Perché filesystem?
Questa è l'idea presa dall'archivio, come se fosse un ufficio che deve tenere delle pratiche ordinate in cartelle e cartelloni.
L’utilizzo principale è dare un interfaccia comune di accesso ai dispositivi. perché dispositivi diversi hanno sotto modi di accedere diversi, questa interfaccia facilita molto l'accesso.
Informazioni dei files (5+)
Il file è l’unità logica di memorizzazione. il formato che c'è dentro è gestito dall'applicazione, non dal file system!
Lista degli attributi
![[image/universita/ex-notion/Filesystem/Untitled.png]]
![[image/universita/ex-notion/Filesystem/Untitled 1.png]]
Ci sono un sacco di informazioni memorizzate nei file (un sacco di metadata anche)
- Nome
- Data e ora di accesso o modifica
- Informazioni sull'ownership e protezione di accesso.
- Dimensione del file
- TIpo del file
Categorizzazione dei files (3)
-
Tipi di files

Possiamo andare a distinguere i files a seconda del
- Contenuto (se contiene codice oggetto, se contiene dati o informazioni)
- Struttura, se sono plain text sequenze di bytes, oppure dati strutturati come database., e possono anche essere un albero**.**
- UNIX: files speciali (blocchi o caratteri), pipes, oltre ai classici files e directories. NOTA: ci sono molte cose che sono viste come files, in unix tutto è un file :D.
- Sono identificati da una coppia di numeri che identificano il device driver
Files in sistemi operativi comuni
I files sono nati con la metafora dell’ufficio:
- Archivi di informazione, che vanno aperti e richiusi (messi nella loro collocazione corretta)
È utile conoscere il tipo di file per capire quale utilizzo andiamo a fare di essa.
C’è un tradeoff, se ho tanti tipi di files, il sistema operativo diventa molto più complesso, se ho troppi pochi potrebbero essere troppo generali.
-
Slide tradeoff tipologie di files

Tecniche di identificazione dei file (3)

Generalmente ci sono 3 modi per riconoscere il tipo di files:
- Magic numbers
- Attributo tipo del filesystem
- estensione.
Rispettivamente queste tecniche sono utilizzate in:
- Win (estensioni)
- Mac, informazioni aggiuntive sui files
- Unix, il magic number all’inizio dei files
-
Slide metodi di riconoscimento nei sistemi di riconoscimento

Unix riconosce solamente gli eseguibili, in questo senso è minimalista.
Col magic number riesce anche a riconoscere l’architettura target dell’eseguibile.
Mac OS ha un codice identificativo per un programma che ha creato il file o la risorsa.
Windows guarda l'estensione. che solitamente sempre da 3 caratteri. (inizilamente il nome del file aveva solo 8 caratteri.
Metodi di accesso comuni (3)
-
Slide metodi di accesso

-
seguenziale
-
diretto
-
indicizzato
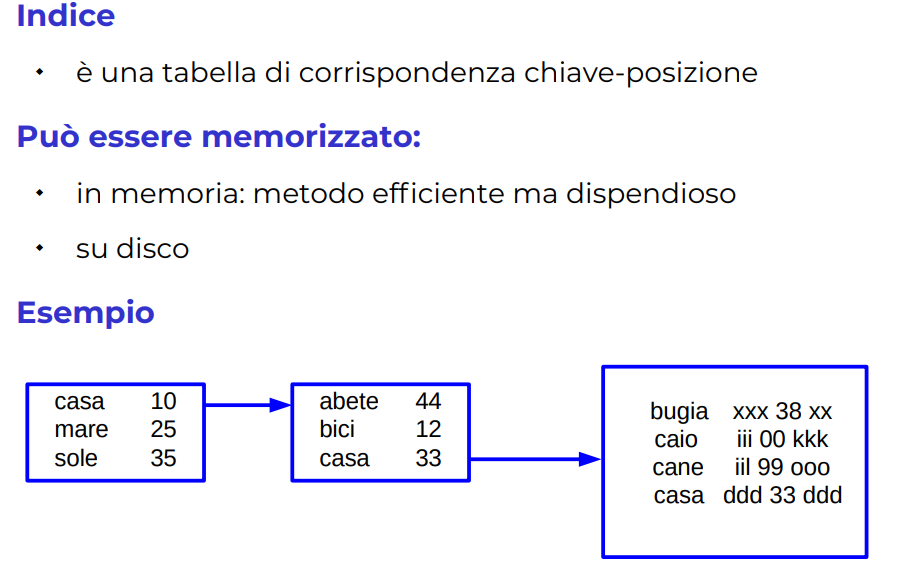
Uno di particolare interesse è INDICIZZATO, che si usa spesso per i databases:
-
Slide metodo di accesso ad indice
Operazioni sui files
-
Slide lista delle operazioni

L’apertura è una operazione molto costosa, bisogna
- Trovare i files
- Capire se si hanno i permessi corretti per poter leggere, o scrivere sul file.
Questo si collega molto bene con la metafora dell’ufficio e con l’archivio. Se ne ho bisogno vado a prendere dall’archivio e la apro se mi serve. Una volta finito lo si rimette apposto.
-
Note sull’apertura e chiusura dei files

Directories
Introduzione alle directories
![[image/universita/ex-notion/Filesystem/Untitled 10.png]]
È quindi un file speciale che contiene le informazioni di accesso per la gestione dei files al suo interno.
A seconda dell’implementazione possono essere degli array lineari oppure degli hashtable. (si pensi a quanto possano essere grandi le directories, se uso una lista diventa molto lento, se invece si sa già che sia piccola si perde del tempo a fare l’hash).
Informazioni nelle directories (2)
-
Slide informazioni delle directories

