Softmax is one of the most important functions for neural networks. It also has some interesting properties that we list here. This function is part of The Exponential Family, one can also see that the sigmoid function is a particular case of this softmax, just two variables. Sometimes this could be seen as a relaxation of the action potential inspired by neuroscience (See The Neuron for a little bit more about neurons). This is because we need differentiable, for gradient descent. The action potential is an all or nothing thing.
There are some reasons why softmax is preferred over other functions to induce a probability.
- Connections with physics
- Part of the exponential family
- Differentiability
- Satisfies the Maximum Entropy Principle This is why it is usually preferred over other ways to induce a simplex.
Definition of the function
The softmax function is usually defined as follows:
The softmax takes the vector into a simplex which is useful for categorical distributions. For this reason, often the output is not exactly correct to say we have a probability distribution (we don't often have priors), but in practice it's a useful concept.
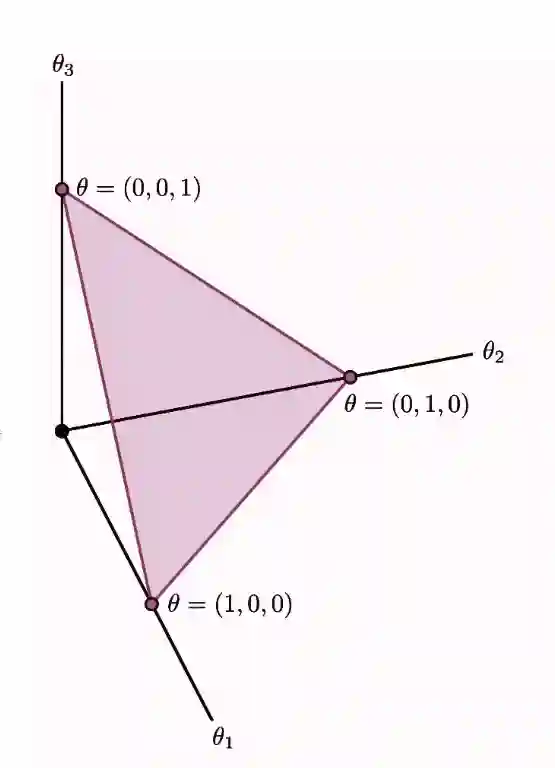
The simplex
The dimensional simplex is the region of where the sum of components is 1.
Down here we have an example of the simplex.
degrees of freedom for the simplex, because the last dimension is a linear combination of the previous ones.
The role of temperature
The parameter is a non-negative parameter that tells us how much spread our categories are. If we have the function automatically. if we have maximum entropy, so we have uniform categorical distribution.
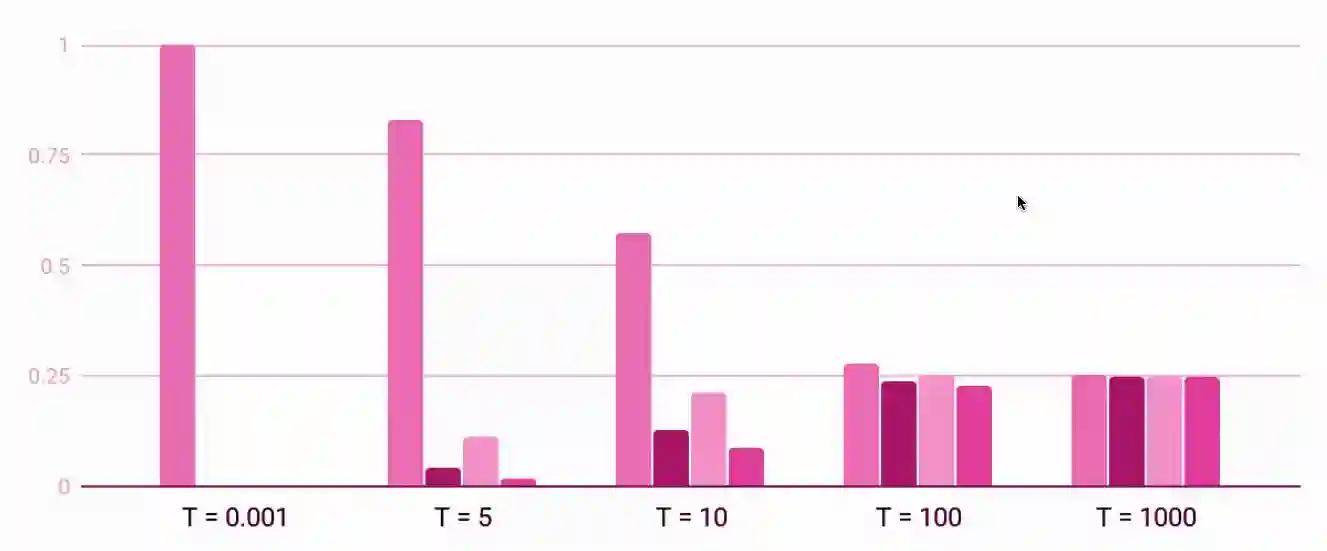 So allows us to smoothly interpolate between argmax and uniform distribution. The interesting thing is that it is a differentiable version of the max, which byitself is not differentiable.
So allows us to smoothly interpolate between argmax and uniform distribution. The interesting thing is that it is a differentiable version of the max, which byitself is not differentiable.
We have that
If we have . This is a easy giustification of why we call this softmax.
The partial derivative
We can calculate the derivative of the log softmax and we obtain:
Relationship with Maximum Entropy Principle
Related to Maximum Entropy Principle for a discussion about that principle. Here we will provide some arguments why Softmax is usually a good choice:
TODO: See here slide 98.
Sigmoid and Rates of Growth
One nice thing about the Sigmoid function is that it is a particular solution for the upper bounded rate of growth problem. One can see that solving the differential equation:
Yields a solution of the form:
Which is exactly the Sigmoid function, by modelling .
Gumbel Softmax
This is another version of softmax for categorical? See https://sassafras13.github.io/GumbelSoftmax/
This is just a stochastic version of the Softmax distribution, that allows you to do sampling given certain logits, instead of
The Gumbel distribution is:
Then adding to softmax we have: