypothesis testing is like a legal trial. We assume someone is innocent unless the evidence strongly suggests that he is guilty. In (Wasserman 2004).
This seems to be a good resource for p-values.
P-values
We use p-values when we have a clear definition of the kinds of hypothesis that we are going to test. This value is useful if we want to compare two hypothesis: one that is the default safe assumption, and the other that is the surprising possible discovery. Usually we partition the parameter space in two disjoint sets and , where and . Then we have the null hypothesis and the alternative hypothesis . We want to find a rejection region such that if the observed data falls in we reject the null hypothesis, otherwise we accept it.
Most likely the rejection region has the form
Where is called the critical value and is the test statistic.
After we have defined those, we can define the p-value as
where is the rejection region of size . So the P-value tells us how likely are we to accept , if it's small we are likely to reject it, if it's large we are likely to accept it. In practice, we often set the value to be 0.05 as one does not have access to the real distribution of the data. So the p-value just tells us the probability of the null hypothesis to be true. Murphy highlights some questions regarding the validity of that statistics in section 6.6.2 of (Murphy 2012).
Types of error
- Type I error: Rejecting the null hypothesis when it is true.
- Type II error: Accepting the null hypothesis when it is false.
Type I error is usually much more serious than Type II error. It could lead to unintended actions that attempt to leverage on the false information, thus bringing demise. If we want are obliged to choose between one of those errors, one would prefer the Type II error. This is why we only accept the alternative hypothesis when there is strong evidence for it.
Risk of the least risky critical value that would lead to the rejection of the null hypothesis.
Size and Power function
Given a rejection region we define the power function to be
So, the power function is the probability of rejection and is more related to Type II errors.
We want our default hypothesis to be the safest as possible, so usually we consider his size to be the one that has the greatest value:
We say that a test has significance level if its size is less or equal to . Usually the value that is picked is 0.05, but this is just tradition, the value is completely arbitrary.
Wald Test
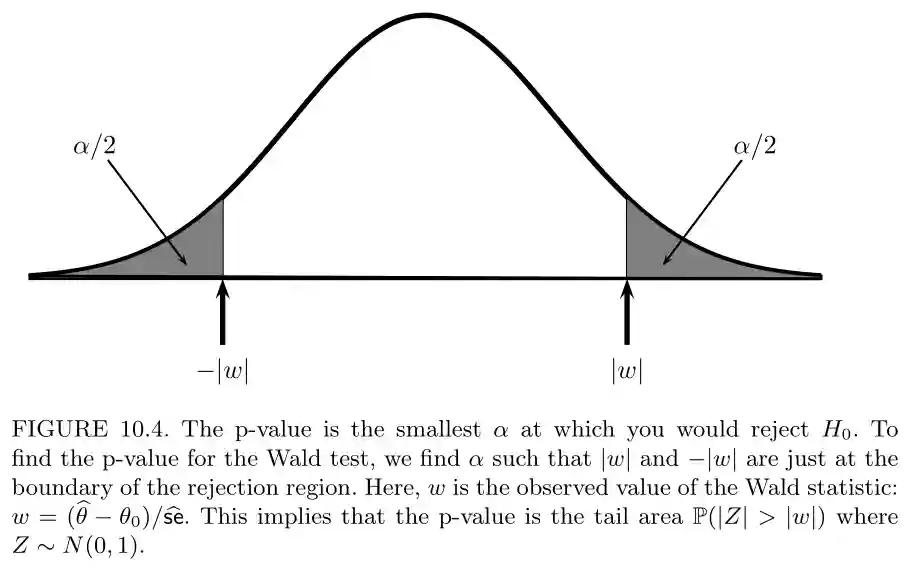
The wald test is defined as
Given a size we reject if where is the quantile of the standard normal distribution.
With this test the p-value is defined as
References
[1] Wasserman “All of Statistics: A Concise Course in Statistical Inference” Springer Science & Business Media 2004
[2] Murphy “Machine Learning: A Probabilistic Perspective” 2012