Sono contenuti i-nodes, che sono degli indici per andare a comprendere la struttura dei files.
Ma può cambiare, questo è un fatto implementativo, potrebbe benissimo anche essere messo nelle entries della directory.
UNIX → messe negli i-node
MSDOS → messe nelle dir entries.
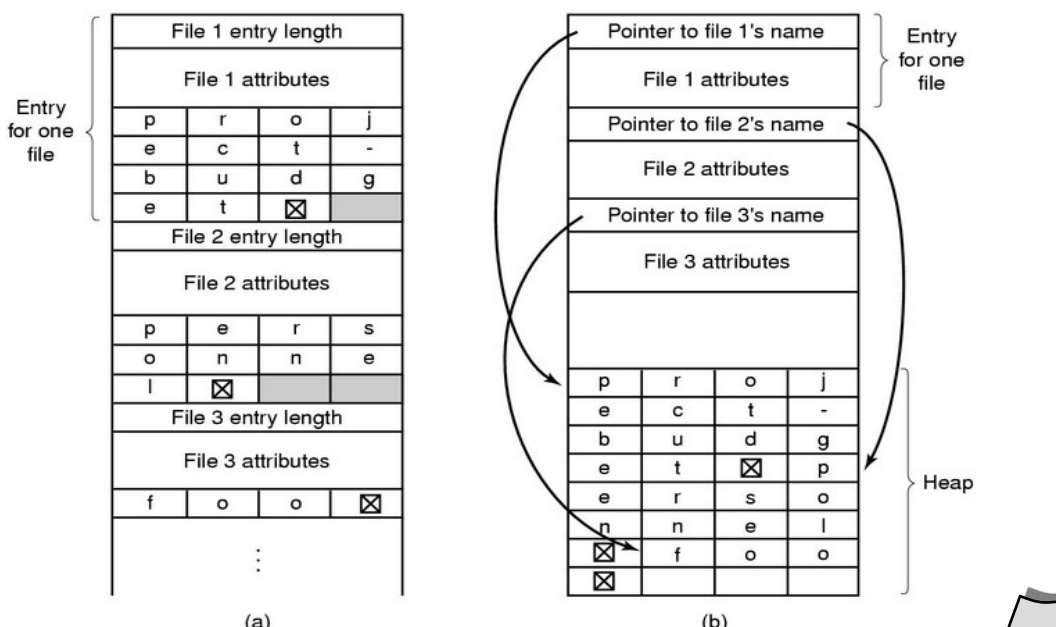
Lunghezza dei nomi
- Introduzione al problema della lunghezza dei nomi

Anche qui facciamo distinzione fra nomi a lunghezza variabile e nomi fissi, MSDOS al tempo utilizzava nomi fissi con necessariamente estensioni a tre caratteri.
- Metodi per nomi a lunghezza variabile
Il metodo a è preferita, perché nel secondo devo leggere in fondo per trovare il nome del file
Directories a grafo aciclico
I files, possono avere più nomi, in questo senso non ho più un albero ma un grafo.
- Slide struttura grafo aciclico

Semantica di coerenza
Dato che i sistemi moderni sono maggiormente tutti multitasking, vogliamo andare a specificare quando una modifica di un file può essere vista da un altro processo.
immediato: questa è la semantica che viene utilizzata anche nei sistemi UNIX, una modifica è subito vista da altri programmi. Bisogna chiedersi ora come si faccia ad implementare una cosa di questo genere.
AFS: è un esempio di file system interplanetario, in cui non era possibile fare una semantica imemdiata (i dati erano sparsi in mezzo al mondo). semantica di coerenza delle sessioni è il nome di questo. ossia il file veniva modificato quando il file era chiuso. Questo era necessario perché ogni write dovevano rendere traffico sulla rete, era troppa questa sincronizzazione e troppo traffico direi.
La struttura
Inode
Allocazione
Master Boot Record
-
Slide MBR
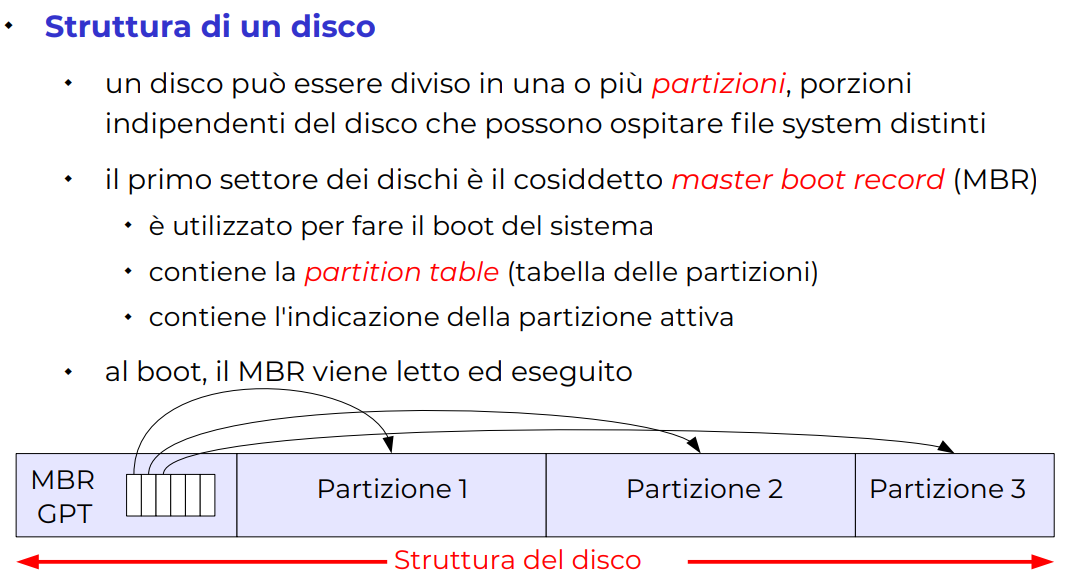
Questo è il classico modo di fare partizioni, e si possono fare al massimo 4 partizioni.
Praticamente è una prima sezione del disco, che contiene una piccola tavola di partizioni, indice alla partizione attiva e informazioni per fare il boot, poi individua la sezione della partizione col boot, ed esegue quello per caricare il sistema operativo.
È utile soprattutto per creare delle aree logiche diverse in cui possono esserci diverse informazioni.
(altro è global partitioning table anche GPT, che permette più partizioni)
Struttura di una partizione (5)
![[image/universita/ex-notion/Filesystem/Untitled 16.png]]
-
Slide spiegazione sezioni logiche della partizione

