Egocentric vision is a sub-field of computer vision that studies vision understanding from a centered point of view, that typical of animals. One historical thing is MIT 1997 they had to bring around very heavy cameras. Now we have glasses. Other examples of egocentric vision are cars with cameras that see their surrounding, or robots equipped with cameras mimicking human vision. The difference of egocentric vision compared to standard vision techniques is the high variability and instability of the video, and the concept of movement and interactions inside the image. Standard computer vision is disembodied and controlled field of view.
Comparison between fixed and wearable camera
| Camera Type | Pros | Cons |
|---|---|---|
| Wearable Camera | ✓ Dynamic uncurated content | ✗ Occlusions |
| ✓ Long-form video stream | ✗ Increased Motion blur | |
| ✓ Driven by goals, interactions, and attention (embodied) | ||
| Driven by goals interactions and attention | ||
| Fixed Camera | ✓ Static setup | ✗ Curated moment in time |
| ✓ Controlled Field of View | ✗ Disembodied |
Vannevar Bush’s Vision and Memex
Seminal paper, he saw that human knowledge would have expanded a lot, and he says we need new methods to manage this technology. He imagines a machine he calls Memex to store the knowledge in books, see this video. This article, (Bush 1945), is often cited as one of the intellectual origins of the web and modern knowledge systems. He anticipated Hypertext, personal computing, wearable technology and speech recognition.
History of Egocentric Vision
Research attempts
In 1968 we have one of the first head mounted displays, and Steve Mann’s inventions in 1970 has pioneered some of these wearable computing. In public media we have Terminator 2 that has given some ideas of egocentric vision. Then you have MIT’s media lab going on with these works, Oxfords’ robotics research group. We also have Sixth sense in 2009, presented in a TED talk, which was quite impressive.
Commercialization attempts
Other commercial attempts where Hololens, Google Glasses, more recent apple glasses, or Meta’s Aria glasses. We are also able to track gaze now.
Datasets
Epic Kitchens is a famous dataset for egocentric vision. EGO4D is one of the most recent datasets, with a HUGE speedup. These are unscripted activities This dataset benchmarks episodic memory, social interaction, hands and objects interactions and audio-visual diarization and future forecasting. So you see it is important to create highly curated datasets. HD-EPIC is another dataset, but egocentric (increasingly more and more). Now that you have more dataset, you can build models and try techniques to solve it.
Applications
Problems common to this field of egocentric vision are:
- Localisation (where am I)
- Scene understanding
- Action recognition, anticipation and gaze understanding and prediction.
- Social behavior understanding
- Full body pose estimation, see Parametric Human Body Models.
- Hand and hand-object interactions, which is a quite complex problem.
- Person identification
- Privacy
- Visual question answering
- Summarization
Hand and Hand-Object Interaction
Internet scale datasets
- Collect lot of hand data (3k hours of video, all annotated).
- Extract hand state information about these videos.
- Bounding box all the hands (left and right annotation), and also objects and its contact (none, self/person/portable/non-portable).
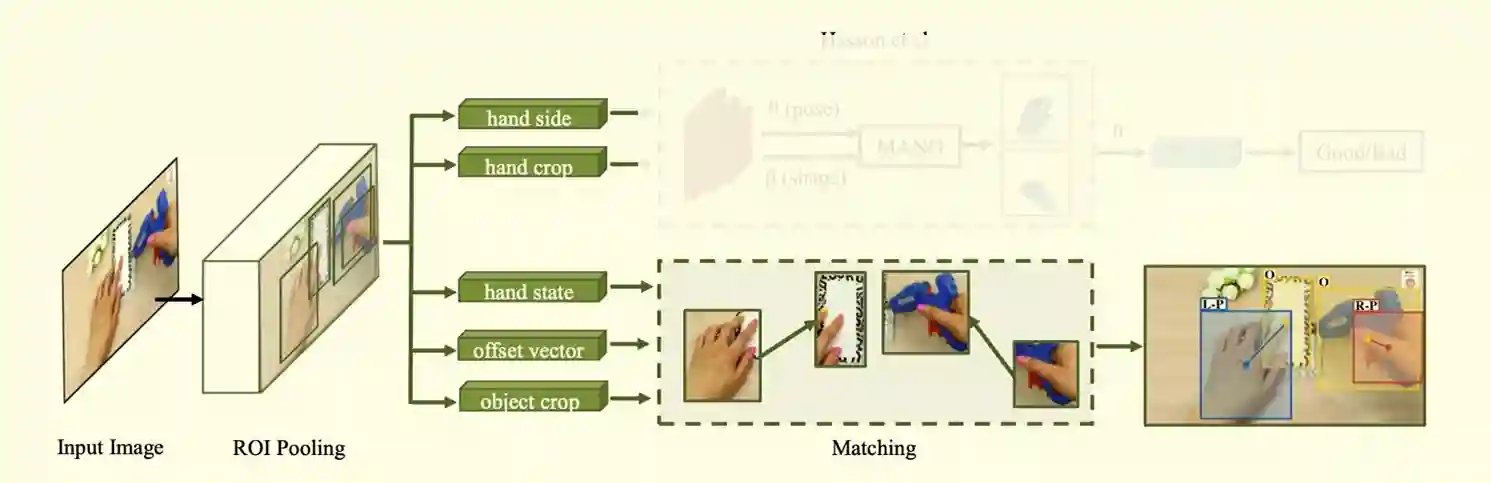
They claim
- 90% accuracy across datasets
- Automated 3D hand mesh reconstruction
- A nice application is how hands would grasp objects that they never seen.
