Algorithms for Sparse Matrix-Vector Multiplication
Compressed Sparse Row
This is an optimized way to store rows for sparse matrices:
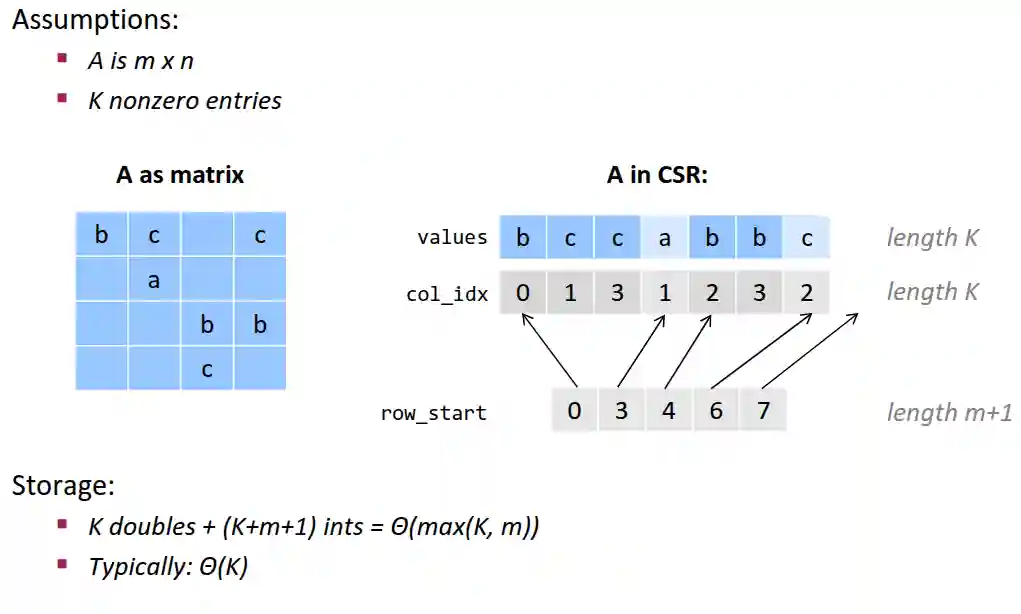
Sparse MVM using CSR
void smvm(int m, const double* values, const int* col_idx,
const int* row_start, double* x, double* y) {
int i, j;
double d;
/* Loop over m rows */
for (i = 0; i < m; i++) {
d = y[i]; /* Scalar replacement since reused */
/* Loop over non-zero elements in row i */
for (j = row_start[i]; j < row_start[i + 1]; j++) {
d += values[j] * x[col_idx[j]];
}
y[i] = d;
}
}
Let's analyze this code:
- Spatial locality: with respect to
row_start,col_idxandvalueswe have spatial locality. - Temporal locality: with respect to
ywe have temporal locality. (Poor temporal with respect to ) - Good storage efficiency for the sparse matrix.
- But it is 2x slower than the dense matrix multiplication when the matrix is dense.