- Un boot block che c'è sempre
- Superblock contiene informazioni per mount, ad esempio è qui che si accorge se è stato unmounted o mounted correttamente
- Alcune cose per gestire spazio libero ed occupato
- Directory root
- e poi il filesystem è gestito come pare a seconda dei filesystem
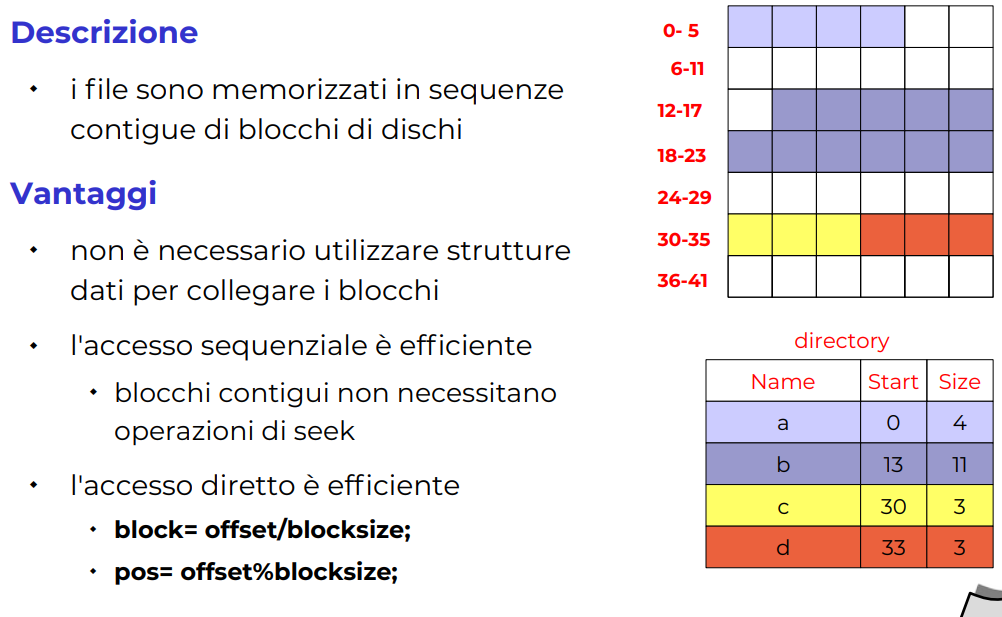
Allocazione contigua
-
Slide allocazione contigua
-
Slide svantaggi allocazione contigua
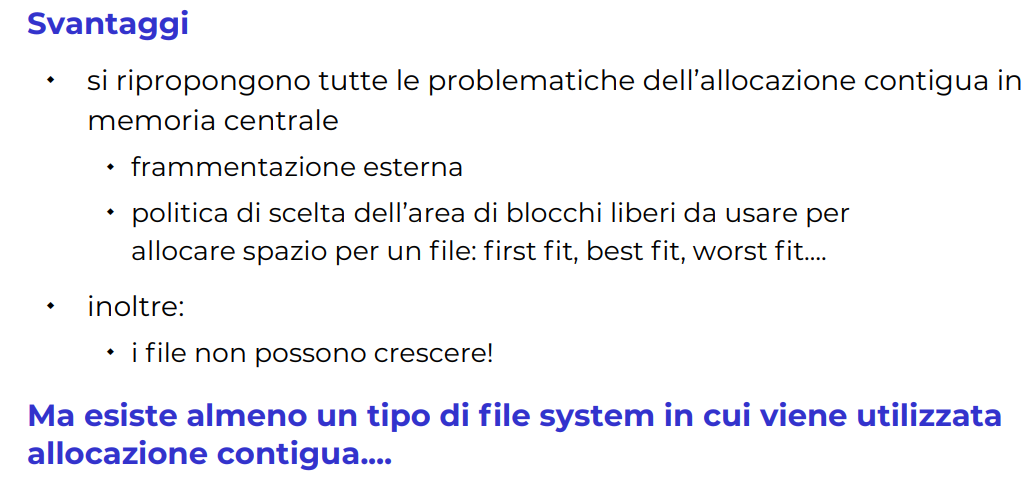
Contigua nel senso che lo metto nel blocco di memoria contiguo libero.
Questo è l’implementazione più veloce, facile da indicizzare.
Il problema principale è che è statico, per esempio non posso allargare il file giallo, si dovrebbe andare a cercare un blocco abbastanza largo per storare questo. Questo è il problema principale.
Infatti se ho un filesystem si sola lettura viene utilizzato questa tipologia di allocazione ISO9660
Allocazione concatenata
-
Slide allocazione concatenata
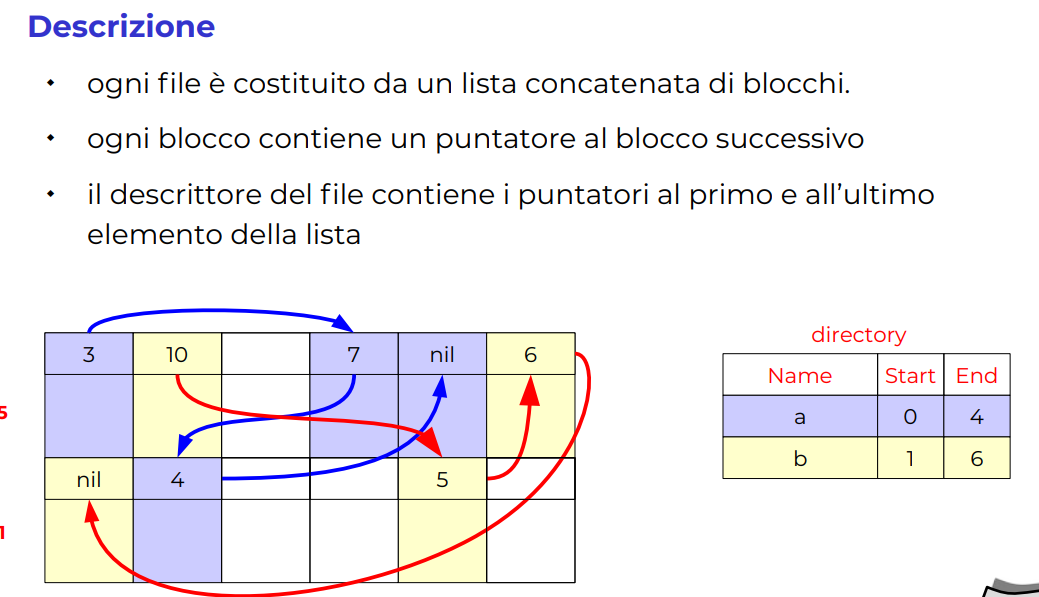
-
Slide vantaggi svantaggi

