Introduzione ai Redundant Array of Indipendent Disks
I RAID ne abbiamo citato per la prima volta in Memoria. Come facciamo a stare su alla velocità del processore se questa va a crescere in modo esponenziale? Parallelizzazione della ricerca!. Ecco perché ci serve raid (oltre alla ridondanza quindi più sicuro). E possono anche fallire. → ammette recovery.
E una altra cosa bella dei raid è che sono hot-swappable cioè li puoi sostituire anche quando stanno runnando.

Speed Analysis
| RAID | Capacity | Max failures | Read speedup | Write speedup | Max reads | Max writes |
|---|---|---|---|---|---|---|
| L0 | 24 GiB | 0 | ≈ 6x | ≈ 6x | 1 | 1 |
| L1 | 12 GiB | 3 | ≈ 3x | ≈ 3x | 2 | 1 |
| L2 | 16 GiB | 2 | ≈ 4x | ≈ 4x | 1 | 1 |
| L3 | 20 GiB | 1 | ≈ 5x | ≈ 5x | 1 | 1 |
| L4 | 20 GiB | 1 | 1x | 1x | 5 | 1 |
| L5 | 20 GiB | 1 | 1x | 1x | 6 | 3 |
| The important thing to keep in mind is if the raid version is bit-wise or block wise. Having disks bit wise can help you speedup single writes or reads, having them block-wise help them do it concurrently. |
livello 0 (striping)
I dati vengono messi su più dischi. Viene utilizzato per applicazioni in cui serve velocità, senza interesse di perdita di dati. Ad esempio in dipartimento ci mettono copie di SO per aggiornare il sistema operativo.
UTILIZZI:
-
per grandi trasferimenti di dati, efficiente, in particolare se la quantità di dati richiesta è relativamente grande rispetto alla dimensione degli strip
-
per un gran numero di richieste indipendenti efficiente, in particolare se la quantità di dati richiesta è paragonabile alla dimensione degli strip
-
Slide RAID 0

Slides from Bologna Operating Systems Course 2023

Slides from ETHz Course CCA 2025
Livello 1 (mirroring)
Ci sono 2n dischi e metà sono delle copie esatte.