Block CSR
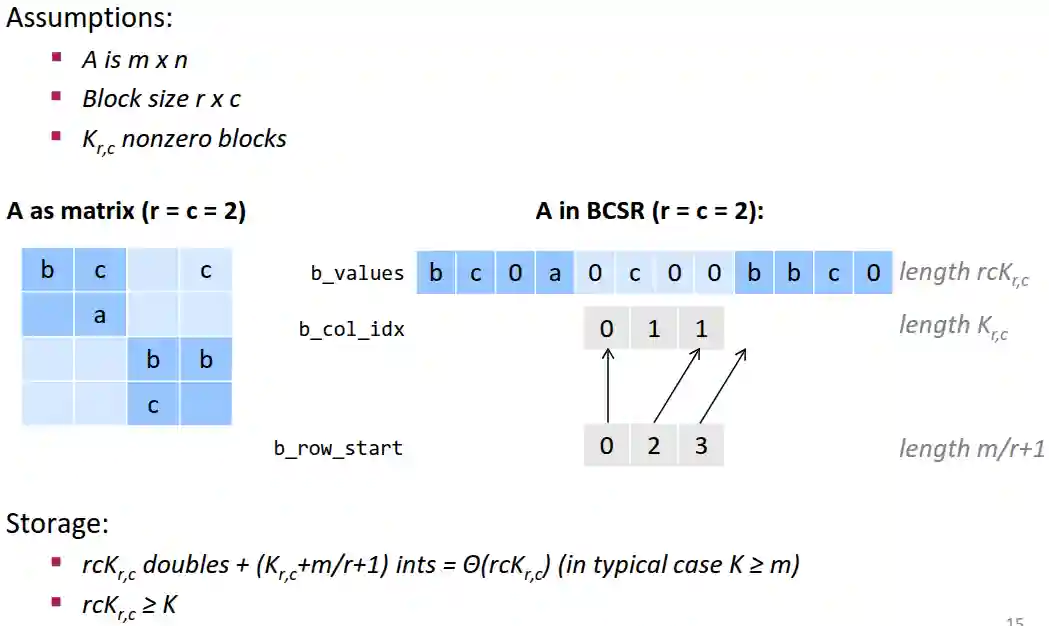
But we cannot do block optimizations for the cache with this storage method.
Blocked Sparse MVM
void smvm_2x2(int bm, const int *b_row_start, const int *b_col_idx,
const double *b_values, double *x, double *y) {
int i, j;
double d0, d1, c0, c1;
/* Loop over bm block rows */
for (i = 0; i < bm; i++) {
d0 = y[2 * i]; /* Scalar replacement since reused */
d1 = y[2 * i + 1];
/* Dense micro MVM */
for (j = b_row_start[i]; j < b_row_start[i + 1]; j++, b_values += 2 * 2) {
c0 = x[2 * b_col_idx[j] + 0]; /* Scalar replacement since reused */
c1 = x[2 * b_col_idx[j] + 1];
d0 += b_values[0] * c0;
d1 += b_values[2] * c0;
d0 += b_values[1] * c1;
d1 += b_values[3] * c1;
}
y[2 * i] = d0;
y[2 * i + 1] = d1;
}
}
- Temporal locality both with respect to
yandx - Lower storage for indexes, but higher for the data.
- Computational overhead due to the zeros.
They discovered that the performance was quite machine dependent, they couldn't se clearly a pattern in the beginning. Then if you wanted to use autotuning using matrix multiplication, then you would have just too many choices (r, c, variables are too much from 1 to 12). The conversion from CSR to blocked CSR is not trivial, the authors estimated it to cost about 10 Single Matrix Vector Multiplications, so the total cost of the search would be 1440 single matrix vector multiplications, which is just too much. See Fast Linear Algebra for ATLAS model.
Simple model
They created a simple model to compare the performance of the blocked sparse MVM with the standard sparse MVM. They got the perfromances for a dense matrix: that was speed up, divided by the computational overhead (slowdown, due to the zeros). This model has been proven to work quite well.
Compression methods for MVM
It is memory bound, so if you find nice compression ways, you can get higher performance!