In pratica in ogni blocco di dati abbiamo un indice per il prossimo (però è lento perché sono molto sparsi, perché devo fare seek e i file vanno in molti posti, per questo dovrei lanciare defrags molto spesso, ma almeno i file possono crescere ed essere modificati liberamente)
SVANTAGGI:
- Accesso inefficiente (posso solo inziare dall'inizio a scandire, non posso fare un offset)
- è che i puntatori possono avere un grosso overhead per blocchi di dati piccoli. (e anche l'assunzione che il blocco di dati non è più una potenza di due).
- Seek di file, che vengono dispersi per utto il disco
Per limitare la frammentazione dei file e l'overhead posso utilizzare cluster
-
Slide cluster blocchi

Allocazione a File Allocation Table (FAT)
-
Slide FAT
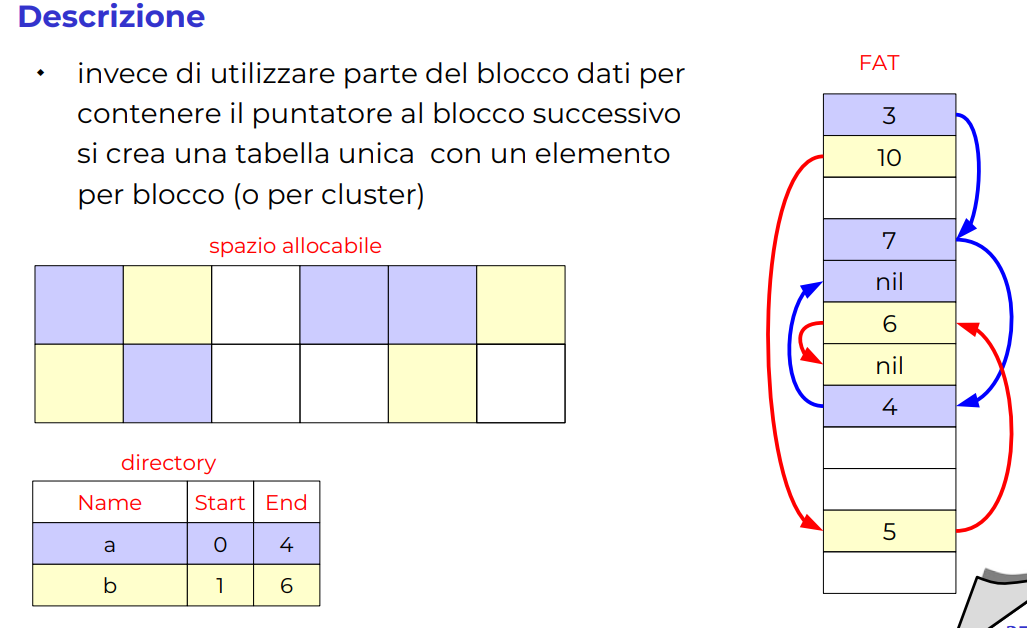
-
Slide svantaggi e vantaggi