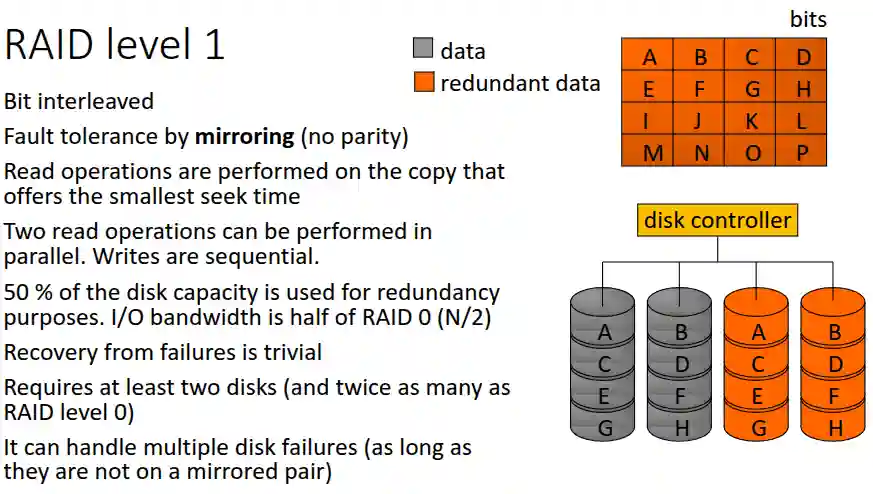
In questo caso la scrittura è più lenta della lettura, si può vedere però che offre una semplice e buona forma di ridondanza.
Tollera un singolo guasto al massimo, o più dischi differenti (non devono essere le due copie diciamo). Si dice fault tolerance livello 1.
Nested RAID
We can nest raid 0 with 1 or the reverse. It has tradeoffs with respect to the I/O bandwidth.
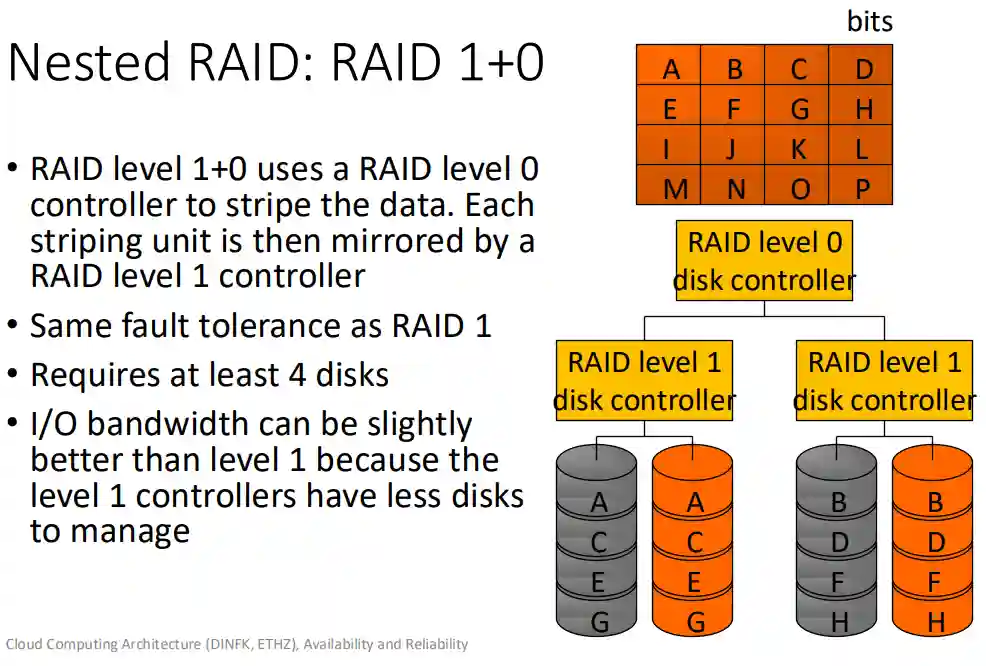 More used for large disk arrays usually present in the cloud.
More used for large disk arrays usually present in the cloud.
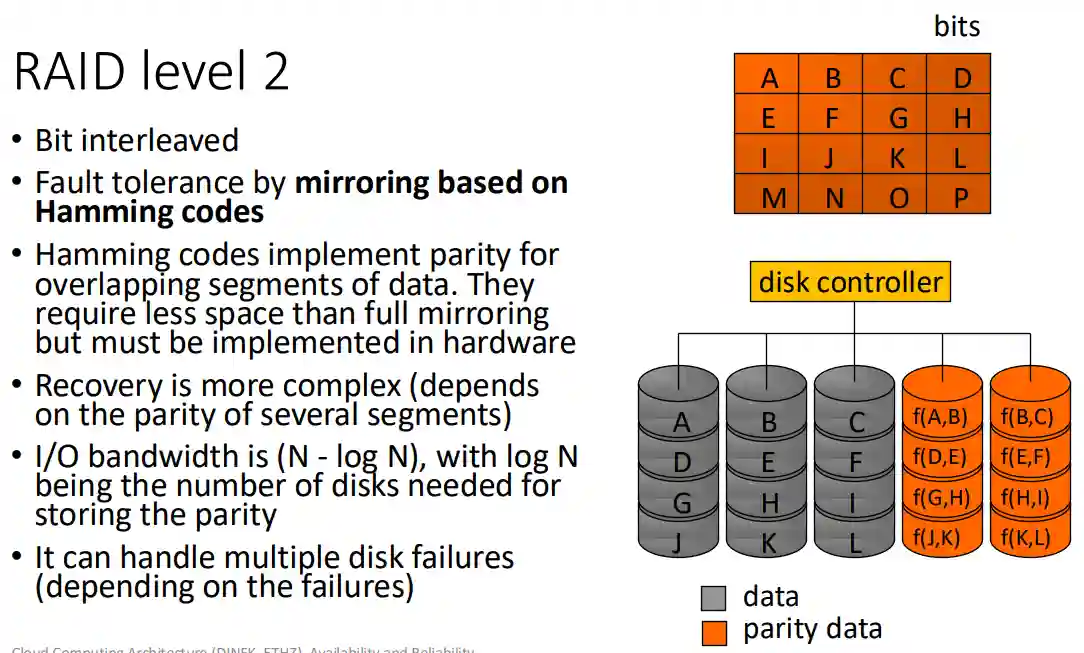
Livello 2
Si usano codici di Hamming a livello bit
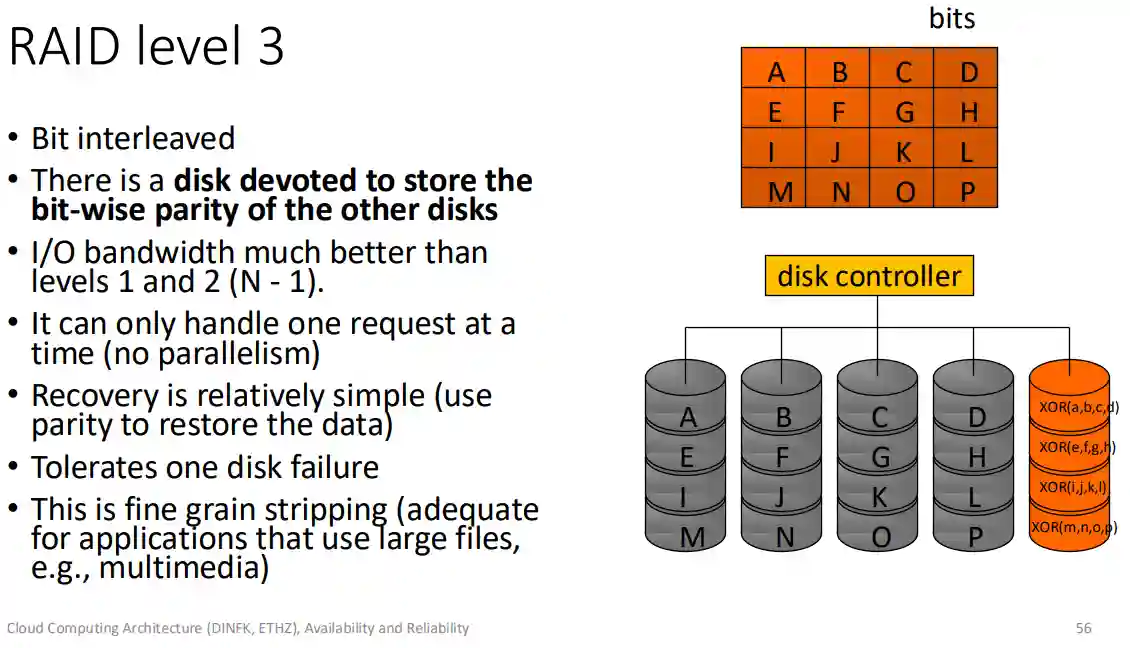
livello 3
Si usano bit di parità, ma lo facciamo a livello del singolo bit, mentre il livello 4 lo fa a livello del blocco.
Livello 4
La differenza col livello 3 è che questo livello è molto più Coarse-Grained (see Cloud Reliability), quindi ha una banda minore, ma latenza minore per letture larghe.