Value Compression
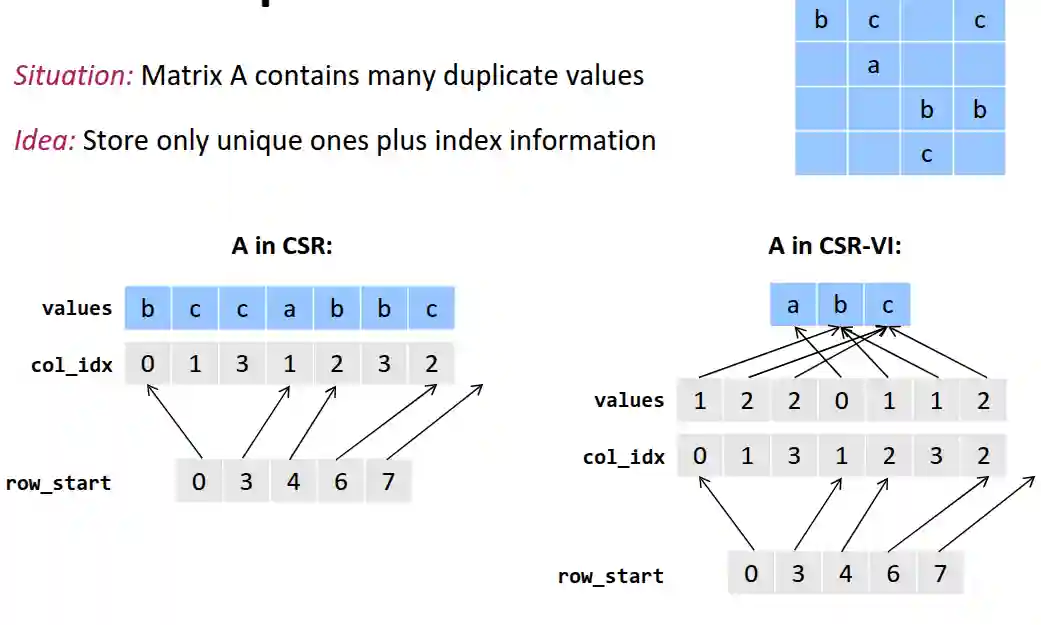
Index Compression
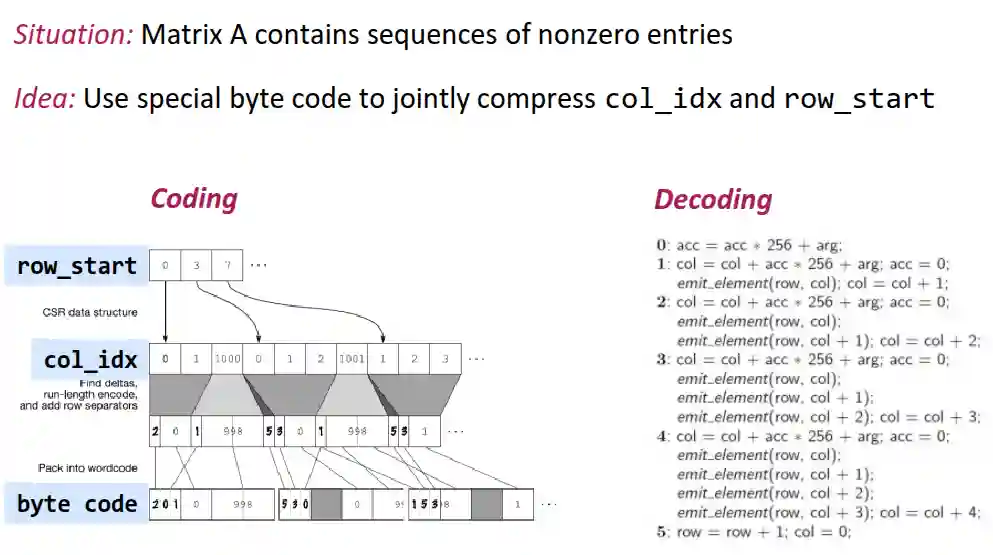
Pattern-based compression

Minuet
This is one algorithm that is used for sparse matrix convolutions, original solutions use hash tables, but these are not very much cache efficient. Cache Optimization is one note that you can see. They tried many different hash functions, but it's different to design one that has high locality, while keeping the hash properties. See (Yang et al. 2023).
Sorted queries make it more memory friendly, which has nice improvements even if computationally is more expensive. In Binary Search lookup you have smaller blocks that have nicer locality, and use binary search in one of the blocks. This is one example of explicitly designed blocks that help make things faster (computationally cheaper and memory friendly). This was 19.2x times faster in GPU tables.
They are able to reconfigure the computation in order to make it and efficient for data movement. It is also possible to use SRAM, the same idea that was present in (Dao et al. 2022).
They get 2.2x maximum in object detection at the end.
References
[1] Yang et al. “Minuet: Accelerating 3D Sparse Convolutions on GPUs” arXiv preprint arXiv:2401.06145 2023
[2] Dao et al. “FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-awareness” Curran Associates Inc. 2022