In this note we will first talk about briefly some of the main differences of the three main approaches regarding statistics: the bayesian, the frequentist and the statistical learning methods and then present the concept of the estimator, compare how the approaches differ from method to method, we will explain maximum likelihood estimator and the Rao Cramer Bound.
Short introduction to the statistical methods
Bayesian
With bayesian methods we often assume a prior on the parameters, often human picked, that allows to give a regularizer term over the possible distribution that we are trying to model. The prior is just an assumption on the distribution of the model $p(\theta)$ and the likelihood $P(X \mid \theta)$, where $X$ are the features, and $\theta$ the model. After we have these two distributions defined, we can then use the famous Bayes rule to compute the posterior, and chose the best possible model given our dataset in this manner. This induces a distribution over possible $\theta$ that we can consider. Another characteristic is that the Bayes’ rule is often infeasible to compute practically. So what we compute is
$$ p(\theta \mid X) = \frac{1}{z}p(X \mid \theta) p(\theta) $$The quantity $P(X \mid \theta)$ could be very complicated if our model is complicated.
Frequentist
Fisher founded this view of statistics. Frequentist methods start by having assumptions on the space of the model parameters (this is the $\mathcal{C}$ class), so we have a family of models $\mathcal{H} = \left\{ p_{\theta} : \theta \in \mathcal{C} \right\}$, but now this assumption is not a belief on the data itself, instead, a restriction that you have to pose in order to limit your search space (the need arises from practical purposes, not from beliefs, we want the most general possible models). But then, instead of using the Bayes’ rule, they just try to maximize the possibility that a certain $\theta$ has given rise to that data. In formulas we have:
$$ \hat{\theta}_{ML} = \arg \max_{\theta} \log p_{\theta}(x_{1}, \dots, x_{n}) $$We assume the data is i.i.d so we need to estimate this value:
$$ \hat{\theta}_{ML} = \arg \max_{\theta} \log \sum_{i = 1}^{n} p_{\theta}(x_{i}) $$This is how maximum likelihood estimators naturally arise with the frequentist approach. This is asymptotically true.
Usually with enough data and big models, frequentist’s methods are preferred.
Statistical learning
The last possible interpretation, the statistical learning approach, I think is due to (Vapnik 2006)’s studies on Statistical learning theory, asserts that the best method is the one that minimizes the risk, meaning it should have the least error on the test split of our dataset. This risk is not accessible so we need to minimize the empirical risk So we try to chose the $\theta$ is this way:
$$ \hat{\theta}_{SL} = \arg \min_{\theta} \mathcal{R}(f) = \arg \min_{\theta} \mathbb{E}_{X, Y} \mathcal{L} (f(X), Y) $$So we choose an approximation for the risk which is
$$ \hat{R}(f) = \frac{1}{n} \sum_{i = 1}^{n} \mathcal{L}(f(x_{i}), y_{i}) $$And then choose the best $f$ from his family of functions
Three problems in statistical learning
The goal of statistical learning is to find a function $f : \mathcal{X} \to \mathcal{Y}$ such that the error rate is minimized. We define the error rate to be just the cases where $f(x) \neq y$. Let’s have so a simple model:
$$ \lim_{ n \to \infty } \frac{1}{n} \sum_{i= 1}^{N}\mathbb{1} \left\{ f(x_{i}) \neq y_{i} \right\} = \mathbb{E}_{\mathcal{x}, \mathcal{y} \sim p^{*}} [\mathbb{1} \left\{ f(x) \neq y \right\} ] $$So we want to minimize the following value:
$$ \min_{f}\mathbb{E}_{\mathcal{x}, \mathcal{y} \sim p^{*}} [\mathbb{1} \left\{ f(x) \neq y \right\} ] $$- We don’t know anything about $f$, we need to have some assumptions, the easiest is to define a hypothesis class.
- We don’t know the starting distribution $p^{*}$, we solve this by collecting training samples so that we have an estimate of the starting distribution. (This is the fundamental problem in machine learning, we have empirical distribution, never the true distribution!)
