Introduction to the course
Machine learning offers a new way of thinking about reality: rather than attempting to directly capture a fragment of reality, as many traditional sciences have done, we elevate to the meta-level and strive to create an automated method for capturing it.
This first lesson will be more philosophical in nature. We are witnessing a paradigm shift in the sense described by Thomas Kuhn in his theory of scientific revolutions. But what drives such a shift, and how does it unfold?
A theory which clearly could fail in the light of the data but gives you good hypothesis, that tells you something about reality, because reality is a deviation from complete randomness. Joachim Buhmann
The paradigm shift
An interesting observation is that in the past 100 years, we’ve seen more progress in the field of computer science than in the previous 5000 years. This is due to the availability of vast amounts of data, an increase in the number of scientists, and our development in line with Kurzweil’s theory of exponential growth.
When comparing the human brain to computers, one excels in creativity, while the other possesses far greater storage capacity. This creates a trade-off between creativity and storage. Humans rely on abstraction to comprehend specific aspects in their pursuit of knowledge. Data structures, such as trees, help us retain the essential elements for the tasks at hand.
Computers, however, face no such constraints and can store data in any manner they prefer. While humans can creatively build connections, often in surprising ways, machines lack this level of creativity. That said, we still don’t have a precise definition for creativity—it’s not simply, as Steve Jobs suggested, the act of linking different ideas. Computers are good at density estimation, but their ability to generate truly creative insights remains limited.
Buhmann says that models are good at reproducing the probability distribution that the input data has. But what we care as humans is the wisdom, e.g. what you can do with this information, as introduced in Introduction to Big Data.
Some Epistemology
In principle, epistemology tells you how to extract knowledge from data, from this point of view it can be seen as the precursor of modern information retrieval systems. This tells you something about methods of derivation. The first of which is deduction (Euclid, Hilbert's Grundlagen der geometrie, David Mumford for bayesian reasoning and image processing, but this person is still living). Deduction allows us to create facts by starting with the core principles of our thinking. Later induction was born (philosophically created by Bacon), where you create theory from data, and it's a little bit more machine learning like. The former goes by logic, the latter by intuition (but could be wrong, and it's not formalized), now modeled by statistics and it is what machine learning does. Machine learning just does induction. These two processes of reasoning can be modeled as computational processes. And this allows us to create nice machines that are able to achieve these :D. This was first proposed by Leibniz, who though that thinking is achieved by computing. We can say from some point of view that Leibniz was one of the first theoretical computer scientists. He also invented the binary system.
We use digital data because we can control it:
- Efficient to manage
- Discover models
- test and simulate hypotheses
- Find solutions The last three points can perhaps be called intelligence.
For Joachim M. Buhmann (the prof.), it's impossible to understand the models, and this can be motivated to the limited storage capacity of our brains, so the attempt of interpretability (i.e. correctly understanding exactly what is happening, the law) is just a bias in the history of science for us humans. While if we understand interpretability as a way to summarize useful information, visualizing it, then it is ok.
Reality is a deviation from randomness. Theories that could fail, but do not in light of the data, are the valid ones. Theories that do not tell you anything, that are always true, are useless.
A new meaning for Algorithm
Classically we considered algorithms as a way to process data, efficiently, now we want to treat them as a relation between data and decisions. At the end, the decisions are what is important for us humans. Algorithm's makes it easier for us. Classically we have studied a concept of complexity of runtime, memory, or energy, but we have not have a clear theory of abstraction or robustness. In our case, we have a probability distribution going in, and another going out. But modelling them as random variables, it's difficult to have a clear definition of correctness. We would also further argue that the correctness of the decision is not a clear science, it is more connected to one's specific values and thus we go into ethics.
For Prof. Buhmann a fundamental ability of intelligence is being able to do counterfactual reasoning and planning. So being able to simulate the future, and be able to plan the today's action in order to change the future. This is similar to (Choi 2022) and abductive reasoning by Choi.
Every law is a social experiment on a not understood population
When Buhmann tried to say that nobody exactly understands everything, but a correct level of abstraction is often enough (i.e. chemical processes of the combustion engine)
Studying algorithms is the most complicated part of mathematics when mathematics becomes concrete. 29 September 2023 Joachim M. Buhmann, minute 5.44 in ETHz AML lesson
He said that Kolmogorov Complexity is Shannon's Theory for Random variables?? What does it even mean?
Noise is your friend because it prevents you to make a statement so precise that you cannot compute it
Noise is an indicator that you can't solve your job.
Framework for learning algorithms
Introductory ideas
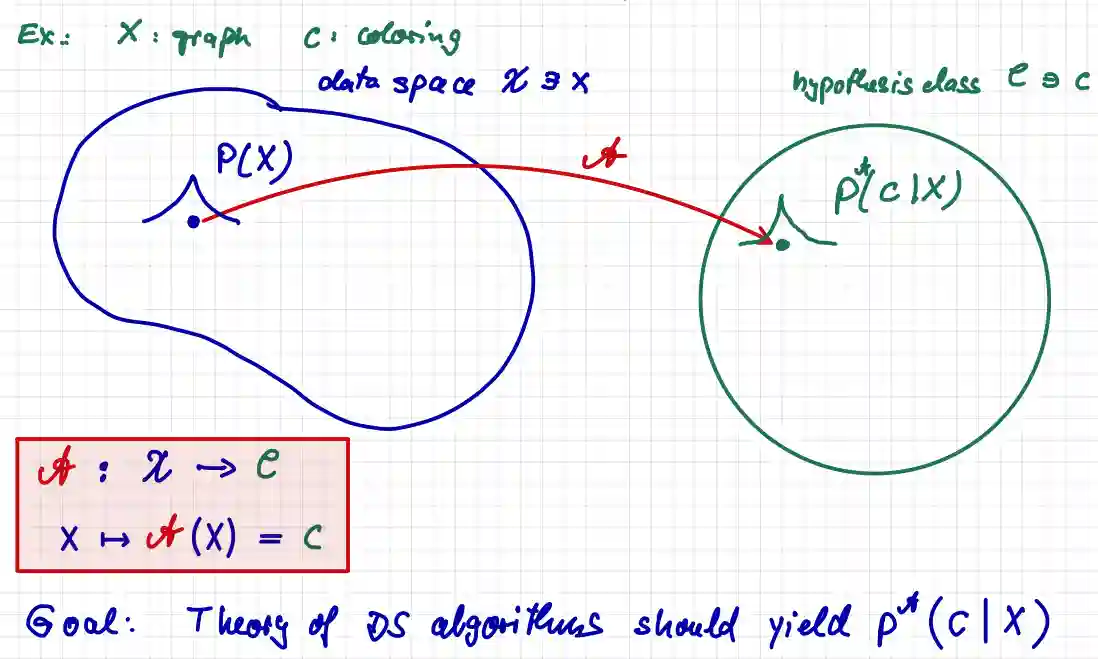
Buhmann argues that all machine learning can be summarized by this simple idea:
Machine learning is getting rid of information that doesn't help you to act.
The Machine learning pipeline
What we want to do is estimating the posterior probability density:
Which goes on this pipeline: And also humans can be part of the algorithm part. The hypothesis can be interpreted as the cause, or the most probable thing that has generated our data. In machine learning context they are the parameters. Usually the hypothesis space is much more smaller compared than the data space. This is also why sometimes we say machine learning is some sort of compression.
Risk and Gibbs distribution
We say that high risk => low probability and low risk is high probability. We have discovered that Gibbs distribution is often a good model for estimating this probability distribution.
This is some sort of parametrization of the posterior function (it's a partial ordering of our hypothesis space, which allows us to optimize for it). And it's the same as Log Linear Models studied in NLP.
The Gibbs distribution is also known as the Boltzmann distribution in statistical mechanics.
Data generation
We want to have a theory used to validate learning algorithms , which admits stochastic data as input.
We define the data to be observations of some experiment of some genre. Mathematically we write , . Meaning: we have an experiment that contributes to the data . We define a hypothesis class where possible hypothesis are located. We use these hypothesis to interpret the dataset .
An example against MLE estimation
Let's consider a simple unbiased coin:
We want to say, what is the most probable sequence in a trials? The answer is easy, its all Heads! But we know that this is very very improbable! The most likely sequence is not what its observed, usually, and this seems like a paradox, and its a strong argument against MLE methods. The best possible sequence (aka the MLE's output) is not always the best for modelling our experiment. We want to minimize risk while maximizing the probability. I still have not wholly understood this example.
Directions on algorithm design
We can broadly categorize the categories of algorithms by how much humans know about the problem.
We can now divide algorithms in three macro categories, based on human-expertise
- Classical algos: humans are able to solve this problems, and are also able to specify those kinds of problems in a logical way
- This is classical algorithm design engineering
- Supervised algos: humans are able to solve these kinds of problems, but don't know how to formalize their logic.
- This is classical supervised learning algorithm
- Unsupervised and self-play: humans are not able to solve these problem good enough, this gave rise to alpha fold, alpha go and stuff similar to this.
- This is autonomous self play, for example (Jumper et al. 2021).
- Unsupervised learning.
Some definitions
A definition of Data Science
We say that data science studies the algorithms that map the data to the space of possible hypothesis .
Statistics usually studies the distribution of data science studies the mappings. Physics and Mathematics, and other sciences study the space of possible hypothesis.
We would say that data science is attempting to learn a function from data to hypothesis. The hypothesis is our interpretation of the reality. We write .
Conditional expected risk
Given a loss function , then the risk of a function given the data is defined as
And the expected risk is just
After we have this we define a empirical risk by splitting test and training and assuming the came from the same distribution. We choose a training error
And we choose Emprirical Risk Minimizer the , this is often too optimistic, and we would also want to use the test data. We want the empirical test error to be similar to the empirical risk, that we don ´t know of, we are interested in the value of
What is Data?
