Andiamo a parlare di processi Markoviani. Dobbiamo avere bene a mente il contenuto di Markov Chains prima di approcciare questo capitolo.
Markov property
Uno stato si può dire di godere della proprietà di Markov se, intuitivamente parlando, possiede già tutte le informazioni necessarie per predire lo stato successivo, ossia, supponiamo di avere la sequenza di stati $(S_n)_{n \in \mathbb{N}}$, allora si ha che $P(S_k | S_{k-1}) = P(S_k|S_0S_1...S_{k - 1})$, ossia lo stato attuale in $S_{k}$ dipende solamente dallo stato precedente.
Normalmente poche cose nel mondo reale si possono dire puramente Markoviane, però non si può negare che è un modello molto buono di partenza come modello di decisione.
ma potremmo sempre rendere Markoviano creando una nuova variabile che ci rappresenta tutta la storia (è qualcosa che non ho capito molto bene, ma credo si possa fare senza probbi).
Markov processes
Possiamo andare a definire un processo markoviano come un insieme di stati e il modello di transizione probabilistico: $(S, P)$, una coppia di stati e tutto il modello di transizione. mi sembra di aver letto che un processo markoviano sia molto buono per studiare i moti browniani in fisica. Praticamente a random abbiamo che ogni punto si può muovere
-
Esempio di processo markoviano
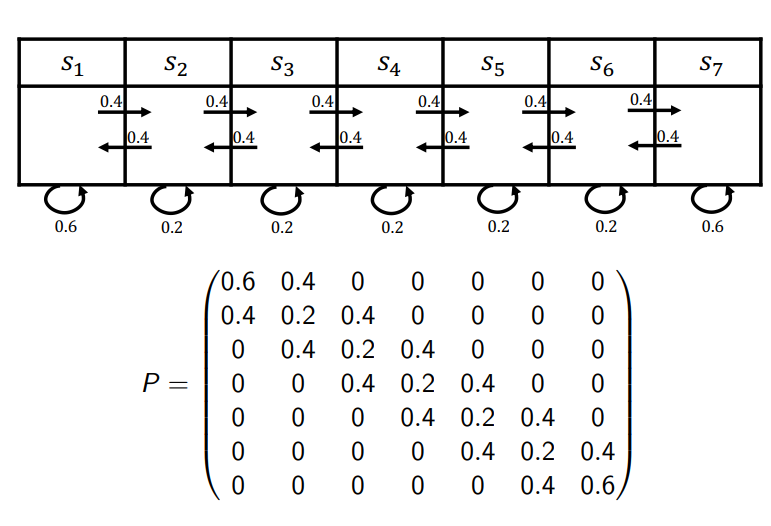
Markov Reward Processes
Quando andiamo a parlare di processo markoviano con reward indichiamo che associamo una funzione valore $V(s)$ che restituisce un certo valore a ogni stato. Di solito questo valore ci è ignoto agli agenti che seguono il modello, quindi diventa un buon problema con questa impostazione provare a stimare il valore dello stato in seguito a numerose osservazioni. Solitamente non vogliamo considerare tutti i reward con lo stesso peso. Vorremmo avere anche a disposizione un parametro che ci indichi quanto siano importanti i reward subito di ora, e i reward nel futuro. Con questo indichiamo un discount factor $\gamma$
Definition
Un tale processo viene formalizzato tramite una quadrupla $S, P, R,\gamma$, con s stati possibili, P il modello di transizione e R la funzione che ritorna il reward per ogni stato.
$(S, P, R, \gamma)$, ossia ora abbiamo sia stato, sia azione possibile e la funzione di transizione deve contare entrambi: $P(\cdot | s, a)$, mentre le reward sono ancora come prima.
- $S$ l’insieme finito o infinito numerabile di stati possibili
- $P$ probabilità di raggiungere un certo stato, dato uno stato iniziale e una azione, solitamente modellati come $P(x' \mid x)$ come arrivare a stato $x'$ da $x$. Questa è un genere di approccio Markoviano, perché dipende solamente dallo stato precedente.
- $R$ reward di uno stato. Talvolta il reward stesso di una azione in un certo stato può essere rumoroso (noisy).
- $\gamma$: decadimento del reward.
State Value Function
Solitamente viene definito state value function:
$$ V(s) = \mathbb{E}[R_t + \gamma R_{t + 1} + \gamma^2 R_{t + 2} + ... | s = s _{t}] $$La parte dentro il valore atteso è solitamente indicata con $G_t$.