DexYCB
This is a dataset of videos that grab things:
- 2D object and keypoints detection.
- 3D hand pose estimation
- 6D object pose estimation (translation and rotation variables).
They claim this dataset is useful to learn object manipulation for robotic hands.
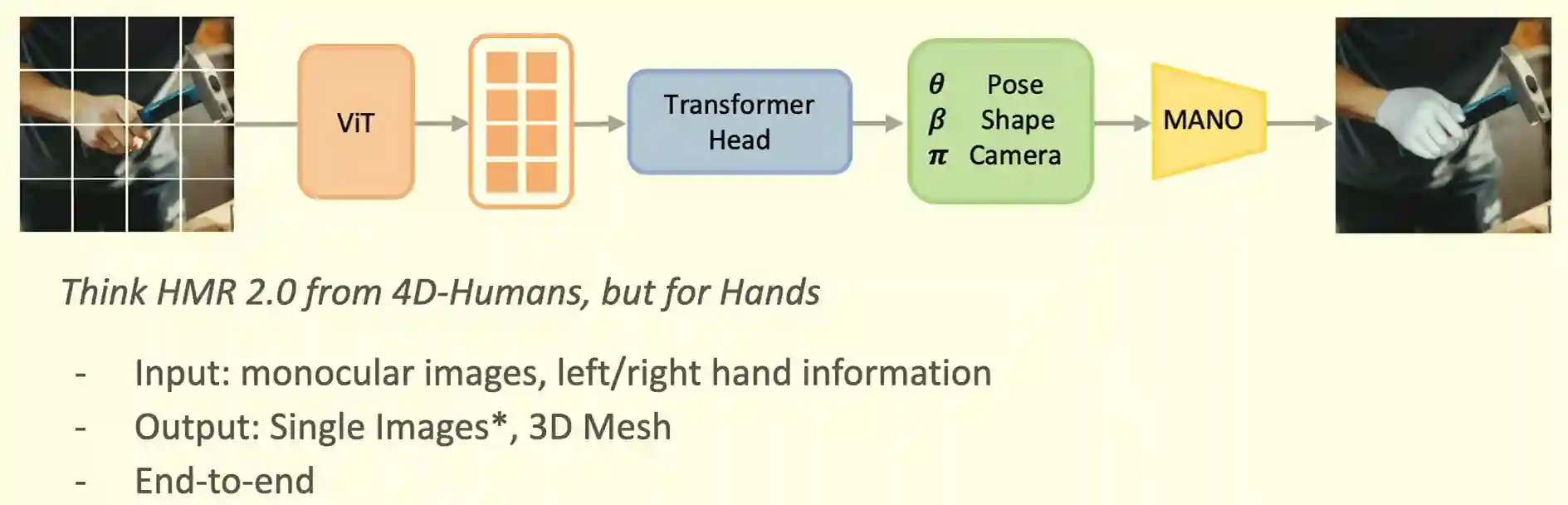
HaMeR
Is the state of the art end-to-end hand reconstruction framework. They use Visual transformers to estimate the parameters of the hand model (shape, pose and camera) to reconstruct and reproject it to the image.
Action Recognition and Anticipation
We want to be able to predict goals, interactions and attention from dynamic uncurated embodied video data. Predicting this part should be useful to recognize and predict actions.