Encyclopedia Britannica: Association of numbers with physical quantities and natural phenomena by comparing an unknown quantity with a known quantity of the same kind.
Measurements by sensors, factual information, numbers. It's not very clear, I would say any numbers that can help you do some interesting inferences in some world (it has to affect some entities (i.e. humans))
What are features?
But we can't use this data directly so we use features of data, that could be arbitrary transformations of the initial data (edges, corners, etc...).
Types of data
Measurements
We say that we have a world of objects, and we do observations about these objects. We say is a measurement (so a data point) where we have a function Choosing a representation of the data is one of the most important parts of machine learning applications. The sample space is the mathematical space where the measurements are represented.
Four types of data
Feature vectors: Categorical data Regression data Proximity data
This division should be pretty intuitive. See the slides for some real examples.
Scales
Nominal or Categorical scales
Example: binary , or some nominal categories (sweet, sour etc)
Quantitative scales
We can divide these scales as interval scales for fahrenheit temperature scale. The important information is between the values, so scale and translation invariant. Ratio scale: the information is the difference with a focal point, for example Kelvin temperature scale Absolute scales where we the important is absolute thing (grade scale ahah).
Buhmann believes humans are only good in relative scale judgement, when they try to do absolute scaling, they can bias negatively or positively. This is why he believes grades should be relative.
Desiderata for Data Science
In this section we would like to describe what exactly is a good data science algorithm.
Hypothesis consistency
The most important requirement is: If and are drawn from the same distribution (one is usually called the experiment, the other is called the control), then meaning the probability of the hypothesis should be similar.
We can call this control experiment and interpret as training data and as test data or control in this setting. But we need to take some care about this statement:
- We want similar inputs to have similar hypothesis
- We want dissimilar inputs to have dissimilar hypothesis If we only had requirement 1, then always outputting the same thing could solve our problem, but more variability is more useful, so we also consider dissimilar hypothesis :).
We can have some similar ideas compared to the Bias Variance Trade-off, that is under-fitting and over-fitting by computing values like:
The best thing is that the two probabilities have a high value in the points were we care. Under-fitting is having low probabilities everywhere, over-fitting is having high spikes, the best is in the middle: see this image: TODO put the image here. This is also called posterior agreement, we will deepen these ideas later in #Log posterior agreement.
The classical problem
When starting to model a problem, we Computer Scientists that have to work on data have to decide the format of the data that we want to use. We want a way to evaluate this problem, discover when it's a good model or not. Usually the trade-off is between the expected classification error, while trying to maximize the generalization ability. We don't have the true expected error, so we use a proxy, the empirical error we can find during the experiments.
Following (Vapnik 2006) we define a learning problem a search of a , and we write . Commonly is parameterized by a . Now we want to compute the risk, which is a loss, a way to tell how much our hypothesis is wrong. There are many possible losses, we won't talk about them here. We call this loss function We say that the conditional expected risk is
And the total expected risk is
But these values are marginalizations, and often infeasible to compute. But the most difficult part of this formula is estimating the , which we don't know. We try to estimate this value by splitting the dataset in training and testing data. But how well can we estimate this? How close is the estimate? We want to know the value of
Where is the best hypothesis for our training data, and is the loss for the test data. We need to have some statistics over this value. k-splitting is a good way to have these statistics.
When we want to mathematically characterize this, we need to keep in mind topology, Inner product spaces, Spazi vettoriali, and Spazi di probabilita.
Log posterior agreement
This section is not exam material (but
- Robust bounds on correctness of ML systems can be achieved (noisy bounds)
- We care about out-of-distribution generalization and fixed entropy of our hypothesis space.
- There are algorithms to efficiently minimize the cost (aka risk, hamiltonian) of out-of-distribution inputs.
- We want a way to measure how well similar distributions induce similar hypothesis. (this is sort of a soundness property).
Let's consider this value
We know that and are independently sampled from the input distribution. The is the same as (mean) which is a normalizing factor for that probability. Remember this:
It's just marginalization.
Now we do some maths, also Jensen's inequality will be needed:
Now we can do some interpretation: The first part is out of sample description length of the hypothesis given the second one is minus the entropy of .
We want a way to describe the quality of an hypothesis (stats people call it risk, physics people call it Hamiltonian) is a function .
The gibbs distribution is often a good way to do this (similar to Log Linear Models):
Some times this is written with the free energy parameter (normalization part)
Where .
We can plug this back into the upper bound (so we can try to minimize the upper bound)
So we may want to do this minimization:
I have not understood exactly why we are doing this.
References
[1] Choi “The Curious Case of Commonsense Intelligence” Daedalus Vol. 151(2), pp. 139–155 2022
[2] Jumper et al. “Highly Accurate Protein Structure Prediction with AlphaFold” Nature Vol. 596(7873), pp. 583–589 2021
[3] Vapnik “Estimation of Dependences Based on Empirical Data” Springer 2006