Utilizzo un intero disco solamente per la parità su un disco. così se si rompe un disco riesco a ricostruire le informazioni di quel disco.
Non è efficiente perché se cambio un dato devo andare sempre a fare due write su dischi diversi. E poi continuo sempre a scrivere sullo stesso disco! Quindi fai finta 4 write contemporanei, per aggiornare gli altri dischi! Per questo c’è il bottleneck
Livello 5

Se c’è un disco rotto si rallenta, ma non si perdono dei dati! è il funzionamento degradato dei raid. Non ho problemi di bottleneck, e ho ancora la velocità del livello 1
Livello 6

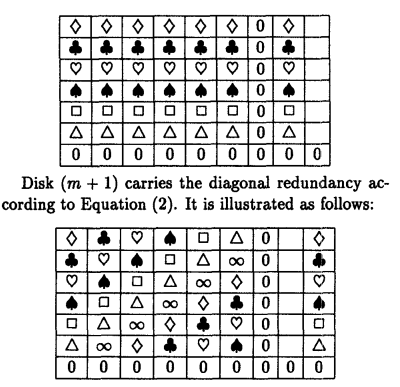
http://www.cs.unibo.it/~renzo/doc/p245-blaum
Questo è per cose sicure, riesce a tollerare livello 2 fino a due dischi rotti. Ovviamente è una parità diversa, in modo che riesco ad avere più fault tolerance. Si utilizza un XOR in diagonale e questo sembra funzionare, anche se non ho capito perché.
- Intuizione mia
In pratica qualunque modo prendi due dischi non di check (se uno è un disco di check è molto ez).
Allora puoi fare questo:
- Recovery dei dischi in alto a sinistra e in basso a destra, questi si possono recoverare solamente con i bits diagonali, quindi posso già farlo.
- Utilizzo questi strips recuperati e utilizzo quelli orizzontali per recuperare l’altro della stessa row, poi utilizzo diagonale per recuperare quelli corrispondenti in row diverse e continuo così e riesco a recuperare tutto., Sarebbe molto utile fare un esempio per mostrare questo, ma spero che il me futuro quando legge questo riesca a ricordarsi l’esempio su carta.