Policy evaluation
Metodi di estimazione della funzione valore:
Abbiamo abbastanza metodi per stimare il valore della funzione: metodi di sampling, metodi diretti (analitici) e metodi basati su programmazione dinamica.
Riguardo i metodi di sampling questi sono i più dinamici, nel senso che permettono l’applicazione a più problemi possibili, in generale hanno una precisione che va nell’ordine dell $\dfrac{1}{\sqrt {n}}$ anche se non so su quali basi in particolare.
I metodi diretti sono leggermente più lenti, perché si tratta di risolvere l’inversa della matrice, cosa che va in $O(n^3)$. Il motivo di questo è che possiamo sfruttare la proprietà di V
Bellman expectation equation
La dimostrazione è sul libro di Krause pagina 186. La differenza qua, è che lo stiamo dimostrando per markov reward process, mentre lì è per decision process, ma è analoga la cosa. Possiamo dire che
$$ V_k(s_t) = \mathbb{E}[R_t + \gamma G_{t + 1} | s = s _{t}] = R(s) + \gamma \sum_{s'}P(s'|s)V_{k -1}(s') = (R + \gamma P V_{k - 1})(s) $$E scritto sfruttando il valore atteso abbiamo: $$ V^{\pi}{k}(x) = R(x) + \gamma \mathbb{E}{x’ \mid x, \pi(x)}[V_{k - 1}(x’)]
$$
$$ V^{\pi}_{k}(x) = \mathbb{E}_{a \sim \pi}[R(x, a) + \gamma \mathbb{E}_{x' \mid x, a}[V_{k - 1}(x')]]] $$Una nota è che questa è stazionaria quindi avremo alla fine che $V_{k} = V_{k - 1}$ se continuiamo per tanto. Questa osservazione permette di sviluppare un algoritmo iterativo per stimare il $V$ fino a convergenza (sul perché converge sicuramente guardare altro, probabilmente idea degli operatori di bellman può essere utile)
Markov Decision Process
Questo è molto simile alla Markov Reward Processes, solo che ora introduciamo una policy, ossia una funzione che ci dica quanto è probabile compiere una certa azione in un certo stato, in pratica aggiungiamo la possibilità di avere azioni ai Markov Reward Processes, allora otteniamo i MDP. Questi modelli sono utilizzati per modellare decisioni sequenziali finite.
Definition
$(S, A, P, R, \gamma)$, which means we now have both state and possible action, and the transition function must account for both: $P(\cdot | s, a)$, while the rewards are still as before.
- $S$ is the finite or countably infinite set of possible states
- $A$ is the set of possible actions
- $P$ a function $S \times A \to S$ which represents the probability of reaching a certain state, given an initial state and an action; typically modeled as $P(x' \mid x, a)$ representing how to reach state $x'$ from $x$ with action $a$. This is a kind of Markovian approach, because it depends only on the previous state.
- $R$ is the reward of a state-action pair, a function $S \times A \to \mathbb{R}$. Sometimes the reward itself of an action in a certain state can be noisy.
- $\gamma$: reward decay.
È da notare che se possediamo una policy, allora possiamo ridurci al caso di Markov Reward Process, infatti possiamo dire che
$$ \begin{align} R^\pi(s) = \sum_{a \in A}\pi(a | s)R(s) \\ P^\pi(s'|s) = \sum_{a \in A} \pi(a | s) P(s'|s, a) \end{align} $$
Notiamo che MDP assumono che lo stato sia totalmente osservabile. Ma normalmente gli stati sono solamente accessibili tramite sensori, quindi si può dire che gli stati sono parzialmente osservabili. Questo è un problema che si chiama POMDP.