There are lots of works in psychology about intention, close to theory of mind, and my own paper in (Huang et al. 2024).
Summarize the past to predict the future
Short object interactions from EGO 4D benchmarks. Predict interaction object, the action and time to contact. They try to summarize important parts of the environment (like, are you in kitchen?, are you doing specific things, for example have you just picked up chopsticks?) This is extracted by language context extraction, then put it into TransFusion and predict next parts. They just do part of speech tagging to get noun and verbs and create mos t probable action annotation for the data. Then they use CLIP to match words and the objects in the image. Everything is then fused together and they use a fast R-CNN RoI heads to make noun, verb, box classification.
They show that dynamic information is hard to predict using this framework. This is why the TTC value is a little bit less accurate. Using language they had better generalization ability.
PALM: Prediction Actions through Language Models
They use a transformer to predict the future action. They use the past and the future to predict the action. They use a language model to predict the action, similar to transfusion, but they move to the language domain before predicting the next action.
They see that if you have many objects, the LM has a big difficulty in predicting the action.
Gaze Understanding and Prediction
With this technology we can estimate the visual attention from egocentric videos. They add the global-local correlation module.
Driving applications
One important application is for driving, you can predict ego-trajectory prediction using these techniques. GPS locations inside the car are quite off, it is better to put them outside.
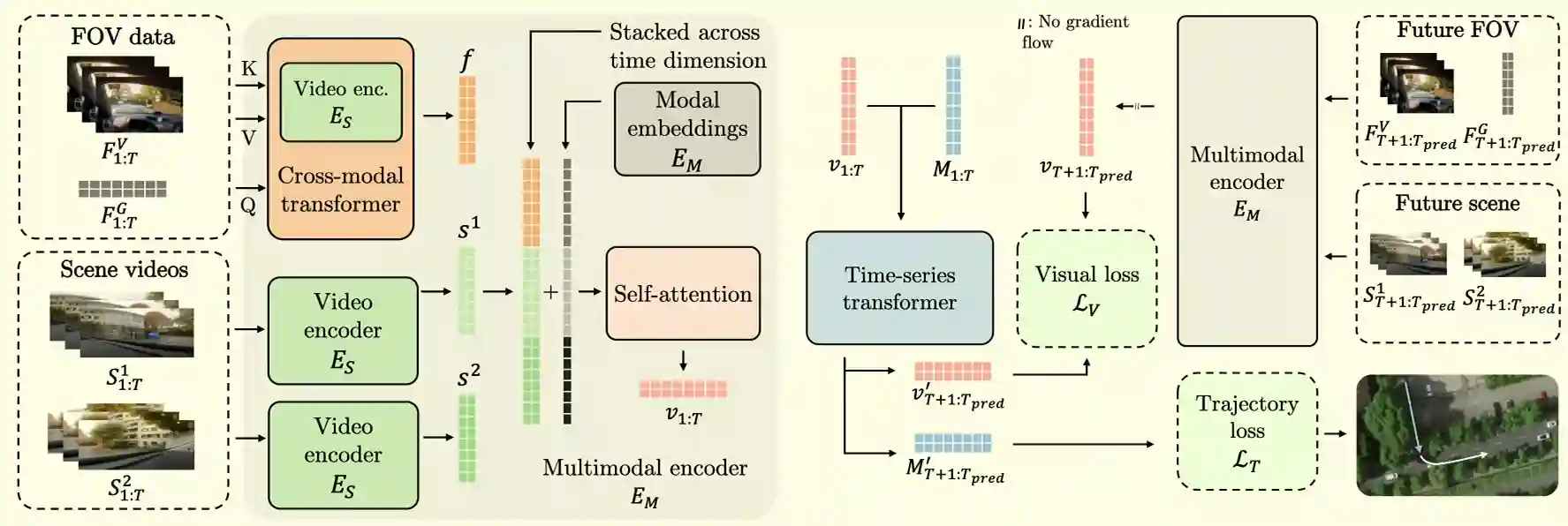
They can used shared embedding models and the feed it into a time-series transformer. One problem is being able to use long-tail distributional data. Visual Loss was to regularize the network.
