Devices
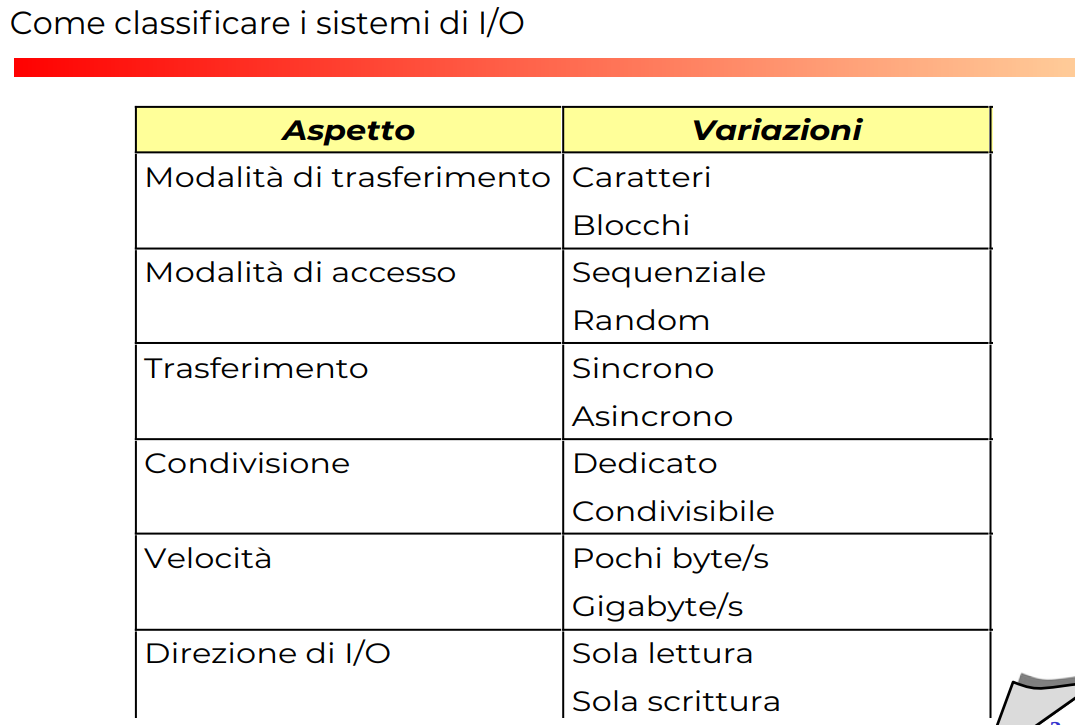
Categorizzazione (6)
- Trasferimento dei dati
- Accesso al device
- sinfonia del trasferimento
- condivisone fra processi
- Velocità del trasferimento
- I/O direction (scrittura o lettura)
Vediamo che molte caratteristiche sono riguardo il trasferimento
-
Slide categorizzazione I/O
Blocchi o caratteri
-
Slide devices blocchi o caratteri


Tecniche di gestione devices (4)
Buffering
Possiamo mettere un buffer per favorire la comunicazione fra i devices. la cosa migliore che fa è creare maggiore efficienza. Un altro motivo è la velocità diversa di consumo.
Anche le schede audio, in cui viene riempito un buffer e poi l’audio viene suonato da questo (differenza consumer e producer), anche per questo motivo è difficile sincronizzare dispositivi differenti (se hanno buffer distinti).
Cache
Invece la cache è trasparente pe ril programma, e rende il tutto più veloce. La differenza maggiore con il buffering è che qui viene mantenuta una copia, non una istanza dell’informazione.
Spooling
Gia trattato per le stampanti in Gestione delle risorse
Scheduling I/O


