This is the generalization of the family of function where Softmax Function belongs. Many many functions are part of this family, most of the distributions that are used in science are part of the exponential family, e.g. beta, Gaussian, Bernoulli, Categorical distribution, Gamma, Beta, Poisson, are all part of the exponential family. The useful thing is the generalization power of this set of functions: if you prove something about this family, you prove it for every distribution that is part of this family. This family of functions is also closely linked too Generalized Linear Models (GLMs).
The definition
$$ p(x \mid \vec{\theta}) = \frac{1}{Z(\vec{\theta}) } \vec{h}(x) \exp(\vec{\theta} \cdot \phi (x)) $$Where $h$ defines the support, $\theta$ are the canonical parameters and $\phi$ is the sufficient statistics. $Z$ is called the partition function. $h$ is called the support. If a function can be written in this form then we have a member of this family. Note that if we set $h$, $\phi$ and $Z$ and let the parameter $\theta$ vary this is a single family (or set). And one can prove this.
Interesting properties
- Finite sufficient statistics (we can compress into a finite vector without loss of information) but I did not understand this very well)
- Conjugate priors (I didn’t understood this very well). We say that a prior distribution (i.e. $p(\theta)$) is conjugate to some likelihood function ($p(x\mid \theta)$) if the posterior distribution $p(\theta \mid x)$ (which results from this likelihood function and prior distribution) is the same distribution as the prior distribution (with updated parameters). This is often useful for bayesian inference, we used this in Bayesian Linear Regression for example.
- Corresponds to maximum entropy distributions (don’t know why).
Sufficient statistics
We have briefly mentioned what is a sufficient statistic above, in this section we will formally describe what that is
Definition of sufficient statistic
$$ p(X \mid T(X), \theta) = p(X \mid T(X)) $$Who is part of this family?
Bernoulli is part of this family
We can write the Bernoulli distribution as $p(y \mid \theta) = \theta^{y}(1 - \theta)^{1 - y}$ where $\theta \in [0, 1]$ and $y \in \left\{ 0, 1 \right\}$. This is a standard trick, we did something very similar when analyzing the MLE in bernoulli in Naïve Bayes.
$$ \begin{array} \\ \theta^{y}(1 - \theta)^{1 - y} = \exp(y \log \theta + (1 - y) \log(1 - \theta)) \\ = \exp\left( y \log \left( \frac{\theta}{1 - \theta} \right) + \log ( 1- \theta) \right) \\ = (1- \theta) \exp\left( y \log\left( \frac{\theta}{1 - \theta} \right) \right) \end{array} $$We can observe that $Z(\theta) = \frac{1}{1 -\theta}$, $h(x) = 1$, $\phi(x) = x$ is the identity function and we use a change of parameter to say that the natural parameter is given by $\log ( \frac{\theta}{1- \theta})$ instead of $\theta$, which needs to rewrite the value of $Z$ in another way, noticing that $\mu = \log \left( \frac{\theta}{1-\theta} \right) \implies \theta = \frac{1}{1 - e^{\mu}}$.
But the important thing to notice is that Bernoulli indeed can be rewritten as a member of the exponential family, thus concluding the proof.
Gaussian is part of this family
$$ p(y \mid \mu, \sigma) = \frac{1}{\sqrt{ 2\pi } \sigma} \exp \left( -\frac{(x - \mu)^{2}}{2\sigma^{2}} \right) $$In this case the natural parameter is two-dimensional. We just need a little care handing this peculiar trait.
The above can be rewritten in the following way: $$ = \frac{1}{\sqrt{ 2\pi \sigma^{2} } \exp \frac{\mu^{2}}{2\sigma^{2}}} \cdot 1 \cdot \exp \left( \begin{bmatrix} \frac{\mu}{\sigma^{2}} & - \frac{1}{2\sigma^{2}}
\end{bmatrix} \cdot \begin{bmatrix} x \ x^{2} \end{bmatrix}
\right) $$
Then it is kinda awful to rewrite the $Z$ with respect to those parameters, but I think you can be convinced it is possible. It’s far easier to see it when we set $\sigma^{2} = 1$. That is available here see 3.1. We use this fact in proving a theorem in minimizing the Forward KL divergence for Gaussians in Variational Inference.