Path Complexity Index
Most driving datasets are long tail distributions. The idea of this index is to take
take speed of the last moment and have a simple linear interpolation, and compare it with the real path, and have a difficulty measure in this manner, by comparing difference of linear and real path:
$$ PCI(\mathcal{T}_{target} | \mathcal{T}_{input}) = \| \mathcal{T}_{target}(t) - \mathcal{T}_{simple}(t) \| $$$$ \begin{aligned} \mathcal{T}_{simple}(t) &= \mathcal{T}_{input}(T) + v_{final} \cdot t, \quad t \ge T \\ v_{final} &= \mathcal{T}_{input}(T') - \mathcal{T}_{input}(T' - 1) \end{aligned} $$Indeed it is correlated with turning angles:
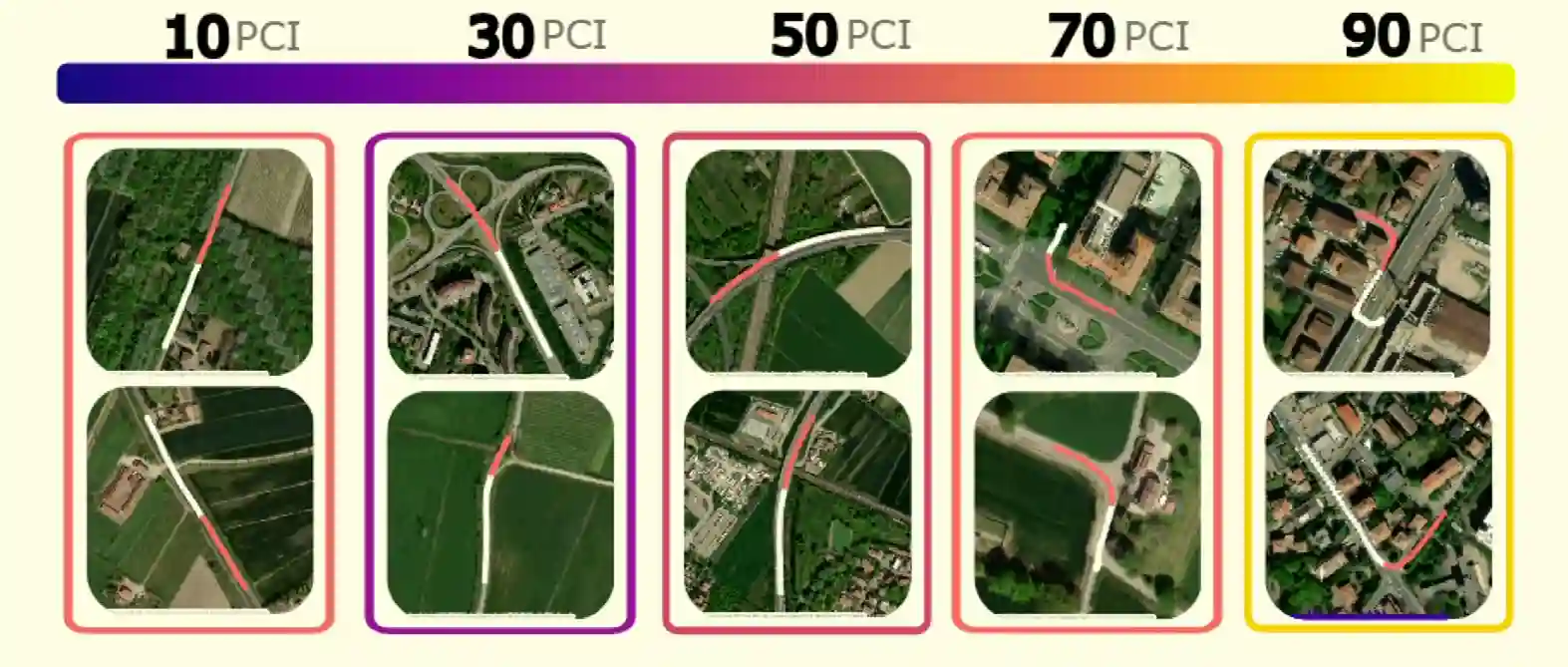
They also show that adding GAZE improves with most complex datasets using this measure.
3D Scene Understanding
There some hard problems:
- Camera motion and narrow vision that make it hard to understand what you are doing
- Contextualization of the scene
- 3D interpretation of the camera motion.
EgoGaussian
You have a 3D representation where the object is moving around. They segment background and object, then they add the changes of the object and complete the shape of the object.
Robotic Applications
Kitten Carousel
One of the most famous experiment in psychology was the Kitten Carousel in the 1963. Here we have a active cat that moves around and see the world, and the passive cat can just see but cannot move. It was to study the visual development of cats. Passive cats cannot develop their visual system. This is a very important experiment in psychology.