- The risk $\mathcal{R}$ is not differentiable, we solve this by choosing a loss function $\mathcal{L} : \mathcal{Y} \times \mathcal{Y} \to \mathbb{R}$ such that this is differentiable. We can write the starting problem in the following way as a proxy for the expected value. $$ \min_{f \in \mathcal{H}} \frac{1}{n} \sum_{i \leq n} \mathcal{L} (f(x_{i}), y_{i}) $$
This image summarizes the whole pipeline
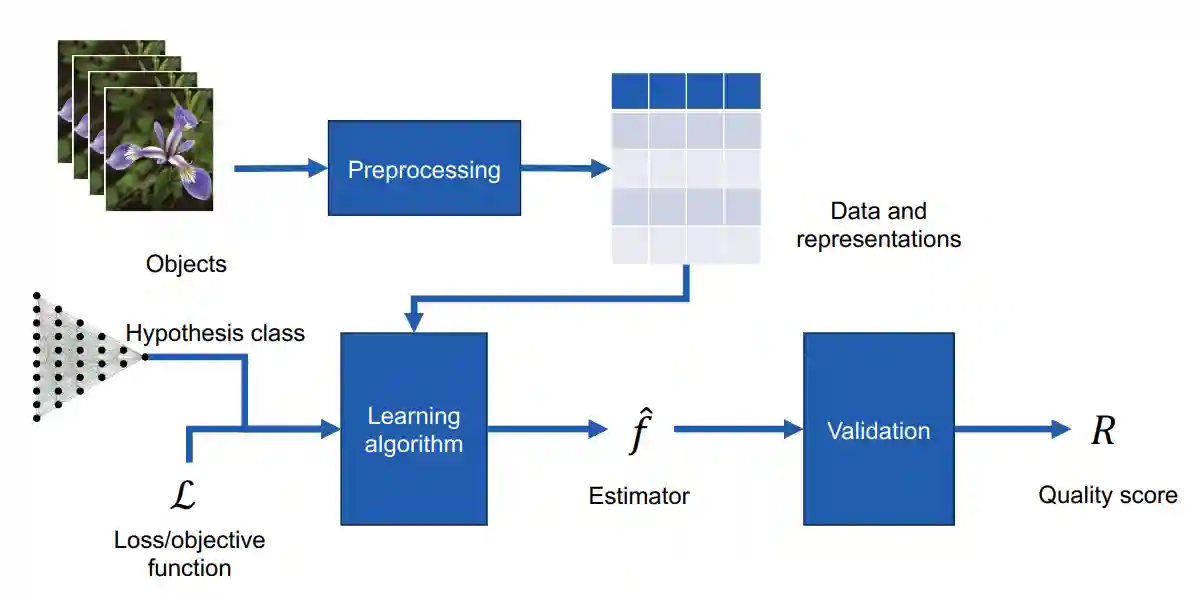
Let’s have a simple example. Let’s attempt to chose the hypothesis class for the iris setosa classification problem. We arbitrarily choose $X$ and $Y$ to be
- $Y \sim Bern(0.5)$
- $X\mid Y \sim \mathcal{N(\mu_{y}, \Sigma)}$
Then we can use Bayes rule to find $P(Y=y \mid X = x) \propto P(X = x \mid Y = y) P(Y = y)$ and we can define then a simple loss, for example the classical binary cross entropy loss.
Bayesian and Frequentist head to head

Estimators
Estimators are functions or procedures that in this context of parametric models allow us to pin-point the correct parameters $\theta$, in the case of the frequentist view, or give a distribution over possible $\theta$s. Usually the generating function is called a density function parameterised by the $\theta$ so we have to define the class of models and likelihood first.
We will mainly focus in this setting with the Maximum likelihood estimator
The Maximum Likelihood Estimator
Given an assumption on the likelihood, we define the Maximum likelihood function to be
$$ \mathcal{L}(\theta) = \prod_{i=1}^{n} f(X^{(i)} ; \theta) $$Definition of MLE 🟩
We define the Maximum Likelihood Estimator (MLE) to be simply the best maximum likelihood
$$ \hat{\theta}_{ML} = \arg \max_{\theta} \mathcal{L}(\theta) $$Sometimes is useful to consider the log-likelihood because sums are usually easier to handle. We will indicate the log version with $\ell(\theta)$.