In pratica ho una tabella apparte che mi dice in che modi i blocchi sono concatenati, in questo modo tolgo l’overhead ai blocchi stessi e posso gestirmi apparte sti puntatori.
Sarebbe lento un accesso in più alla tabella fat, ma di solito questa viene caricata in RAM come se fosse una cache, quindi è molto più veloce. (se poi il blocco è grosso si dovrebbe perdere molto di meno).
Sarebbe lenta perché il disco dovrebbe andare avanti indietro ogni volta per accedere al blocco successivo.
Allocazione indicizzata
-
Slide allocazione indicizzata
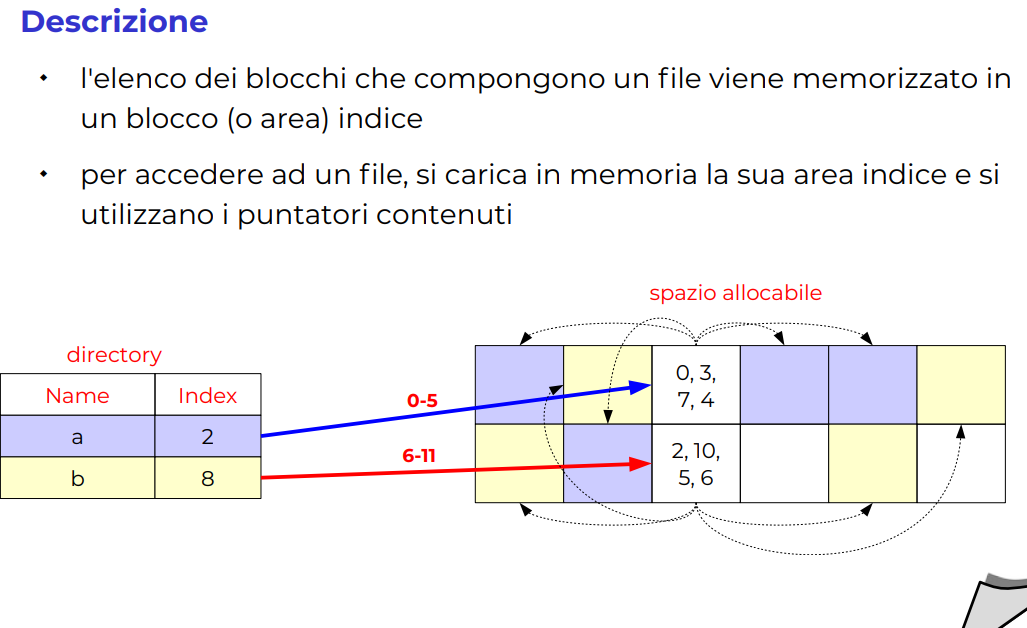
In pratica ho un blocco di dati che contiene solamente i blocchi di dati del file, questo permette un accesso diretto molto veloce. Però non posso avere una lunghezza a piacere del file, perché il numero di indici in un blocco di dati è limitato (prima aveva dimensione a piacere).
-
Slide svantaggi vantaggi2