L’immagine seguente riassume questi concetti brevemente:
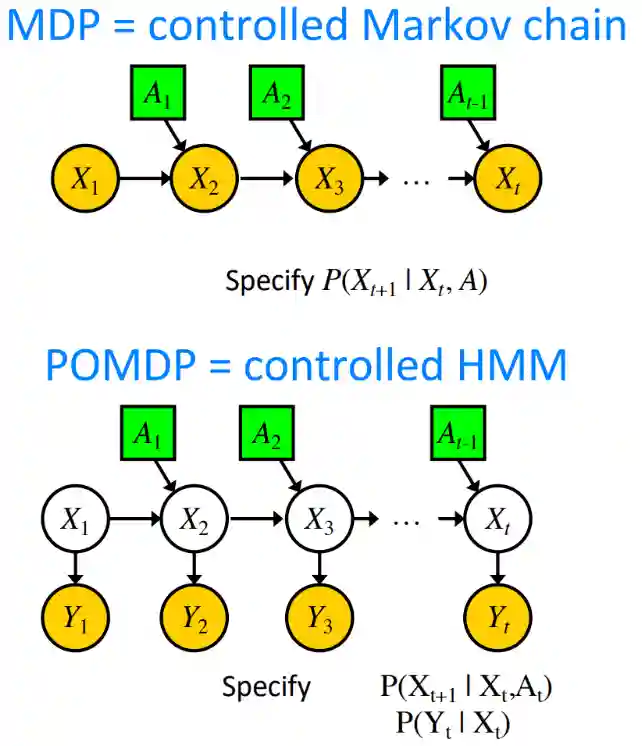
Modelling reward
$$ \max \mathbb{E} \left[ \sum_{t = 0}^{\infty} \gamma^{t}r_{t} \right] $$Si potrebbero interpretare come una sorta di Markov Chains, con labels negli edge di transizione (quindi potremmo riutilizzare la nozione di Ipergrafo fatta per Backpropagation forse) Comunque a seconda se la funzione di transizione sia deterministica, ossia da uno stato dia una azione, oppure probabilistica, possiamo definire effettivamente la Markov Chains sottostante:
$$ \begin{align} \\ P(x' \mid x) = P(x' \mid x , \pi(x)) & \text{ se deterministica} \\ P(x' \mid x) = \sum_{a \in \mathcal{A}} \pi(a \mid x)P(x' \mid x, a) & \text{ se probabilistica} \\ \end{align} $$Quindi data una policy possiamo utilizzare gli argomenti fatti di sopra e riuscire a dare una valutazione di essa
Policy Evaluation
Bellman backup
- Algoritmo iterativo DP per policy evaluation

With vector notation, we can define the bellman backup as follows:
$$ \begin{align} \\ B: \mathbb{R}^{n} \to \mathbb{R}^{n} \\ B(V)(s) = R(s) + \gamma \sum_{s'} P(s'|s)V(s') \\ \end{align} $$Bellman backup is a contraction
We can prove that bellman backup is a contraction, which is useful to prove that the iteration converges. We can use this bellman backup operator to find an iterative algorithm to estimate the value of a single state.
$$ \begin{align} \lvert BV - BV' \rvert_{\infty} & = \lvert R + \gamma PV - R - \gamma PV' \rvert_{\infty} \\ &= \gamma \lvert PV - PV' \rvert_{\infty} \\ & = \gamma \max_{y} \sum_{x} P(x \mid y) \lvert V(x) - V'(x)) \rvert \\ & \leq \gamma \cdot \max_{y}\sum_{x} P(x \mid y) \lvert V - V' \rvert_{\infty} \\ & \leq \gamma \cdot \lvert V - V' \rvert_{\infty} \\ \end{align} $$As we need to multiply the transition vector, the speed is polynomial on the number of states.
Policy Search
Cerchiamo ora la policy migliore possibile da applicare a un MDP, questo è il problema del policy control ora che sappiamo come fare policy evaluation è il momento giusto per introdurre soluzioni a questo problema.
Una soluzione naïve è semplicemente enumerare tutte le policy e utilizzare l’algoritmo di policy evaluation, poi andare a vedere quale sia la migliore. Questo è molto dispendioso perché assumendo che posso applicare tutto l’insieme di azioni a tutti gli stati ho potenzialmente $|S|^{|A|}$ policy possibili, che sono troppi.
È bene, raggiunti questo punto, provare a introdurre alcune definizioni utili.
Definitions: state-action-value, optimal value policy
Sia $\pi$ una policy e $V^\pi$ la evaluation di quella policy, allora possiamo andare a definire la state-action-value function in questo modo:
$$ Q^{\pi}(s, a) = R(s, a) + \gamma \sum_{s'} P(s'|s, a)V^\pi(s') $$ossia ci dice più o meno il valore atteso dell’azione a un certo stato!
Possiamo anche definire la policy migliore:
$$ \pi^*(s) = \arg\max_{\pi} V^\pi(s) $$Ossia è la policy che rende massimo il valore in qualunque stato!
