Queste note sono molto di base. Per cose leggermente più avanzate bisogna guardare Bayesian Linear Regression, Linear Regression methods.
Introduzione alla logistic regression
Giustificazione del metodo
Questo è uno dei modelli classici, creati da Minsky qualche decennio fa In questo caso andiamo direttamente a computare il valore di durante l'inferenza, quindi si parla di modello discriminativo.
Introduzione al problema
Supponiamo che
- siano variabili booleane
- siano variabili continue
- siano indipendenti uno dall'altro.
- sono modellate tramite distribuzioni gaussiane
- NOTA! la varianza non dipende dalle feature!, questo mi permetterebbe di poi togliere la cosa quadratico dopo, rendendo poi l'approssimazione lineare
- Per esempio se utilizziamo nelle immagini, avrebbe senso normalizzare pixel by pixel, e non image wide con un unico valore, è una assunzione, che se funziona dovrebbe poi far andare meglio la regressione logistica!
- è una distribuzione bernoulliana.
Ci chiediamo come è fatto ?
Caratterizzazione di P(Y|X)
Proviamo a calcolare analiticamente come è fatto usando le assunzioni di sopra
Theorem Assunte le cose di sopra si avrà che
 Nella derivazione di sopra si ha che
Nella derivazione di sopra si ha che
E poi sappiamo che
E si può notare che poi abbiamo il risultato di sopra e diventa sensato avere la forma di Sigmoid, che esce in modo molto molto naturale
Dalla parte in blu capiamo che è una cosa lineare, perché se è maggiore di zero allora è meglio la probabilità di stare da una parte rispetto all'altra.
Funzione di Sigmoid
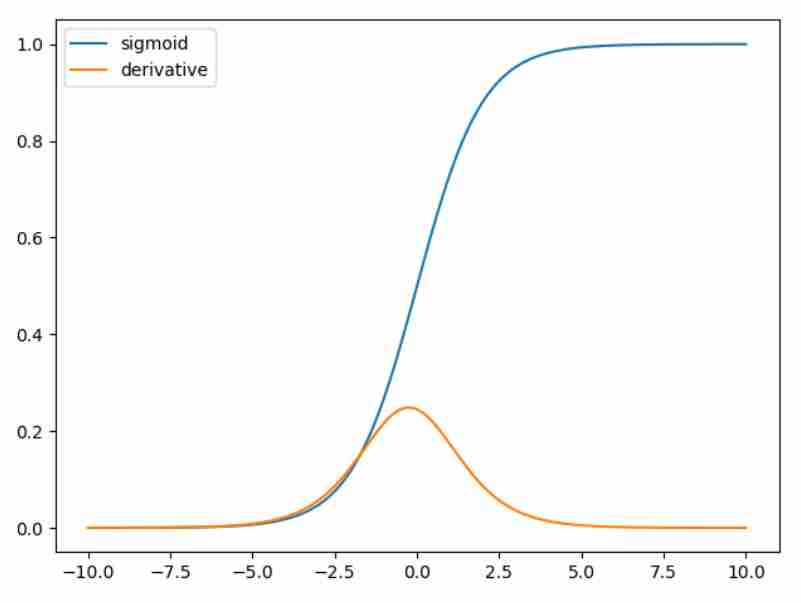 Questo ci dà una motivazione del motivo per cui utilizziamo
Questo ci dà una motivazione del motivo per cui utilizziamo
Questa funzione si può vedere come un caso particolare di Softmax Function.
Derivata Si può calcolare che ha una derivata molto molto carina, ma è anche il problema per cui esiste vanishing gradient.
Quindi diventa vero che
Possiamo scrivere la probabilità di ogni singolo campione come in figura sotto
Funzione di loss
 Che sembra una cross-entropy classica, che però non ha una soluzione analitica, per questo motivo si utilizza discesa del gradiente.
Che sembra una cross-entropy classica, che però non ha una soluzione analitica, per questo motivo si utilizza discesa del gradiente.