SOLUZIONE ALLA LIMITAZIONE INDICI:
-
Concatenazione blocchi indici
-
Slide soluzione concatenazione
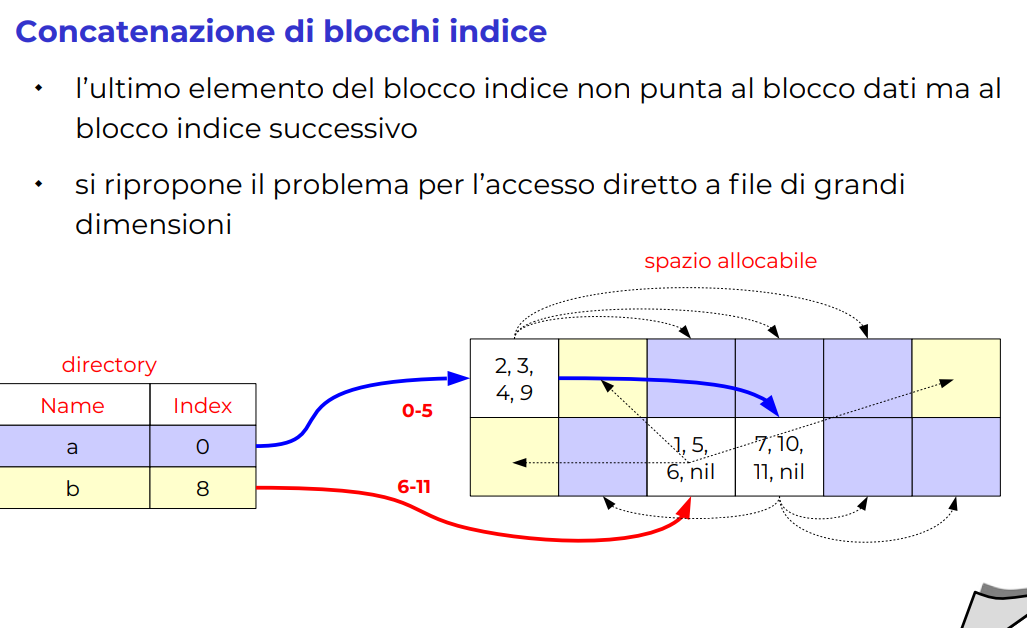
Però con questa soluzione torno ai problemi di accesso diretto lento e frammentazione delle allocazioni precedenti (→ prestazione degrada linearmente con i blocchi)
-
-
Multilivello
-
Indice multilivello
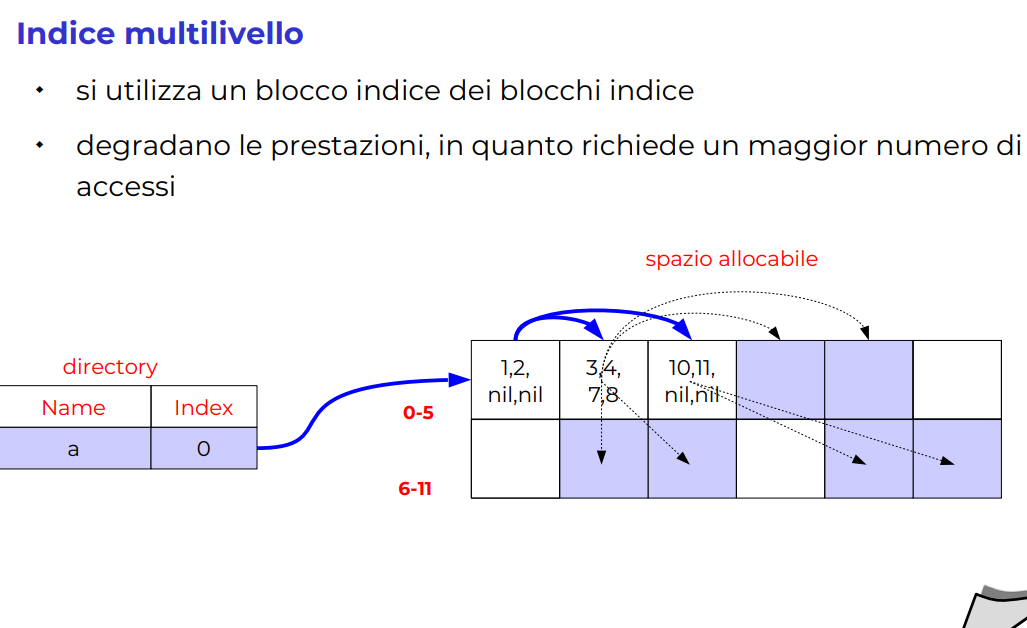
Questa cosa si può rendere ricorsiva, la prestazione degrada logaritmicamente, molto poco abbiamo una sorta di albero here.
-
Gestione dello spazio libero
Bitmap
-
Slide allocazione bitmap
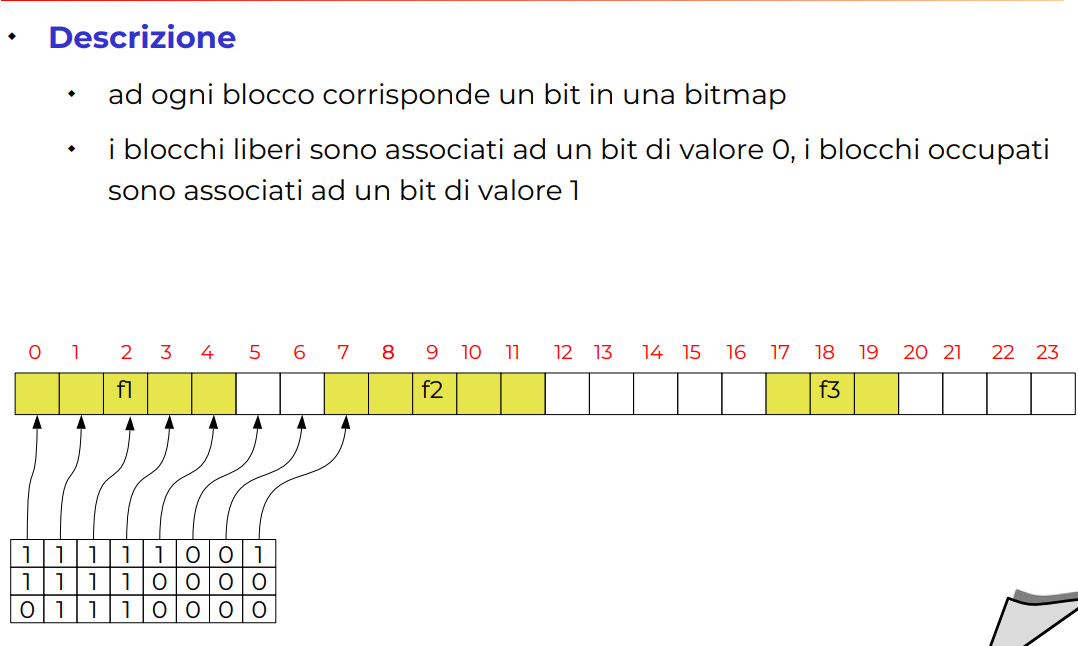