Storage area network
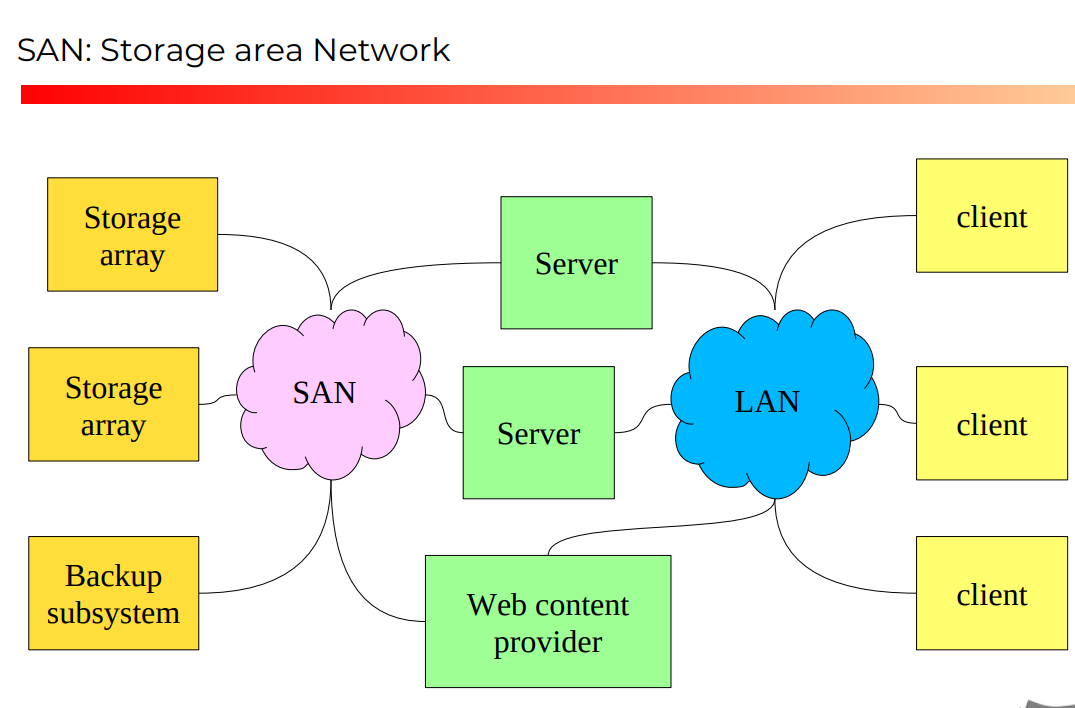
Il vantaggio principale è resilienza del server, che ho il device in altra parte. (non ho iil tight coupling fra server e disco in questo modo, prima se si rompe qualunque, si rompe il servizio).
Ora se si rompe un server, ci sarà un altro server che sostituisce, se si rompe un storage array, ci sarà ridondanza, e altro storage ti risponderebbe. Si vede che questa parte è strettamente collegata con cose fatte in Reti di Calcolatori
Memoria secondaria
Solid State Drive

Un sacco di vantaggi come
- Velocità di accesso
- Meno consumo energetico
- Meno fragilità
- Velocità di lettura è molto veloce.
- Poche scritture (comuqnue tante) comunque limitati cicli di scrittura.
- Uniforme velocità in tutto il disco (questo rende l’accesso veloce :D).
Non andiamo ad approfondire sugli algoritmi di scheduling per le scritture a banco, trattiamo meglio gli HDD.
Hard Disk Drive
Soffrono molto i terremoti perché la testina è vicina al disco e non soffrono problemi di pressione.
Devo avere:
- Testine settore giusto
- La traccia desiderata si muova e mi dia le cose giuste
Questo mi crea 3 parametri per valutare questo accesso
Velocità di rotazione, Tempo di seek o di cambiare cilindro**, velocità di trasferimento**.
Solitamente il tempo più lungo è per il cilindro, poi devo andare alla sezione, e andare alla testina corretta.
-
In generale sul disco:

Ossia solitamente mezzo giro, + tempo cambio
Valutazione tempo di accesso
- Slide tempi di accesso per dischi