Other Properties
Bellman’s theorem
$$ \pi^*(s) = \arg\max_a Q(s, a) $$Which means that the optimal policy is greedy with respect to the state-action value function. This is the same as the Characterization of optimal policies explained layer
$$ V^*(s) = \max_{a \sim \pi} Q^*(s, a) $$So, if the policy satisfies this condition, we can call it to be optimal. If it’s a stationary condition of the above, then the condition is satisfied.
Characterization of Optimal policies
$$ V^{*}(x) = \max_{a} \left[ Q^{*}(x, a) \right]=\max_{a} \left[ R(x, a) + \gamma \sum_{x'} P(x' \mid x, a)V^{*}(x') \right] $$This is another fixed point, an observation that we can use for another contraction operator which guarantees convergence. This is an optimality condition for deterministic policies.
Policy iteration
The algorithm
Una volta creato una policy iteration, è una cosa molto sensata andare a definire una nuova policy $\pi_{k + 1}$ definita in questo modo:
$$ \forall s, \pi_{k + 1}(s) = \arg\max_a Q(s, a) $$Ossia andiamo proprio a crearci una nuova policy, cercando di rendere maggiore possibile il valore atteso a fare una certa azione a uno stato, in modo greedy! Riusciremo a dimostrare che $\forall s, V^{\pi_{k + 1}}(s) \geq V^{\pi_{k}}(s)$
In formule, possiamo caratterizzare l’algoritmo in modo molto semplice:
- Initialize $V^{\pi}(s)$ and $\pi(s)$
- Repeat until convergence:
- Policy evaluation: $V^{\pi} \leftarrow V^{\pi}$
- Policy improvement: $\pi \leftarrow \pi$
Monotonicity of policy iteration
Si nota che una policy induce un value, che induce una policy migliore, quindi si può provare a reiterare questo algoritmo fino a convergenza.
-
Dimostrazione dal (Sutton & Barto 2018)
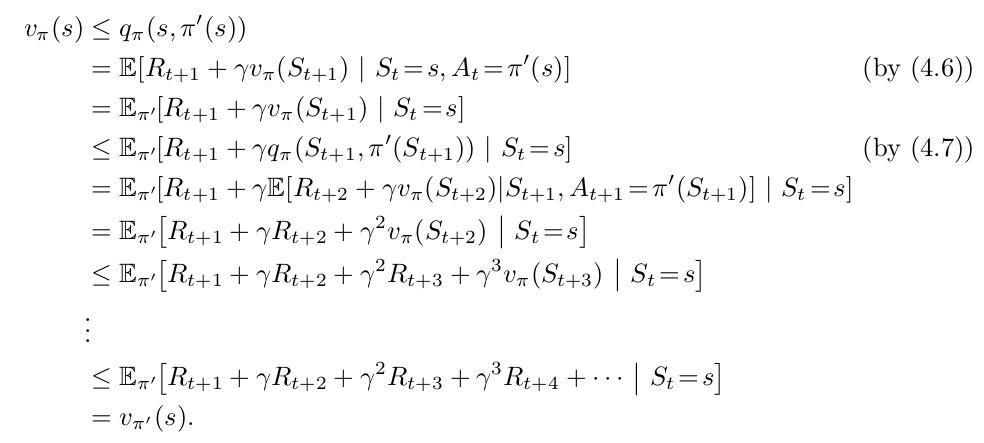
l’idea principalmente è prendere sempre il massimo volta dopo volta, e dimostrarlo per induzione in pratica… Anche non ho capito come formalizzare e non ho capito se posso trarne vantaggi didattici nella formalizzazione di questa merda
Convergence of Policy Iteration
The number of deterministic policies is finite for finite Markov decision processes (it’s easy to count them). It was shown by Ye 2011 that we need a polynomial number of iterations for it to converge. The complexity should be dependent on the number of states and actions. Note that the policy evaluation is cubic in the number of states, so the polynomial is at least cubic.
$$ \mathcal{O}\left( \frac{n^{2}m}{1 - \gamma} \right) $$Where $n$ is the number of states, $m$ are the actions.
Value Iteration
The idea
L’idea di value iteration è sostituirla subito, cioè non stare a sviluppare fino in fondo la value evaluation, ma aggiornare la policy subito dopo appena si ha il valore. Questo perché la parte di policy evaluation può essere molto molto lunga.
- Pseudo-codice value iteration

Note: the above could also be written in terms of state-action value $Q(s, a)$. One can prove that this algorithm is also $\varepsilon-$optimal.