Ho praticamente una bitmap con un bit per ogni cluster, per indicare se è libero occupato, una soluzioen simile è anche utilizzata in Bitmap
Lista concatenata
-
Slide lista concatenata
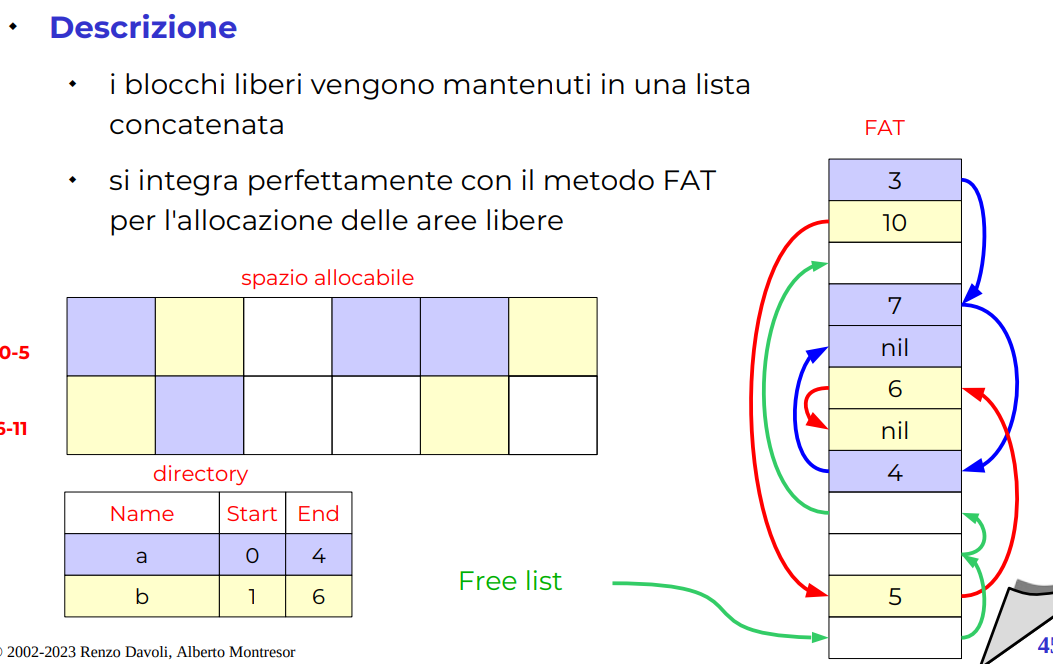

