Queste note sono molto di base. Per cose leggermente più avanzate bisogna guardare Bayesian Linear Regression, Linear Regression methods.
Introduzione alla logistic regression
Giustificazione del metodo
Questo è uno dei modelli classici, creati da Minsky qualche decennio fa In questo caso andiamo direttamente a computare il valore di $P(Y|X)$ durante l’inferenza, quindi si parla di modello discriminativo.
Introduzione al problema
Supponiamo che
- $Y$ siano variabili booleane
- $X_{i}$ siano variabili continue
- $X_{i}$ siano indipendenti uno dall’altro.
- $P(X_{i}| Y= k)$ sono modellate tramite distribuzioni gaussiane $\mathbb{N}(\mu_{ik}, \sigma_{i})$
- NOTA! la varianza non dipende dalle feature!, questo mi permetterebbe di poi togliere la cosa quadratico dopo, rendendo poi l’approssimazione lineare
- Per esempio se utilizziamo nelle immagini, avrebbe senso normalizzare pixel by pixel, e non image wide con un unico valore, è una assunzione, che se funziona dovrebbe poi far andare meglio la regressione logistica!
- $Y$ è una distribuzione bernoulliana.
Ci chiediamo come è fatto $P(Y|X)$?
Caratterizzazione di P(Y|X)
Proviamo a calcolare analiticamente come è fatto $P(Y|X)$ usando le assunzioni di sopra
$$ P(Y=1| X= \left< x_{1},\dots, x_{n} \right> ) = \frac{1}{1 + \exp\left( w_{0} + \sum_{i} w_{i}x_{i} \right)} $$ Nella derivazione di sopra si ha che $\pi = P(Y=1)$
Nella derivazione di sopra si ha che $\pi = P(Y=1)$
E poi sappiamo che
$$ \ln \frac{P(X_{i} | Y=0)}{P(X_{i} | Y=1)} = \ln \frac{e^{-\frac{(X_{i} - \mu_{i0})^{2}}{2 \sigma_{0}^{2}}}}{ e^{-\frac{(X_{i} - \mu_{i_{1}})^{2}}{2 \sigma_{1}^{2}}}} = -\frac{(X_{i} - \mu_{i0})^{2}}{2 \sigma_{i}^{2}} + \frac{(X_{i} - \mu_{i1})^{2}}{2 \sigma_{i}^{2}} $$E si può notare che poi abbiamo il risultato di sopra e diventa sensato avere la forma di Sigmoid, che esce in modo molto molto naturale
Dalla parte in blu capiamo che è una cosa lineare, perché se è maggiore di zero allora è meglio la probabilità di stare da una parte rispetto all’altra.
Funzione di Sigmoid
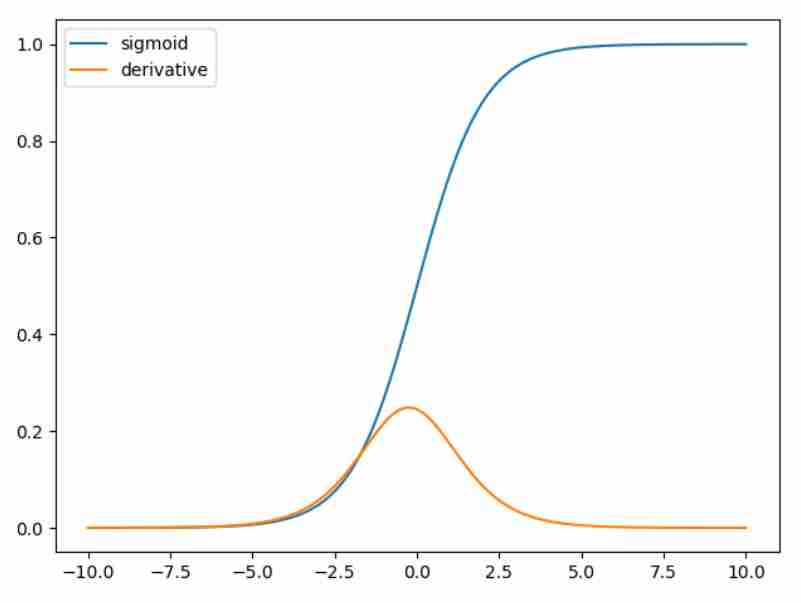 Questo ci dà una motivazione del motivo per cui utilizziamo
$$
\text{ Funzione di sigmoid: }\sigma(x) = \frac{1}{1 + e^{-x}}
$$
Questa funzione si può vedere come un caso particolare di Softmax Function.
$$
\sigma'(x) = \sigma(x) (1 - \sigma(x))
$$$$
P(Y=1|x,w) = \sigma\left( w_{0} + \sum_{i} w_{i}x_{i} \right)
$$
Questo ci dà una motivazione del motivo per cui utilizziamo
$$
\text{ Funzione di sigmoid: }\sigma(x) = \frac{1}{1 + e^{-x}}
$$
Questa funzione si può vedere come un caso particolare di Softmax Function.
$$
\sigma'(x) = \sigma(x) (1 - \sigma(x))
$$$$
P(Y=1|x,w) = \sigma\left( w_{0} + \sum_{i} w_{i}x_{i} \right)
$$Possiamo scrivere la probabilità di ogni singolo campione come in figura sotto
Funzione di loss
 Che sembra una cross-entropy classica, che però non ha una soluzione analitica, per questo motivo si utilizza **discesa del gradiente**.