Bellman update operator
The bellman update is defines as:
$$ \begin{align} B: \mathbb{R}^{n} \to \mathbb{R}^{n} \\ B(V)(s) = \max_{a} R(s, a) + \gamma \sum_{s'} P(s'|s, a)V(s') \end{align} $$This operator yields a value function over all states $s$ and returns a new value function. If we found a fixed point for this function, then we know that is the optimal value function that satisfies the Bellman theorem, which implies we have reached the best policy possible for this fixed case.
Si può dimostrare che questo operatore è una contrazione, quindi value iteration converge qualunque sia il punto di partenza
Con questo operatore, possiamo anche riscrivere in modo migliore la policy evaluation
- Slide

Convergence analysis
-
Proof of contraction of bellman operator
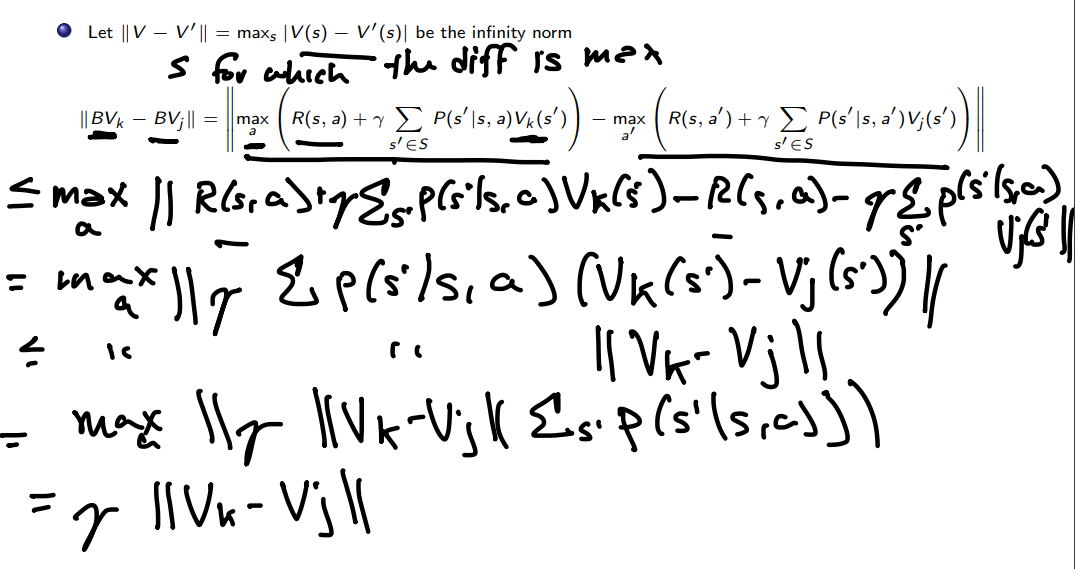
This proof is enough to use Banach Fixed Point Theorem and say there is an unique fixed point. Then we can use the fact that $\gamma < 1$ to say that it converges, in a manner akin to what we have done with policy Evaluation. Also in this case we can prove it converges in a polynomial number of iterations But differently from Policy Iteration, value iteration does not converge to the exact solution.
The only part which could be seen as not obvious is why $\lVert max(f(x)) - max(g(x)) \rVert \leq max \lVert f(x) - g(x) \rVert$ this is a simple consequence from the observation that $max(f(x) + g(x)) \leq max(f(x)) + max(g(x))$, moving a max to the other side, and setting the functions accordingly.
POMDP
POMDP stands for Partially Observable Markov Decision Process. It has some similarities with Kalman Filters, which the relaxation that we are not constrained to have Gaussian Transitions.
Definition of POMDP
A POMDP is defined as a tuple $(S, A, P, R, \Omega, O, \gamma)$, where:
- $S$ is the set of states
- $A$ is the set of actions
- $P$ is the transition probability
- $R$ is the reward function
- $\Omega$ is the set of observations
- $O$ is the observation probability, a function that given the real state returns a probability distribution over the set of observations
- $\gamma$ is the discount factor
So we have added the set of possible observations and how it links with the hidden true state.
Equivalence to MDP
TODO: should be a good exercise, these are the current hints:
- Define a belief space, and the you just need to work out the belief transitions to this new space.
- Also define the new rewards for this.
References
[1] Sutton & Barto “Reinforcement Learning: An Introduction” A Bradford Book 2018