Problemi di frammetazione grossi, dato che i blocchi libero possono praticamente stare ovunque.
Anche questo metodo l'abbiamo descritto in Paginazione e segmentazione, abbiamo anche una lista di bloccchi liberi per la FAT. ne abbiamo parlato anche in Gestione della memoria per la HEAP, gli algoritmi alla fine sono gli stessi.
Confronto cluster dati e spazio utilizzato
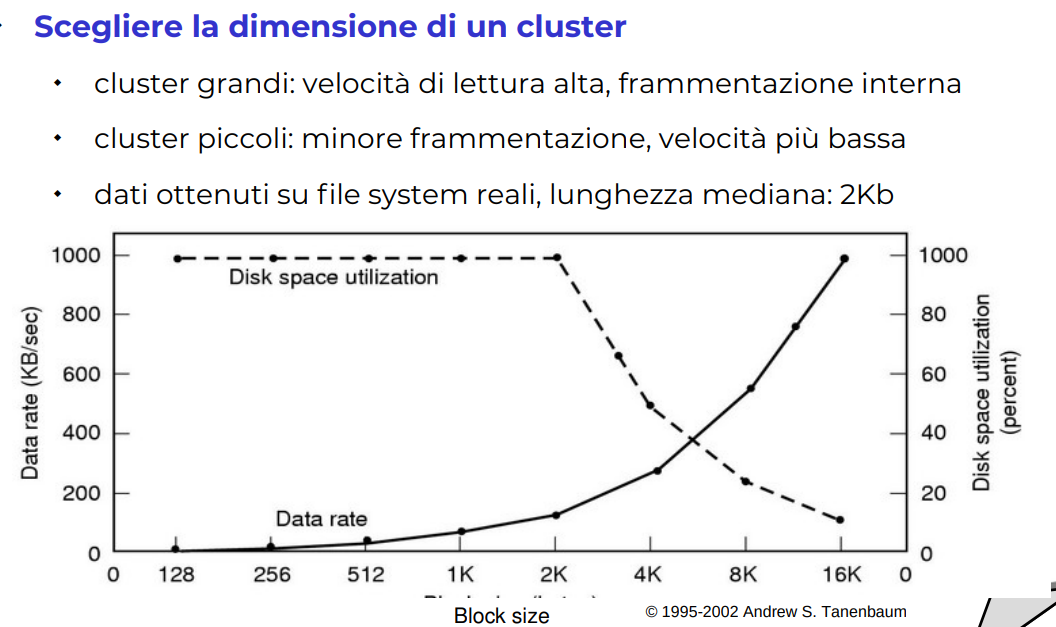
Notiamo che dopo un certo punto se abbiamo un blocco di dati troppo grosso il disco lo utilizziamo poco ma il rate dei dati è molto bello. Quindi se ho dati grossi ho buona roba.
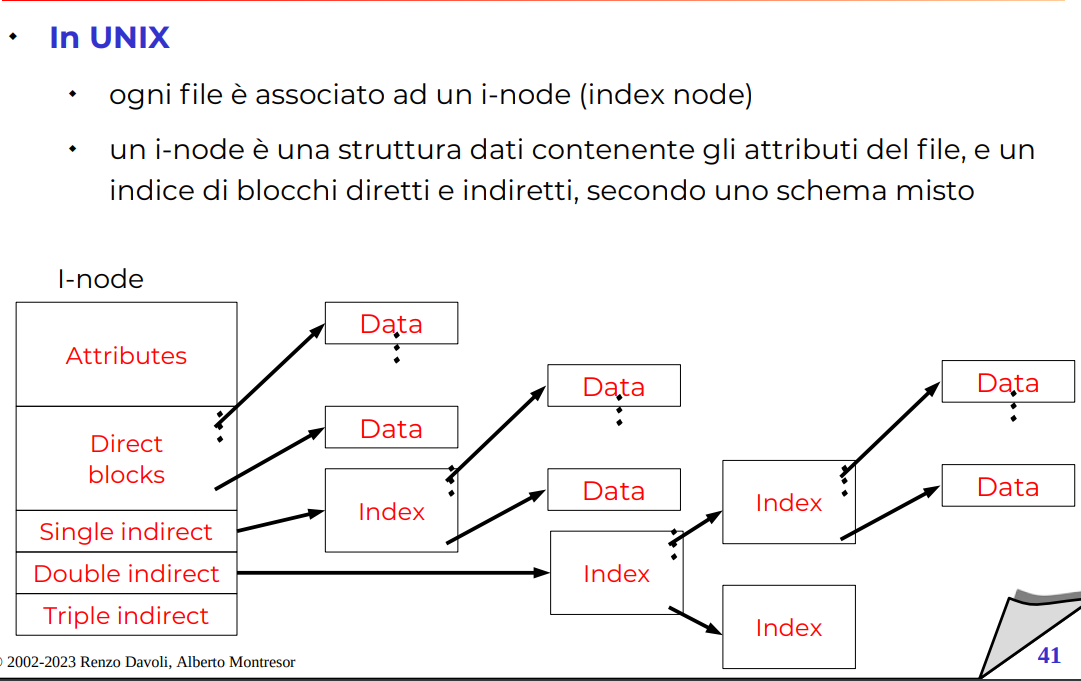
In UNIX
Multi-livello in unix.
Ci sono tanti file piccoli e pochi grandi, quelli grandi possono essere anche molto annidati con l’allocazione indicizzata multilivello. I file piccoli sono molto veloci di accedere, sono praticamente subito accessibile
Link hard e soft
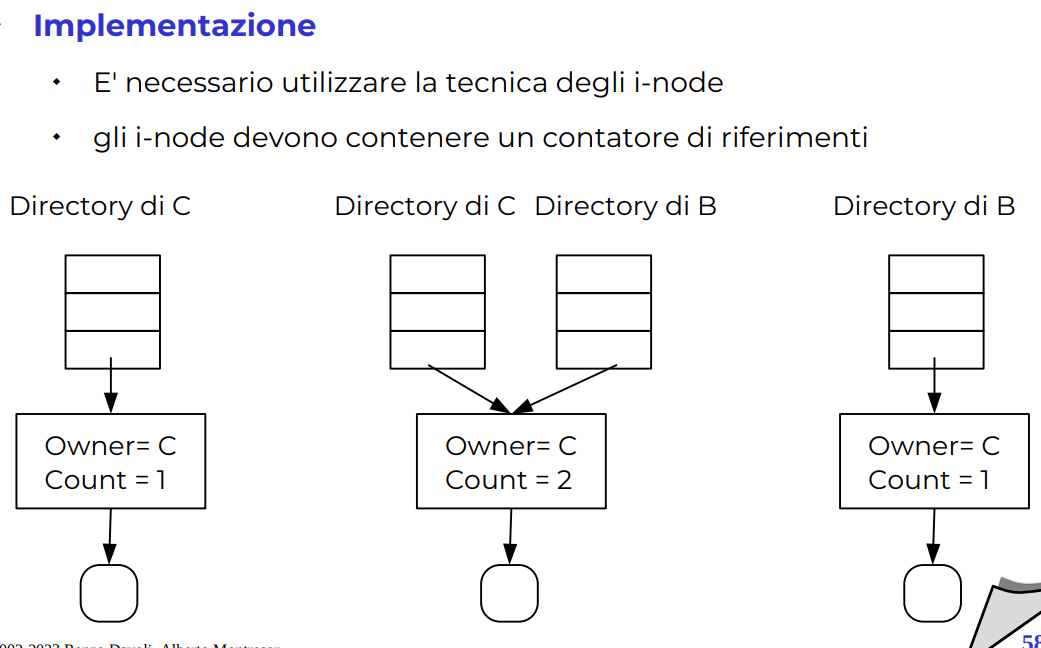
Per sistemi FAT questi non sono possibili solitamente. in unix è identificato dall’inode, se due cose indicano lo stesso inode ecco che posso creare un link, è come se avessi due files per lo stesso inode.
La cancellazione logica è proprio chiamata unlink, quando l’ultimo nome del file è tolto allora il file è stato cancellato.
Il soft link è un file, il so capisce che è un link, ma non si riferisce allo stesso inode.
Curare e prevenire
Curare il filesystem significa riportare lo stato del filesystem in uno stato coerente, ma non abbiamo garanzie riguardo che i files siano stati tutti salvati correttamente
il check è uno scan completo di tutto il filesystem
-
Slide curare fsck

Praticamente l'eseguibile fsck si va a ricostruire l’albero degl inode, se non c'è nessuna reference la mette nei lost and found, riporta tutti gli errori di block size e path names.
Per filesystems che prevengono ,come ext3, prova a vedere tutto come una transazione, quindi va a registrare le operazioni riguardo il filesystem in un singolo file. Dopo ciò si mette a farlo. è idempotente.
-
Slide transazioni

Concatenata
FAT