Ottimizzazione discesa del gradiente
Intuizione sul gradiente
abbiamo alla fine che il gradiente è
Perché già sta misurando in un certo senso la differenza (l'errore), e il prodotto lo sta legando all'input preciso, quindi è molto bello quando la formula è interpretabile in modo fisico quasi.
Sometimes is clearer to write in an explicit fashion:
Calcolo del gradiente cross entropy
Dalla formula di sopra riscritta in altro modo.
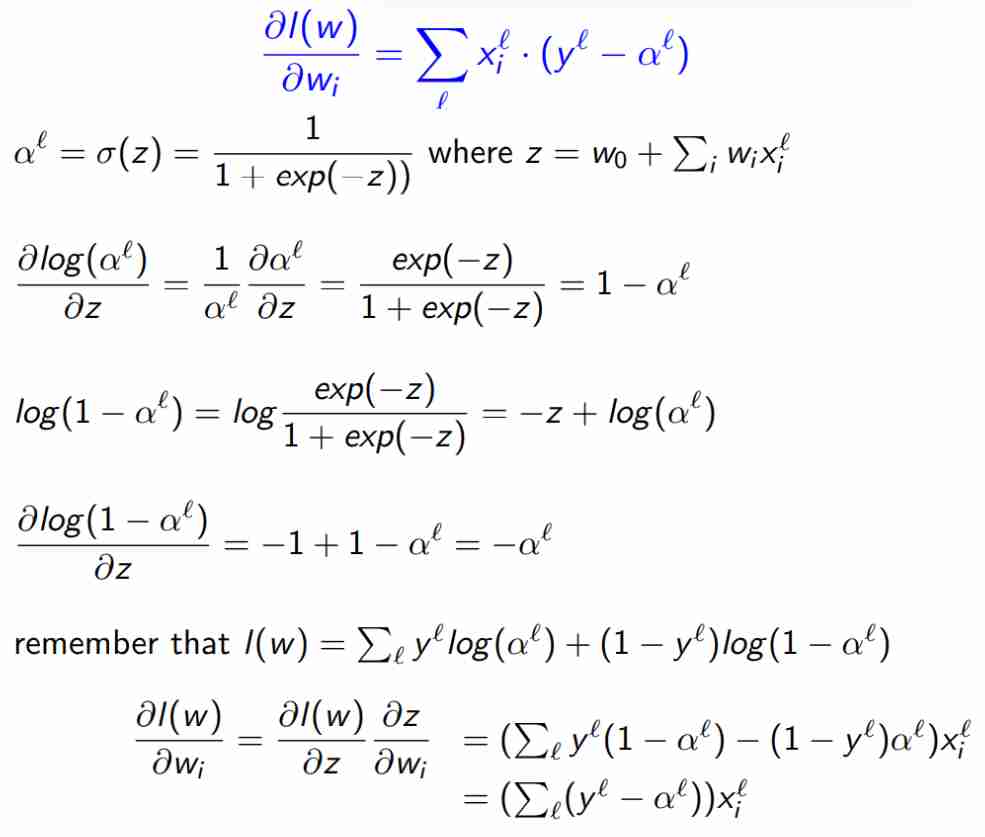 Questo è esattamente poi quanto sarà fatto durante il percettrone, per l'aggiornamento delle variabili in quelle istanze.
Questo è esattamente poi quanto sarà fatto durante il percettrone, per l'aggiornamento delle variabili in quelle istanze.
Fase update del gradiente
Una volta calcolato che il valore di update è analiticamente uguale a
Possiamo usare questa per aggiornare il peso di
Update step:
A volte viene aggiunto un fattore di regolarizzazione che fa diventare la regola di update come
Che implica il fatto che se abbiamo un singolo peso grande, farà molta fatica ad esserci nel regolarizzatore (quindi ho meno varianza fra i pesi diciamo).