We can prove this also for the multivariate Gaussian:
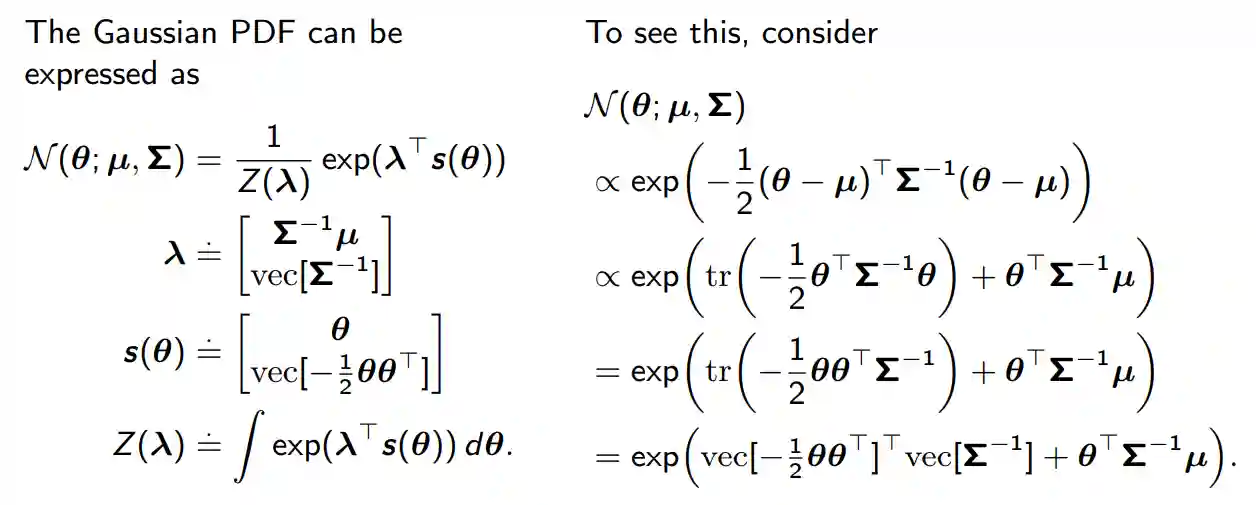 Image from here.
Image from here.
Beta is part of this family
The classical Beta distribution is
$$ p(x \mid \alpha, \beta) = \frac{x^{\alpha - 1} (1 - x)^{\beta - 1}}{B(\alpha, \beta)} $$Where $\alpha > 0, \beta > 0$ and the support of the beta in $[0 ,1 ]$. This is usually considered as the updated prior for the Bernoulli distribution after you have seen $\alpha$ successes and $\beta$ failures. A generalization for this distribution is the Dirichlet Distribution.
This is quite easy, after we rewrite the numerator in the following way: $$ x^{\alpha - 1} (1 - x)^{\beta - 1} = \exp( (\alpha - 1) \log x + \log(1 - x) (\beta - 1))
$$ Which can be rewritten in multivariable form in the following way: $$\exp \left( \begin{bmatrix} \alpha - 1 & \beta - 1 \end{bmatrix} \cdot \begin{bmatrix} \log x \ \log ( 1- x) \end{bmatrix}
\right) $$ Adding the partition function completes the expression.
Chi-square is part of this family
The chi-square distribution is as follows:
$$ p(x, k) = \frac{ x^{k / 2 - 1} \exp\left( -\frac{x}{2} \right)}{2^{k / 2} \Gamma(k / 2)} $$Where $k \in \mathbb{N}^{+}$, and the support is $(0 , \infty)$ if $k = 1$, and $[0, \infty)$ otherwise.
This is easy if we set $k / 2 - 1$ to be the canonical parameter, $\exp(- x / 2)$ is the support, the denominator is the partition function, we just need to express $x^{ k / 2 - 1} = \exp (( k / 2 - 1) \log x)$ and we have also the sufficient statistics which is $\phi(x) = \log x$.
Binomial is part of the family
$$ p(x \mid \pi) = \begin{pmatrix} n \\ x \end{pmatrix} \pi^{x} (1 - \pi)^{n - x} $$This is the classical count for the Tartaglia triangle, also known as the Pascal Triangle, in this case is just the iterated Bernoulli assuming $x$ number of successes. This is a special case of the multinomial distribution. We have $\pi \in [0, 1]$ and the support is $\left\{ 0, \dots, n \right\}$.
$$ \pi^{x} (1 - \pi)^{n - x} = \exp(x \log \pi + (n - x) \log(1 - \pi)) = \exp(n \log(1- \pi)) \cdot \exp\left( x \log \frac{\pi}{1- \pi} \right) $$And now we can clearly see that $\exp( - n \log(1- \pi))$ is our partition, $\phi(x) = x$ is our sufficient statistics, $\log \frac{\pi}{1-\pi}$ is our canonical parameter and the binomial coefficient is our support.
Uniform distribution is not in the family
$$ p(x \mid b) = \begin{cases} \frac{1}{b} & \text{ for } x \in [0, b] \\ 0 & \text{ otherwise} \end{cases} $$We want to prove that this classical distribution is not part of our family of distributions. We have $b \in (0, \infty)$ and the support is $[0, b]$.
In this case there is no way to encode into the exponential family the cases of the function. The exponential can’t just return $0$. And the support has no information about the $b$. This is not a proof, but it is reasonable.
Dirichlet is part of the family
TODO