Che sembra una cross-entropy classica, che però non ha una soluzione analitica, per questo motivo si utilizza **discesa del gradiente**.
Ottimizzazione discesa del gradiente
Intuizione sul gradiente
abbiamo alla fine che il gradiente è
$$ \frac{\delta \mathcal{L}(w)}{\delta w_{i}} = \sum_{l} x^{l}_{i} \cdot (y^{l} - \alpha^{l}) $$Perché già $(y - \alpha)$ sta misurando in un certo senso la differenza (l’errore), e il prodotto lo sta legando all’input preciso, quindi è molto bello quando la formula è interpretabile in modo fisico quasi.
$$ \nabla_{w} \ell(w)(x, y) = [\sigma(w \cdot x) - y]x $$Calcolo del gradiente cross entropy
$$ a^{l} = \sigma\left( w_{0} + \sum_{i} x_{i}w_{i} \right) = \sigma(z) $$$$ \sum_{l} \log P(Y= y^{l} | x ^{l}, w) = \sum_{l} y^{l}\log(\alpha^{l}) + (1- y^{l})(1 - \log(\alpha^{l})) $$Dalla formula di sopra riscritta in altro modo.
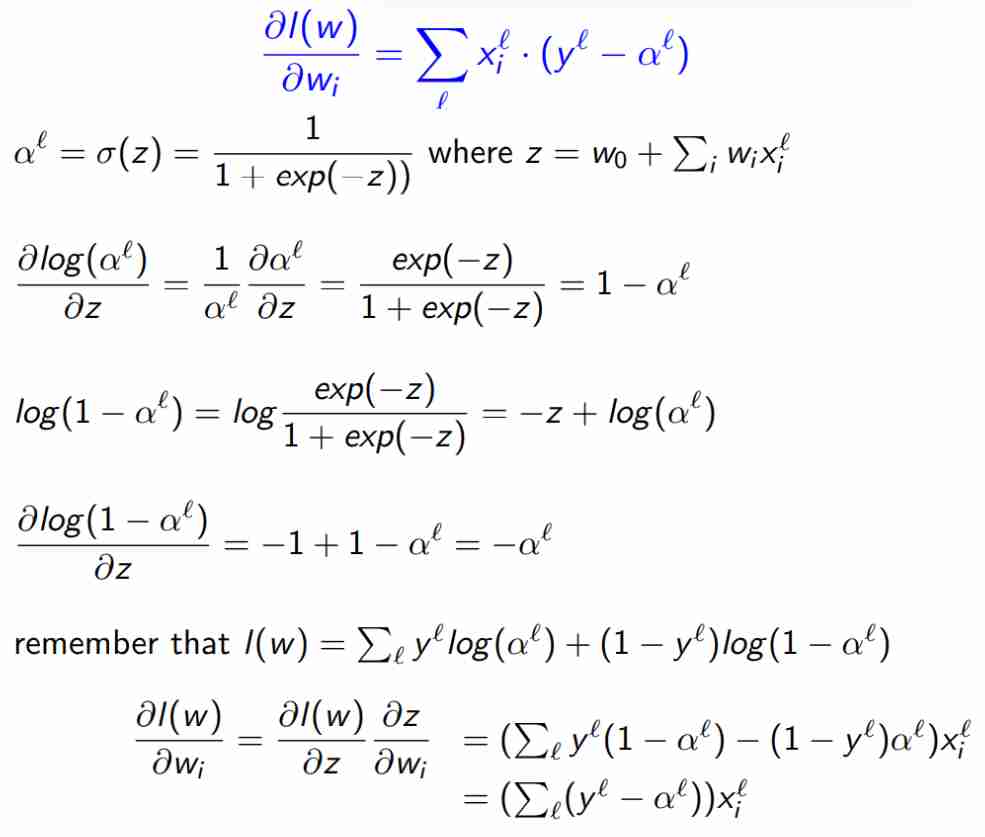 Questo è esattamente poi quanto sarà fatto durante il percettrone, per l'aggiornamento delle variabili in quelle istanze.
Questo è esattamente poi quanto sarà fatto durante il percettrone, per l'aggiornamento delle variabili in quelle istanze.
Fase update del gradiente
$$ \frac{\delta \mathcal{L}(w)}{\delta w_{i}} = \sum_{l} (y^{l} - \alpha^{l}) x^{l} $$Possiamo usare questa per aggiornare il peso di $w_{i}$
$$ w_{i} = w_{i} + \mu \frac{\delta \mathcal{L}(w)}{\delta w_{i}} $$$$ w_{i} = w_{i} + \mu \frac{\delta \mathcal{L}(w)}{\delta w_{i}} + \mu \lambda|w_{i}| $$Che implica il fatto che se abbiamo un singolo peso grande, farà molta fatica ad esserci nel regolarizzatore (quindi ho meno varianza fra i pesi diciamo).