Properties of the MLE 🟨–
The important thing here is to be able to name the properties, not prove them. You can see a good presentation of these properties with (Wasserman 2004) chapter 9 (page 127 onwards). Three main properties concern us:
- Consistency: (meaning it will converge to the true parameter, if modelling assumptions are correct e.g. function family)
- In formula it means that a point estimator $\hat{\theta}_{n}$ of a $\theta$ is consistent if it converges in probability which is: $$ \forall \varepsilon > 0, \mathbb{P}(\lvert \hat{\theta}_{n} - \theta \rvert > \varepsilon) \to_{n \to \infty} 0 $$
- See Central Limit Theorem and Law of Large Numbers for definition of convergence in probability, the proof is not trivial and has many technicalities.
- Asymptotic efficiency: For well-behaved estimators, the MLE has the smallest variance for large $n$. - For example the median estimator satisfies $\sqrt{ n } (\theta_{\text{ median}} - \theta_{*}) = \mathcal{N}\left( 0, \sigma^{2} \frac{\pi}{2} \right)$, but the MLE doesn’t have that $\pi$ factor.
- Asymptotically normal: meaning the error will be Gaussian if we have too many samples. Which means that
$$
\frac{\hat{\theta} - \theta_{*}}{\text{standard error}} \sim \mathcal{N}(0, 1)
$$
- Informally, this theorem states that the distribution of the parameters $\theta$ that we find with MLE follows a normal distribution $\mathcal{N}(\theta_{*}, se)$. This theorem holds also for estimated standard errors. The interesting thing is that with this method we can build asymptotic confidence intervals for MLE, which can come quite handy in many occasions, and rival the bayesian approach for confidence intervals.
- The proof is quite hard, it is presented in the appendix of Chapter 9 of (Wasserman 2004).
- Equivariance meaning: if $\hat{\theta}$ is MLE of $\theta$ then for any given $g$ we have that $g(\hat{\theta})$ is the MLE of $\theta$. I don’t know what is this useful for, but nice to know.
We will discuss these properties one by one. These properties are the reason why MLE is preferred over other estimators, such as means or medians.
We want to say that an estimator is efficient if it uses its information well, which means
$$ \lim_{ n \to \infty } \mathbb{E} \left[ (\hat{\theta}_{ML} - \theta_{0})^{2} \right] = \frac{1}{I_{n}(\theta_{0})} $$Where $I_{n}$ is the fisher information. Every estimator is lower bounded by this. (this is the maximum efficiency) and it’s very important.
Biases usually are good if it includes information that is correct with the data. (helps it learn faster, an example of why bias works is the Stein estimator, but I didn’t understood exactly why). Simple cases and reasoning for first principles usually helps you build the intuition to attack more complex cases. This is something you would need to keep in mind.
MLE is overconfident 🟥
TODO: see Sur and Candes 2018
One can show that there are many examples where logistic regression (see Linear Regression methods) is quite biased. This is a problem especially with high dimensional data. There are some numerical instabilities with correlated features, especially when we are trying to invert something small (floating point imprecisions!)
You can see it quite easily: Remember that the ordinary least squares solution is $(X^{T}X)^{-1}X^{T}y$, let’s suppose we use Singular Value Decomposition and write $X = V^{T}DU$ then we have $X^{T}X = U^{T}DVV^{T}DU = U^{T}D^{2}U$ Inverting this we get $U^{T}D^{-2}U$ and multiplying with the original one we get $\beta = U^{T}D^{-1}Vy$ but the matrix $D^{-1}$ is quite unstable, especially when you are inverting small numbers.
One nice thing about this decomposition is that the inference is just $X\beta = V^{T}Vy$ and that is a nice form.
Rao-Cramer Bound 🟩
Professor says this bound has same principle with the Heisenberg’s uncertainty principle with the Cauchy-Schwarz inequality somehow. But I don’t know about that.
Let’s consider a likelihood $p(y \mid \theta)$, for $\theta \in \Theta$ which is our parameter space, and some samples $y_{1}, \dots, y_{n} \sim p(y \mid \theta_{0})$, using a particular $\theta_{0}$. We want to know how precisely can we estimate the value $\theta_{0}$ given $n$ samples. So let’s define an estimator $\hat{\theta}$ and consider the expected deviation $\mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \theta_{0})^{2} \right]$, which tells us how much can the estimated value $\hat{\theta}$ vary compared to the ground truth. We consider the value of a score to be (use the log because perhaps the $p$ could be large, and we try to see how much it varies when varying the parameters, we are interested in this value because you know, Massimi minimi multi-variabile, if it’s 0 it should have some nice properties regarding maximum value of our likelihood).
$$ \Lambda := \frac{ \partial }{ \partial \theta } \log p(y \mid \theta) = \frac{\left( \frac{ \partial }{ \partial \theta } p(y \mid \theta) \right)}{p(y \mid \theta)} $$Let’s define the bias to be
$$ b_{\hat{\theta}} = \mathbb{E}_{y \mid \theta} [ \hat{\theta} (y_{1}, \dots, y_{n})] - \theta $$Now let’s consider the value of the expected score:
$$ \mathbf{E}_{y \mid \theta} \Lambda = \int p(y \mid \theta) \cdot \frac{1}{p(y \mid \theta)} \frac{ \partial }{ \partial \theta } p(y \mid \theta) \, dy = \int \frac{ \partial }{ \partial \theta } p(y \mid \theta) \, dy = \frac{ \partial }{ \partial \theta } 1 = 0 $$which is an interesting result.
Let’s consider another value:
$$ \mathbf{E}_{y \mid \theta} \left[ \Lambda \cdot \hat{\theta} \right] = \frac{ \partial }{ \partial \theta } \int p(y \mid \theta) \hat{\theta} \, dy = \frac{ \partial }{ \partial \theta } \mathbf{E}_{y \mid \theta} \left[ \hat{\theta} \right] = \frac{ \partial }{ \partial \theta } \left( \mathbf{E}_{y \mid \theta} \left[ \hat{\theta} \right] - \theta \right) + 1 = \frac{ \partial }{ \partial \theta } b_{\hat{\theta}} + 1 $$And the first part is surprisingly the bias of our estimator, so we want to see how much we can lower the bias value when we want to assess these kinds of problems.
We now consider the cross correlation between $\Lambda$ and $\hat{\theta}$
$$
\mathbf{E}_{y \mid \theta} \left[ ( \Lambda - \mathbf{E} \Lambda)( \hat{\theta} - \mathbf{E} \hat{\theta}) \right]
= \mathbf{E}_{y \mid \theta}\left[ \Lambda \cdot \hat{\theta} \right] - \mathbf{E}_{y \mid \theta} \left[ \Lambda \mathbf{E} \hat{\theta} \right]
= \mathbb{E}_{y \mid \theta} \left[ \Lambda \cdot \hat{\theta} \right]
$$
We now use Cauchy-Schwarz Inequality to observe that
$$
\mathbb{E}_{y \mid \theta} \left[ \Lambda \cdot \hat{\theta} \right] ^{2} =
\left( \mathbf{E}_{y \mid \theta} \left[ ( \Lambda)( \hat{\theta} - \mathbf{E} \hat{\theta}) \right] \right)^{2} \leq \mathbf{E}_{y \mid \theta}\left[ \Lambda^{2} \right] \mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \mathbf{E} \hat{\theta}) ^{2} \right]
$$
We now expand the second term:
$$
\mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \mathbf{E} \hat{\theta}) ^{2} \right]
\mathbf{E}{y \mid \theta} \left[ (\hat{\theta} - \theta)^{2} \right] - 2 \mathbf{E}{y \mid \theta} \left[ (\hat{\theta} - \theta) (\mathbf{E} \hat{\theta} - \theta) \right] + \mathbf{E}_{ y \mid \theta} \left[ (\mathbf{E} \hat{\theta} - \theta)^{2} \right]
\mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \theta)^{2} \right] - (\mathbf{E} \hat{\theta} - \theta) $$ Which is just $= \mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \theta)^{2} \right] - b_{\hat{\theta}}$ Putting everything together we have that
$$ \mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \theta)^{2} \right] \geq
\frac{\mathbb{E}{y \mid \theta} \left[ \Lambda \cdot \hat{\theta} \right] ^{2}}{\mathbf{E}{y \mid \theta}\left[ \Lambda^{2} \right] } + b^{2}_{\hat{\theta}}
\frac{\left( \frac{ \partial }{ \partial \theta } b_{\hat{\theta}} + 1 \right)^{2}}{\mathbf{E}{y \mid \theta}\left[ \Lambda^{2} \right] } + b^{2}{\hat{\theta}} $$
If we have an unbiased estimator, which means that $b_{\hat{\theta}} = 0$ then we have that the expected difference of the models is always greater than the expected value of the double power of the score, also known as the fisher information in maths:
$$ \mathbf{E}_{y \mid \theta} \left[ (\hat{\theta} - \theta)^{2} \right] \geq \frac{1}{\mathbf{E}_{y \mid \theta} \left[ \Lambda^{2} \right] } = \frac{1}{I_{n}(\theta_{0})} $$If instead we have a biased estimator, sometimes is advantageous because the numerator could actually be smaller.
Fisher information
Fisher information is defined as the variance of the score function. We discovered that the fisher information has something to do with the Rao-Cramer bound, let’s briefly analyze that:
$$ \mathbf{E}_{y \mid \theta} \left[ \Lambda^{2} \right] = \int p(y \mid \theta) \left( \frac{ \partial }{ \partial \theta } \log p(y \mid \theta) \right)^{2} \, dy =: I^{(1)}(\theta) $$Where $I(\theta)$ is the fisher information. We can also define the Fisher information as the Variance of the score function i.e. :
$$ I(\theta) = Var(\Lambda) = \mathbb{E}_{y \mid \theta}[(\Lambda - \mathbb{E}_{y \mid \theta}[\Lambda])^{2}] $$And simplifying, as we know that the mean of the score function is 0.
Fisher information could also be written as the derivative with respect of theta of the score function, if $\log p(y \mid \theta)$ is twice differentiable. See wikipedia.
The Multi-variable case
Let’s consider this
$$ I^{(n)} (\theta) = \int p(y_{1}\dots y_{n} \mid \theta) \left( \frac{ \partial }{ \partial \theta } \log p(y_{1} \dots y_{n}) \right)^{2} \, dy_{1}\dots dy_{n} $$And assuming we have independent variables we can see with some tricks and reasoning about the mean that:
$$ \int p(y_{1}\dots y_{n} \mid \theta) \left( \frac{ \partial }{ \partial \theta } \log p(y_{1} \dots y_{n}) \right)^{2} \, dy_{1}\dots dy_{n} = \int p(y_{1}\dots y_{n} \mid \theta) \left( \sum \Lambda_{i}^{2} \right) \, dy_{1}\dots dy_{n} = n I^{(1)}(\theta) $$Which is a nice property of the fisher information
Stein estimator
If we use this estimator we have that it is consistently better than the MLE, but we can’t prove that this is the best ever possible. We have to assume we have a multivariate random variable with $\mathbb{R}^{d}$ with $d \geq 3$ the exact details are not important, but we want to say that MLE is not always the best, this is the surprising fact.
$$ \hat{\theta}_{JS} := \left( 1 - \frac{(d - 2)\sigma^{2}}{\lVert y \rVert ^{2}} \right) y $$We then have that
$$ \mathbb{E}\left[ (\hat{\theta}_{JS}- \theta_{0})^{2} \right] \leq \mathbb{E}\left[ (\hat{\theta}_{MLE}- \theta_{0})^{2} \right] $$References
[1] Vapnik “Estimation of Dependences Based on Empirical Data” Springer 2006
[2] Wasserman “All of Statistics: A Concise Course in Statistical Inference” Springer Science & Business Media 2004