In media 100 giri al secondo, quindi tipo 5 ms per andare a trovare la testina corretta, potrebbe essere 2.5 se è il doppio o 1, ma l’ordine di grandezza resta questo per il ritardo.
RAID
Vedere Redundant Array of Independent Disks.
Algoritmi per HHD
First Come First Served
Questo è un algoritmo fair, nel senso che eseguo a seconda di quanto viene, questo non general starvation. Però non minimizza il numero di seek, quindi in generale è più lento. Se invece facciamo in batch, in gruppo di richeiste alla volta sarebbe molto più semplice!
Questa è l’idea del prossimo algoritmo
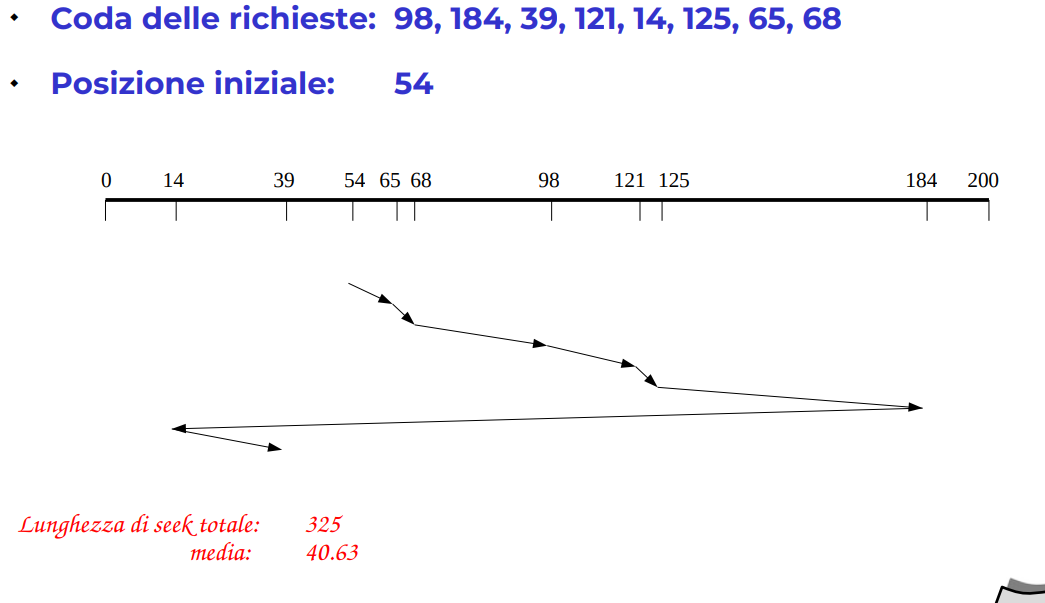
Shortest Seek Time First
Seleziona la richieste che prevede il minor spostamento della testina dalla posizione corrente
può provocare starvation, quando arrivano tante vicine, non visito mai quelle lontane! (Per esempio le richieste fatte su RAID 1, scelgono il disco con meno seek time, ma questo è inteso ad un livello differente). Quindi non abbiamo fairness, e non c’è una buona velocità di risposta per le richieste agli estremi.
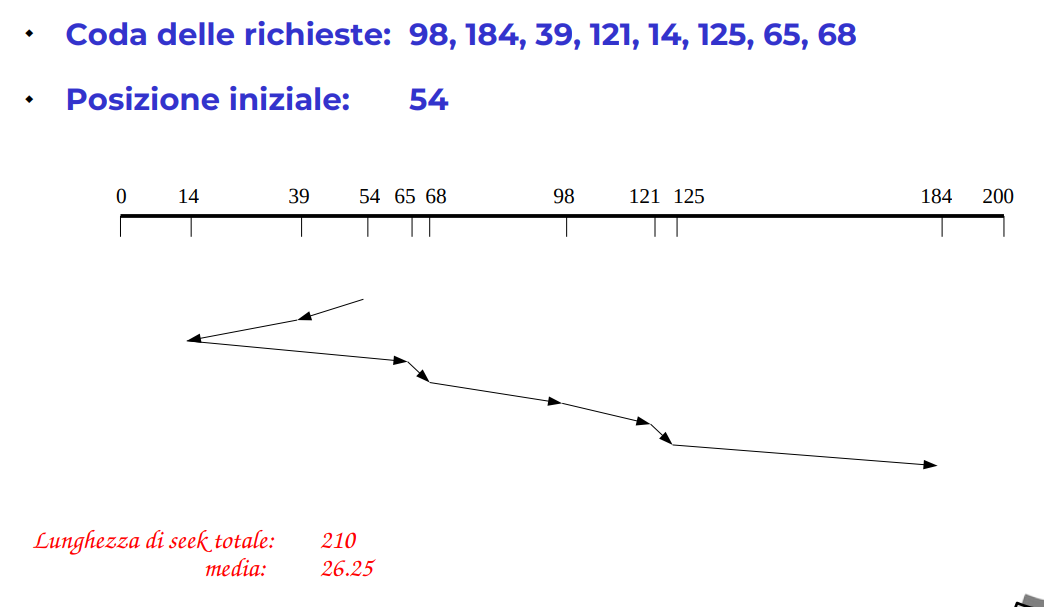
Look - Algoritmo dell’ascensore
Praticamente vado avanti indietro, e quando arrivo alla fine torno indietro, continuo così a soddisfare le richieste.
Il tempo medio di accesso non è omogeneo, le tracce centrali sono accesse più spesso.
-
Esempio ascensore
DISCUSSIONE DI IMPLEMENTAZIONE
Si utilizzano due code. Una coda a scendere e una coda a salire.
Potrei creare starvation quando mi arrivano richieste sullo stesso cilindro, quindi quando succede devo mettere la richiesta nell’altra coda.
-
Implementazione delle due code

C-Look
È molto simile all’algoritmo dell’ascensore, ma solo che quando arrivo alla fine torno all’inizio.
Non ho ancora capito in quali casi può essere utile.
-
Slide esempio C-Look