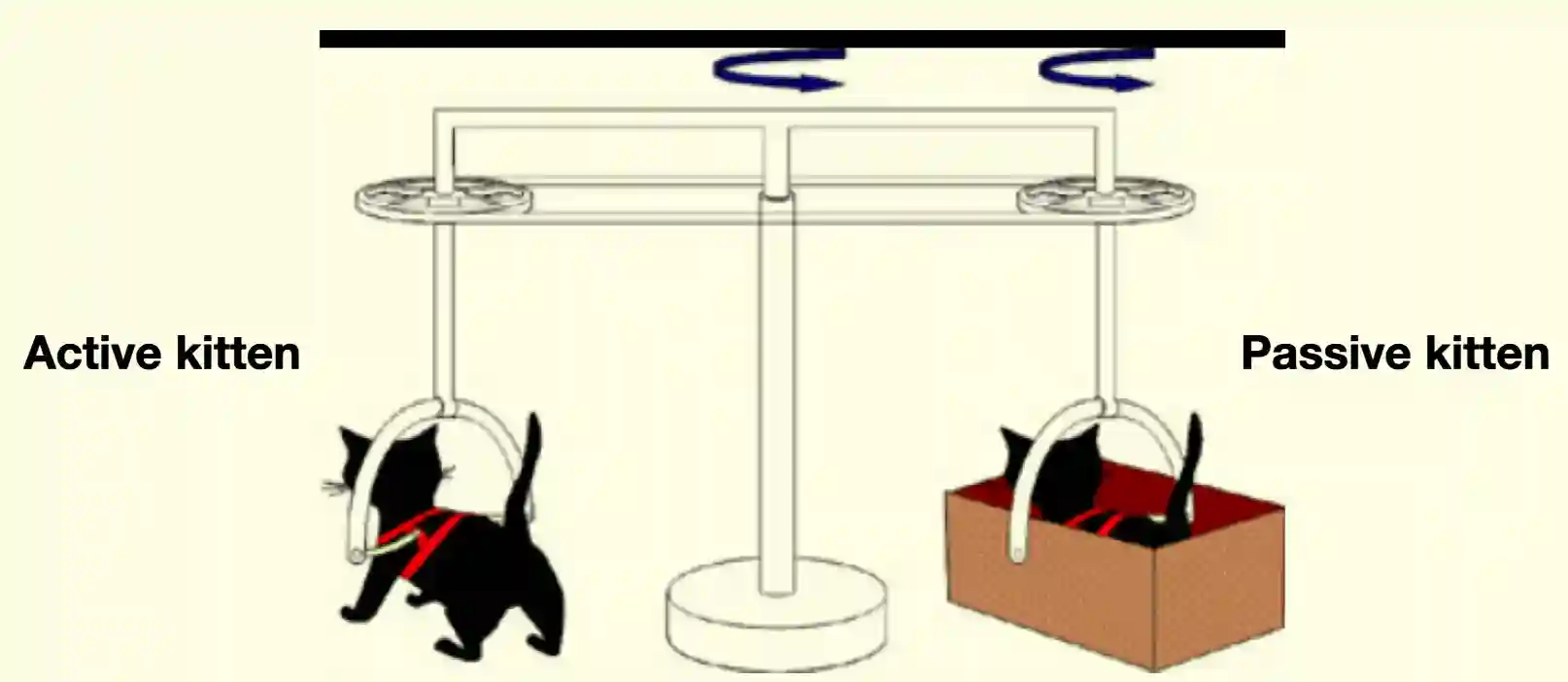
This suggests that to really being able to navigate the real world, you need to be able to navigate it (self motion + feedback), not just passively observe it.
Visual encoder for Dexterous manipulation
They use a visual encoder for features extraction, which is then used to policy training which is then used in the real world.
MAPLE
Another useful work is MAPLE: using manipulation priors (contact points) that are learned from egocentric videos to attack these kinds of problems

They use a ViT encoder to return the contact points and hand poses as tokens, then you move it to a diffusion policy to extract everything. They also have a label extraction pipeline.
Generalizable Ego-Vision World Model
(Gao et al. 2024) is an example of these world models. You want to be able to predict next frames and being able to make prediction based on these predictions.
References
[1] Bush “As We May Think” The Atlantic 1945
[2] Huang et al. “A Notion of Complexity for Theory of Mind via Discrete World Models” Association for Computational Linguistics 2024
[3] Gao et al. “Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability” arXiv preprint arXiv:2405.17398 2024